
Overview of My Submission
Juhu is an open-source search engine that is built using Nodejs and Redis database. As you have already guessed the use case scenario of the website. Why not try on your own, Search for Elon Musk.
I was always curious to know about how search engine are built and most importantly how SEO is done. Throught the journey of building the new search engine, I have learnt a lot of things about how the data should be displayed on the website, what are the HTML tags needed to make the crawler understand what your website is all about. Also, using a pre-styled HTML elements (built for the specific purpose) are better than using a CSS to style the elements later.
Submission Category:
MEAN/MERN Mavericks Yes, I have used MERN, also replaced M with R, I mean I have used redis as a primary database
Video Explainer of My Project
Language Used:
I have used Javascript as a primary language and Nodejs as a runtime environment. I have used different libraries/packages to build this application. Some of them are:
Puppetter -> I have used this automation tool to scrape the websie
Redis OM -> Used to interact with redis services (Redis search/ JSON database)
Express -> To create server
React -> To create client side (frontend)
Mongoose -> To use secondary database (MongoDB)
Link to Code
The MERN application repository:
 aashishpanthi
/
search-engine
aashishpanthi
/
search-engine
This is an open source search engine built using redis and puppeteer
Juhu - search engine
Juhu is an open source search engine that doesn't track users and id fully customizable.


Overview video
Here's a short video that explains the project and how it uses Redis:
How it works
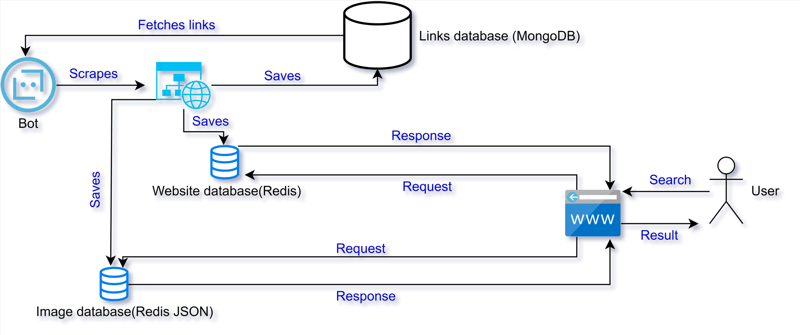
Firstly of all a bot is used to run through different websites and that bot checks if the url is allowed to crawl or not. If able to crawl, it means it is able to be indexed. So, the bot scrapes the data from that website. Filters the data and stores in a form that it will be easier to search and index the scraped data. I want to attach a little architecture diagram here to clear out the things I said:

How the data is stored:
First of all, our server needs to be connected with the redis database. This is a long code but it works :).
import…The bot repository:
Web-crawler
This is a web crawler made using puppeteer library in javascript. It visists different websites, scrapes the information and stores the information inside of a database which can be accessed by the search engine.
Architecture:
Links:
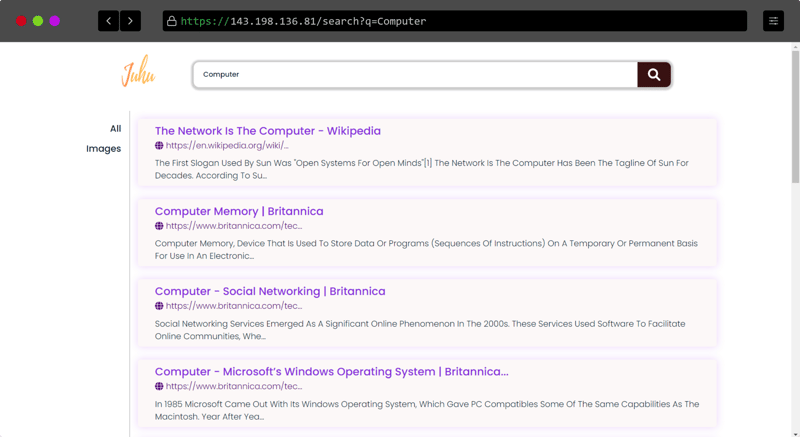
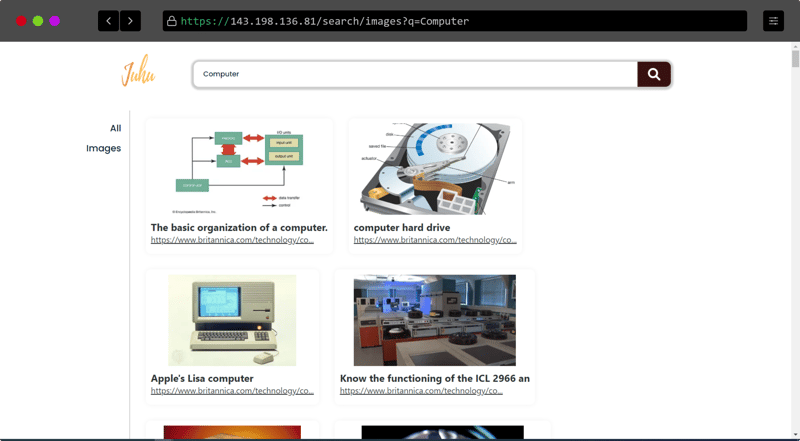
Some Screenshots of the website
- Home page

- Text Result (Search result) page
- Image result (Search result) page
Collaborators
@roshanacharya and me @aashishpanthi
- Check out Redis OM, client libraries for working with Redis as a multi-model database.
- Use RedisInsight to visualize your data in Redis.
- Sign up for a free Redis database.





Top comments (0)