Introduction
A serverless database is a database that is hosted and managed by a third-party provider. This means you do not need to worry about the hardware, software, or maintenance of the database. You can simply connect to the database and start using it.
Serverless databases are a good option for businesses that do not have the resources to manage their database. They are also a good option for businesses that need to scale their database quickly. Such examples of serverless databases are FaunaDB, CockroachDB, Amazon DynamoDB, and so on.
In this tutorial, you will learn how to build a serverless database to store SMS messages sent to your WhatsApp number, and also their classification, if they are spam or not. You will use Twilio MessagingX SMS API to receive SMS messages on your Fast API backend which will send these data into FaunaDB.
Prerequisites
Python 3.9+ is installed on your machine.
FaunaDB free account, if you dont have one, you can set it up here.
Twilio free account, you can set up one here.
Ngrok account, follow this guide to set up one.
An IDE or text editor, such as VS code.
Hugging Face account, you can set one up here
Setting up the Development Environment
Before you start, you need to set up the development environment by creating the directory and files you will need.
mkdir sms_classifier
cd sms_classifier
touch requirements.txt models.py utils.py main.py .env
requirements.txt contains the required libraries to build the database.
model.py contains the code connecting the Fast API app to FaunaDB
utils.py contains the code to connect to the sms classification model on Hugging Face.
main.py contains the code to build the Fast API server
sms_classifier is the directory for all our files.
Next, you create and activate a virtual environment and update the Python package manager pip to the most recent version, to know more about the benefits of using virtual environments. Ensure you read this post.
python -m venv venv; ./venv/Scripts/Activate; pip - upgrade pip
If you are on a Linux machine use,
pyton -m venv venv; venv\\Scripts\\activate.bat; pip - upgrade pip
Next, fill the requirements.txt file with the following dependencies,
fastapi
uvicorn
faunadb
pyngrok
requests
dotenv
fastapiis a Python framework for building APIs quickly and easilyuvicornis a lightning-fast server implementation for Pythonpyngrokenables you to tunnel a local server to a public URLrequestsallows you to send HTTP requests using Pythondotenvloads the environment variables from the.envfile.faunadbis a Python driver allowing you to connect to the fauna server.
Install these dependencies by running the following command on your terminal
pip install -r requirements.txt
Connecting to Fauna Database
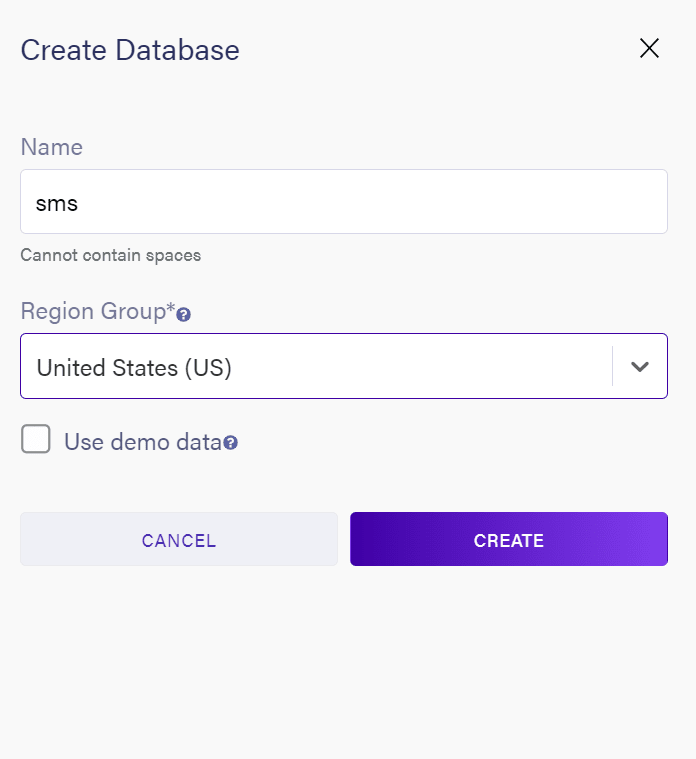
On the Fauna home page, click on Create Database ,

Next, give the name of your database, which is SMS, and select a Region Group then click Create.
Go to Security and click on New Key to create your fauna key
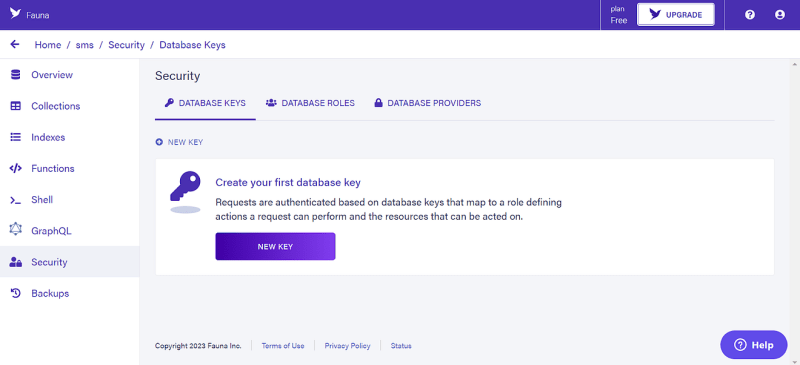
Select the role as Server and Save

Copy the fauna key displayed to you, then go to the .env file and create a variable called FAUNA_SECRET and paste it there.
FAUNA_SECRET=<secret>
Go to the models.py and paste the following code
from faunadb import query as q
from faunadb.client import FaunaClient
from dotenv import load_dotenv
import os
load_dotenv()
client = FaunaClient(secret=os.getenv("FAUNA_SECRET"),
endpoint="https://db.us.fauna.com/")
collection_name = "sms"
# Check if collection exists
try:
client.query(q.get(q.collection(collection_name)))
print(f"Collection '{collection_name}' already exists.")
except:
# Collection doesn't exist, create it
client.query(q.create_collection({"name": collection_name}))
print(f"Collection '{collection_name}' created successfully.")
load_dotenv() loads the environment variables into models.py
The FaunaClient() function is used to create a client object that can be used to interact with the FaunaDB database. It creates a fauna client using the secret key and fauna endpoint.
collection_name stores the name of the collection, q.get checks if a collection with the name sms exists, and if false, client.query creates a new collection sms, collections are like tables in SQL.
Run the code above and go back to the database you created earlier on. You will see the already created collection sms.

The dashboard shows no document in the collection, documents are NoSQL versions of rows in tables. Each SMS and its data will make up a document in the SMS collection.
Building the Spam Classifier Model Function
An SMS spam classifier classifies an SMS as spam or ham (not spam). One can build a spam classifier from scratch, but this needs a lot of data and computing resources to get an accurate model. You are going to set up a hugging face account and use an already pre-built model from hugging face. Thanks to hugging face, you dont need to build an SMS spam classifier from scratch.
To get a Hugging Face API key, go to Settings and click on Access Tokens
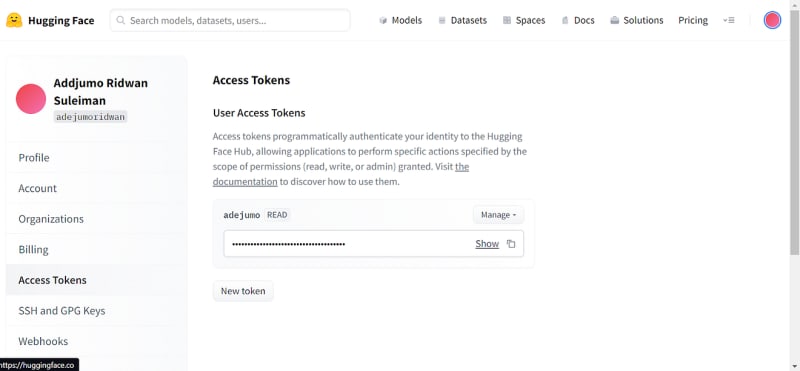
Create a new token with READ role by clicking on New Token
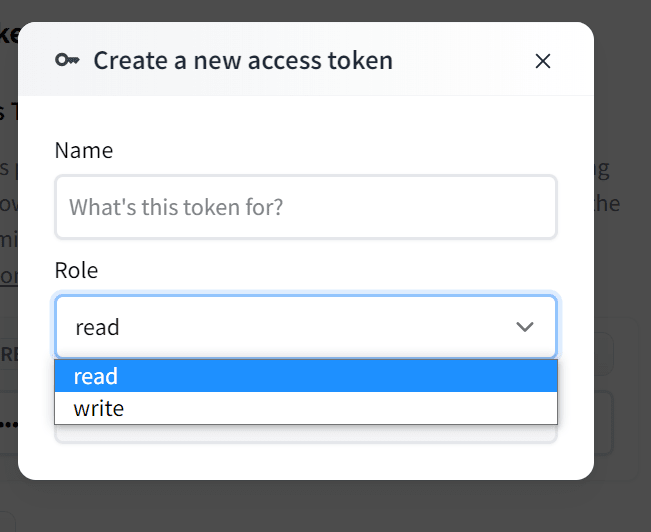
Copy this token and paste it to the .env file, and store it as HUGGING_API_KEY
HUGGING_API_KEY="<api_key>"
FAUNA_SECRET="<fauna_secret>"
Copy and paste the following code below into utils.py
from dotenv import load_dotenv
import os
import requests
load_dotenv()
api_key=os.getenv("API_KEY")
# SMS Classification
def sms_spam_class(sms):
API_URL = "https://api-inference.huggingface.co/models/mrm8488/bert-tiny-finetuned-sms-spam-detection"
headers = {"Authorization": f"Bearer {api_key}"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "f{sms}",
})
# Find the scores for 'LABEL_0' and 'LABEL_1'
label_0_score = None
label_1_score = None
for item in output[0]:
if item['label'] == 'LABEL_0':
label_0_score = item['score']
elif item['label'] == 'LABEL_1':
label_1_score = item['score']
# Check if 'LABEL_1' score is greater than 'LABEL_0' score
if label_1_score is not None and label_0_score is not None:
if label_1_score > label_0_score:
spam_class = "spam"
else:
spam_class = "ham"
else:
spam_class = "Unable to determine spam status."
return spam_class
The sms_spam_class() function checks if a given sms is spam or not, API_URL contains the reference link to the spam classification model API. The headers contain the Hugging Face api_key which allows you to make requests from the API using the requests library.
The function query() takes in the payload which is sms. This function makes a POST request using the requests.post function and returns a JSON response response.json() stored in the variable output.
The output contains the score of the word for various labels, the for loop checks each label score and stores the values into their respective variables, label_0_score and label_1_score for Label_0 and Label_1 respectively. Label_0 shows an SMS as ham (not spam) while Label_1 shows an SMS as spam.
If the score in Label_0 is greater than Label_1 then the SMS is spam else the SMS is ham , and it saves the resulting classification in spam_class.
Setting up the webhook with ngrok
Inside the main.py, set up a basic Fast API application
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def index():
return {"message": "I love Serverless"}
The code below sets up a basic fastapi backend, creating a new instance of the Fast API class and assigning it to the app variable. The @app.get decorator creates a new endpoint that you can access with an HTTP GET request. The endpoint is at the root URL / and returns a JSON response with a single key-value pair: message: I love Serverless.
To run the app, run the following command in your terminal:
uvicorn main:appreload
On your browser, open the host http://127.0.0.1:8000, you will see a JSON response of {message: I love Serverless}, you can also access an interactive API doc provided by swagger on the host http://127.0.0.1:8000/doc which allows you to interact with your API and see if you have any errors.

To receive Twilio messages on the backend, you are going to use ngrok to host the local host on a public server. Read this post to learn how to set up ngrok on your machine.
On ngrok administrator, run the command ngrok http 8000, this makes your host public and you can receive messages on your backend.
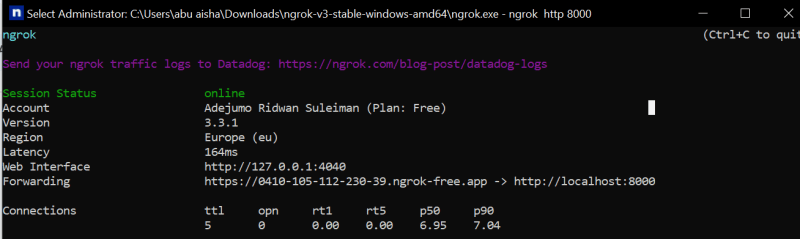
Log in to Twilio Studio, under Phone Numbers go to Manage then Buy a Number to buy a Twilio Number.
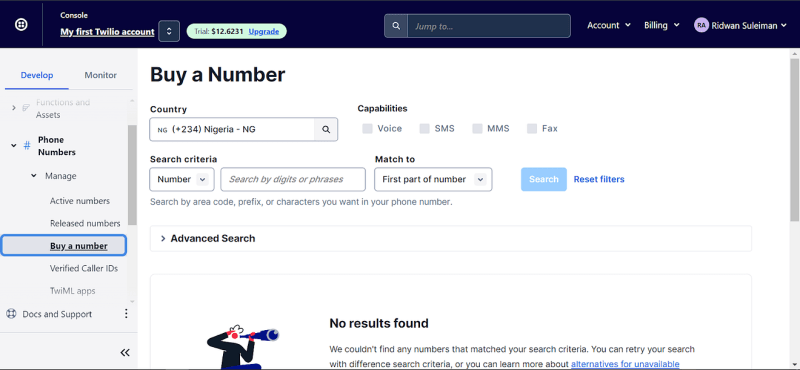
Next, go to Active Numbers to see your number, and click on the number. On the dashboard displayed to you, click on Configure and go to Message Configuration , paste the ngrok address into the URL under When a message comes in and click Save configuration , this allows Twilio to request your fast API app anytime you receive an incoming message, congratulations you just set up a Webhook.
Building the Fast API Application
Update the main.py with the code below
from fastapi import FastAPI, Form, Request
from utils import sms_spam_class
from dotenv import load_dotenv
import os
from faunadb import query as q
from model import client
load_dotenv()
app = FastAPI()
@app.post("/sms")
async def reply(request: Request):
form_data = await request.form()
MessageSid = form_data["MessageSid"]
AccountSid = form_data["AccountSid"]
From = form_data["From"]
Body = form_data["Body"]
To = form_data["To"]
spam_class = sms_spam_class(Body)
response = client.query(q.create(q.collection("sms"), {"data": {
"MessageSid": MessageSid,
"AccountSid": AccountSid,
"From": From,
"Body": Body,
"To": To,
"spam_classification": spam_class
}}))
return ""
The code above sends a POST request at the endpoint /sms, the reply function takes the Twilio request as the query parameter. This will give us information on what and what was in the message you receive on your Twilio number.
await request.form() stores the message data into form_data, there are a lot of parameters when Twilio requests your webhook URL.
In this tutorial, you will just make use of some of the parameters. You can explore other parameters in their documentation.
MessageSidis a unique identifier assigned to every messageAccountSidis a unique identifier assigned to every Twilio accountFromis the phone number sending the messageTois the phone number receiving the messageBodyis the body of the SMS
sms_spam_class(Body) is the function you built earlier on classifying if a model is spam or not, storing the value in spam_class.
The response variable stores all the parameters gotten from the SMS data in the database collection SMS.
Getting the Server up and running
Now your fast API app is ready to receive and store messages in the fauna database,
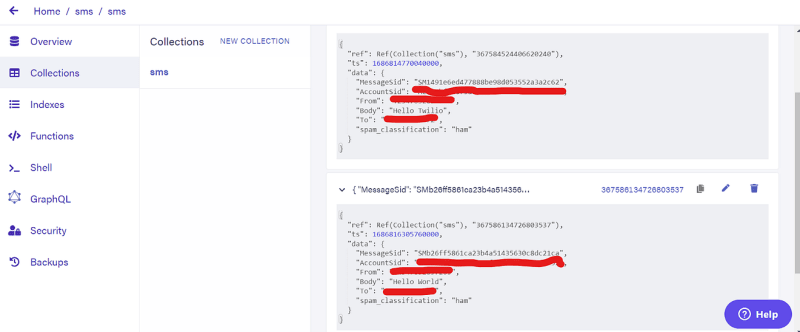
Here is an example of an SMS sent to a Twilio number:
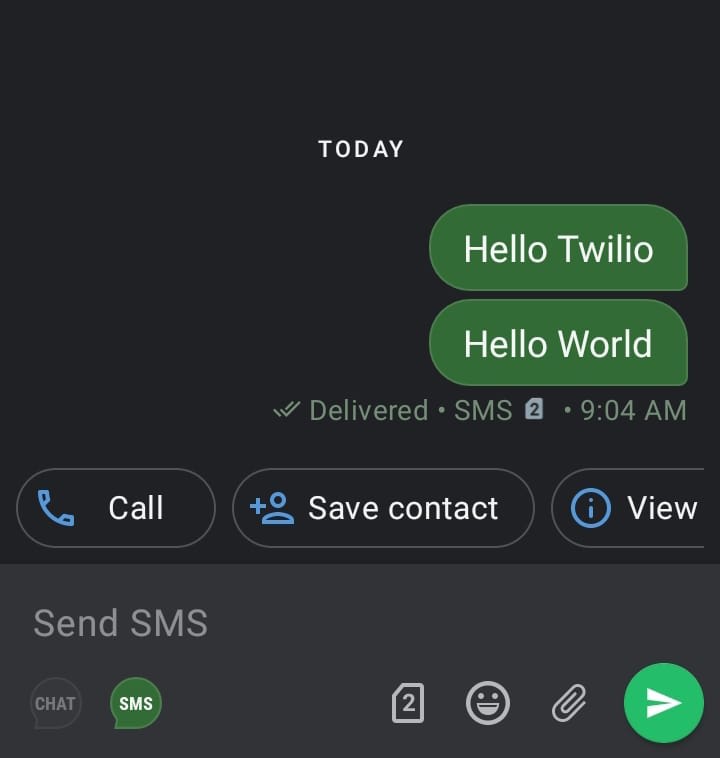
On Fauna, you will see the text messages reflected as follows:
Conclusion
In this tutorial, you learned how to create a Fauna serverless database that stores SMS messages and also their spam classification built on Fast API. You also learned about how to connect to pre-built models on Hugging Face.
You can extend this app by adding more parameters from the Twilio request made to your webhook such as media URL, date a message was sent and received, and so on.
You can also try another serverless database like Cassandra, Redis, MongoDB and so on.





Top comments (0)