👋 Introduction
What is Scrapy?
Scrapy is an open-source web scraping framework written in Python that provides an easy-to-use API for web scraping, as well as built-in functionality for handling large-scale web scraping projects, support for different types of data extraction, and the ability to work with different web protocols.
Why use Scrapy?
Scrapy is the preferred tool for large-scale scraping projects due to its advantages over other popular Python web scraping libraries such as BeautifulSoup.
BeautifulSoup is primarily a parser library, whereas Scrapy is a complete web scraping framework with handy built-in functionalities such as dedicated spider types for different scraping tasks and the ability to extend Scrapys functionality by using middleware and exporting data to different formats.
Some real-world examples where Scrapy can be useful include:
E-commerce websites: Scrapy can be used to extract product information such as prices, descriptions, and reviews from e-commerce websites such as Amazon, Walmart, and Target.
Social media: Scrapy can be used to extract data such as public user information and posts from popular social media websites like Twitter, Facebook, and Instagram.
Job boards: Scrapy can be used to monitor job board websites such as Indeed, Glassdoor, and LinkedIn for relevant job postings.
It's important to note that Scrapy has some limitations. For example, it cannot scrape JavaScript-heavy websites. However, we can easily overcome this limitation by using Scrapy alongside other tools like Selenium or Playwright to tackle those sites.

Beautiful Soup vs. Scrapy for web scraping
Learn the differences between these Python scraping tools.
 blog.apify.com
blog.apify.com
Alright, now that we have a good idea of what Scrapy is and why it's useful, let's dive deeper into Scrapy's main features.
🎁 Exploring Scrapy Features
Types of Spiders 🕷
One of the key features of Scrapy is the ability to create different types of spiders. Spiders are essentially the backbone of Scrapy and are responsible for parsing websites and extracting data. There are three main types of spiders in Scrapy:
Spider : The base class for all spiders. This is the simplest type of spider and is used for extracting data from a single page or a small set of pages.
CrawlSpider : A more advanced type of spider that is used for extracting data from multiple pages or entire websites. CrawlSpider automatically follows links and extracts data from each page it visits.
SitemapSpider : A specialized type of spider that is used for extracting data from websites that have a sitemap.xml file. SitemapSpider automatically visits each URL in the sitemap and extracts data from it.
Here is an example of how to create a basic Spider in Scrapy:
import scrapy
class MySpider(scrapy.Spider):
name = "myspider"
start_urls = ["<http://example.com>"]
def parse(self, response):
# extract data from response
This spider, named myspider, will start by requesting the URL http://example.com. The parse method is where you would write code to extract data from the response.
Here is an example of how to create a CrawlSpider in Scrapy:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class MyCrawlSpider(CrawlSpider):
name = "mycrawlspider"
start_urls = ["<http://example.com>"]
rules = [
Rule(LinkExtractor(), callback='parse_item', follow=True)
]
def parse_item(self, response):
# extract data from response
This spider, named mycrawlspider, will start by requesting the URL http://example.com. The rules list contains one Rule object that tells the spider to follow all links and call the parse_item method on each response.
Extending Scrapy with Middlewares 🔗
Middlewares allow us to extend Scrapys functionality. Scrapy comes with several built-in middlewares that can be used out of the box.
Additionally, we can also write your own custom middleware to perform tasks like modifying request headers, logging, or handling exceptions. So, lets take a look at some of the most commonly used Scrapy middlewares:
- UserAgentMiddleware: This middleware allows you to set a custom User-Agent header for each request. This is useful for avoiding detection by websites that may block scraping bots based on the User-Agent header. To use this middleware, we can set it up on our Scrapy settings file like this:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy.downloadermiddlewares.useragent': 500,
}
In this example, we're using a priority of 500 for the built-in UserAgentMiddleware to ensure that it runs before other downloader middlewares.
By default, UserAgentMiddleware sets the User-Agent header for each request to a randomly chosen user-agent string. You can customize the user agent strings used by setting the USER_AGENT setting in your Scrapy settings.
Note that we first set UserAgentMiddleware to None before adding it to the DOWNLOADER_MIDDLEWARES setting with a different priority.
This is because the default UserAgentMiddleware in Scrapy sets a generic user agent string for all requests, which may not be ideal for some scraping scenarios. If we need to use a custom user agent string, we'll need to customize the UserAgentMiddleware.
Therefore, by setting UserAgentMiddleware to None first, we're telling Scrapy to remove the default UserAgentMiddleware from the DOWNLOADER_MIDDLEWARES setting before adding our own custom instance of the middleware with a different priority.
-
RetryMiddleware: Scrapy comes with a
RetryMiddlewarethat can be used to retry failed requests. By default, it retries requests with HTTP status codes 500, 502, 503, 504, 408, and when an exception is raised. You can customize the behavior of this middleware by specifying theRETRY_TIMESandRETRY_HTTP_CODESsettings. To use this middleware in its default configuration, you can simply add it to your Scrapy settings:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
}
- HttpProxyMiddleware: This middleware allows you to use proxies to send requests. This is useful for avoiding detection and bypassing IP rate limits. To use this middleware, we can add it to our Scrapy settings file like this:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
'myproject.middlewares.ProxyMiddleware': 100,
}
PROXY_POOL_ENABLED = True
This will enable the HttpProxyMiddleware and also enable the ProxyMiddleware that we define. This middleware will select a random proxy for each request from a pool of proxies provided by the user.
-
CookiesMiddleware: This middleware allows you to handle cookies sent by websites. By default, Scrapy stores cookies in memory, but you can also store them in a file or a database by specifying the
COOKIES_STORAGEin the Scrapy settings. To add **CookiesMiddleware**to the **DOWNLOADER_MIDDLEWARES**setting, we simply specify the middleware class and its priority. In this case, we're using a priority of700, which should be after the defaultUserAgentMiddlewareand **RetryMiddleware**but before any custom middleware.
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
}
Now we can use CookiesMiddleware to handle cookies sent by the website:
from scrapy import Spider, Request
class MySpider(Spider):
name = 'myspider'
start_urls = ['<https://www.example.com/>']
def start_requests(self):
for url in self.start_urls:
# Send an initial request without cookies
yield Request(url, cookies={}, callback=self.parse)
def parse(self, response):
# Extract cookies from the response headers
cookies = {}
for cookie in response.headers.getlist('Set-Cookie'):
key, value = cookie.decode('utf-8').split('=', 1)
cookies[key] = value.split(';')[0]
# Send a new request with the cookies received
yield Request('<https://www.example.com/protected>', cookies=cookies, callback=self.parse_protected)
def parse_protected(self, response):
# Process the protected page here
pass
When the spider sends an initial request to https://www.example.com/, we're not sending any cookies yet. When we receive the response, we extract the cookies from the response headers and send a new request to a protected page with the received cookies.
These are just a few of the uses for middlewares in Scrapy. The beauty of middlewares is that we are able to write our own custom middleware to continue expanding Scrapys features and performing additional tasks to fit our specific use cases.
Exporting Scraped Data 📤
Scrapy provides built-in support for exporting scraped data in different formats, such as CSV, JSON, and XML. You can also create your own custom exporters to store data in different formats.
Heres an example of how to store scraped data in a CSV file in Scrapy:
Note that this is a very basic example, and the
closedmethod could be modified to handle errors and ensure that the file is closed properly. Also, the code is merely explanatory, and you will have to adapt it to make it work for your use case.
import scrapy
from scrapy.exporters import CsvItemExporter
class MySpider(scrapy.Spider):
name = 'example'
start_urls = ['<https://www.example.com>']
def parse(self, response):
items = response.xpath('//div[@class="item"]')
for item in items:
yield {
'title': item.xpath('.//h2/text()').get(),
'description': item.xpath('.//p/text()').get(),
}
def closed(self, reason):
filename = "example.csv"
with open(filename, 'w+b') as f:
exporter = CsvItemExporter(f)
exporter.fields_to_export = ['title', 'description']
exporter.export_item(item for item in self.parse())
In this example, we define a spider that starts by scraping the "https://www.example.com" URL. We then define a parse method that extracts the title, price, and description for each item on the page. Finally, in the closed method, we define a filename for the CSV file and export the scraped data using the CsvItemExporter.
Another way of exporting extracted data in different formats using Scrapy is to use the scrapy crawl command and specify the desired file format of our output. This can be done by appending the -o flag followed by the filename and extension of the output file.
For example, if we want to output our scraped data in JSON format, we would use the following command:
scrapy crawl myspider -o output.json
This will store the scraped data in a file named output.json in the same directory where the command was executed. Similarly, if we want to output the data in CSV format, we would use the following command:
scrapy crawl myspider -o output.csv
This will store the scraped data in a file named output.csv in the same directory where the command was executed.
Overall, Scrapy provides multiple ways to store and export scraped data, giving us the flexibility to choose the most appropriate method for our particular situation.
Now that we have a better understanding of what is possible with Scrapy, let's explore how we can use this framework to extract data from real websites. We'll do this by building a few small projects, each showcasing a different Scrapy feature.
🛠 Project: Building a Hacker News Scraper using a basic Spider
In this section, we will learn how to set up a Scrapy project and create a basic Spider to scrape the title, author, URL, and points of all articles displayed on the first page of the Hacker News website.
Creating a Scrapy Project
Before we can generate a Spider, we need to create a new Scrapy project. To do this, we'll use the terminal. Open a terminal window and navigate to the directory where you want to create your project. Start by installing Scrapy:
pip install scrapy
Then run the following command:
scrapy startproject hackernews
This command will create a new directory called "hackernews" with the basic structure of a Scrapy project.
Creating a Spider
Now that we have a Scrapy project set up, we can create a spider to scrape the data we want. In the same terminal window, navigate to the project directory using cd hackernews and run the following command:
scrapy genspider hackernews_spider news.ycombinator.com
This command will create a new spider in the spiders directory of our project. We named the spider hackernews_spider and set the start URL to news.ycombinator.com, which is our target website.
Writing the Spider Code
Next, lets open the hackernews_spider.py file in the spiders directory of our project. We'll see a basic template for a Scrapy Spider.
import scrapy
class HackernewsSpiderSpider(scrapy.Spider):
name = 'hackernews_spider'
allowed_domains = ['news.ycombinator.com']
start_urls = ['http://news.ycombinator.com/']
def parse(self, response):
pass
Before we move on, lets quickly break down what were seeing:
nameattribute is the name of the Spider.allowed_domainsattribute is a list of domains that the Spider is allowed to scrape.start_urlsattribute is a list of URLs that the Spider should start scraping fromparsemethod is the method that Scrapy calls to handle the response from each URL in thestart_urlslist.
Cool, now for the fun part. Let's add some code to the parse method to scrape the data we want.
import scrapy
class HackernewsSpiderSpider(scrapy.Spider):
name = 'hackernews_spider'
allowed_domains = ['news.ycombinator.com']
start_urls = ['http://news.ycombinator.com/']
def parse(self, response):
articles = response.css('tr.athing')
for article in articles:
yield {
"URL": article.css(".titleline a::attr(href)").get(),
"title": article.css(".titleline a::text").get(),
"rank": article.css(".rank::text").get().replace(".", "")
}
In this code, we use the css method to extract data from the response. We select all the articles on the page using the CSS selector tr.athing, and then we extract the title , URL , and rank for each article using more specific selectors. Finally, we use the yield keyword to return a Python dictionary with the scraped data.
Running the Hacker News Spider
Now that our Spider is ready, let's run it and see it in action.
By default, the data is output to the console, but we can also export it to other formats, such as JSON, CSV, or XML, by specifying the output format when running the scraper. To demonstrate that, lets run our Spider and export the extracted data to a JSON file:
scrapy crawl hackernews -o hackernews.json
This will save the data to a file named **hackernews.json** in the root directory of the project. You can use the same command to export the data to other formats by replacing the file extension with the desired format (e.g., o hackernews.csv for CSV format).
That's it for running the spider. In the next section, we'll take a look at how we can use Scrapy's CrawlSpider to extract data from all pages on the Hacker News website.
🛠 Project: Building a Hacker News Scraper using the CrawlSpider
The previous section demonstrated how to scrape data from a single page using a basic Spider. While it is possible to write code to paginate through the remaining pages and scrape all the articles on HN using the basic Spider, Scrapy offers us a better solution: the CrawlSpider. So, without further ado, lets jump straight into the code.
Project Setup
To start, let's create a new Scrapy project called hackernews_crawlspider using the following command in your terminal:
scrapy startproject hackernews_crawlspider
Next, let's create a new spider using the CrawlSpider template. The CrawlSpider is a subclass of the Spider class and is designed for recursively following links and scraping data from multiple pages.
scrapy genspider -t crawl hackernews_spider https://news.ycombinator.com/
This command generates a new spider called "hackernews_spider" in the "spiders" directory of your Scrapy project. It also specifies that the spider should use the CrawlSpider template and start by scraping the homepage of Hacker News.
Code
Our goal with this scraper is to extract the same data from each article that we scraped in the previous section: URL, title, and rank. The difference is that now we will define a set of rules for the scraper to follow when crawling through the website. For example, we will define a rule to tell the scraper where it can find the correct links to paginate through the HN content.
With this in mind, thats what the final code for our use case will look like:
# Add imports CrawlSpider, Rule and LinkExtractor 👇
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
# Change the spider from "scrapy.Spider" to "CrawlSpider"
class HackernewsSpider(CrawlSpider):
name = 'hackernews'
allowed_domains = ['news.ycombinator.com']
start_urls = ['<https://news.ycombinator.com/news>']
custom_settings = {
'DOWNLOAD_DELAY': 1 # Add a 1-second delay between requests
}
# Define a rule that should be followed by the link extractor.
# In this case, Scrapy will follow all the links with the "morelink" class
# And call the "parse_article" function on every crawled page
rules = (
Rule(LinkExtractor(allow=[r'news\\.ycombinator\\.com/news$']), callback='parse_article'),
Rule(LinkExtractor(restrict_css='.morelink'), callback='parse_article', follow=True),
)
# When using the CrawlSpider we cannot use a parse function called "parse".
# Otherwise, it will override the default function.
# So, just rename it to something else, for example, "parse_article"
def parse_article(self, response):
for article in response.css('tr.athing'):
yield {
"URL": article.css(".titleline a::attr(href)").get(),
"title": article.css(".titleline a::text").get(),
"rank": article.css(".rank::text").get().replace(".", "")
}
Now lets break down the code to understand what the CrawlSpider is doing for us in this scenario.
You may notice that some parts of this code were already generated by the CrawlSpider, while other parts are very similar to what we did when writing the basic Spider.
The first distinctive piece of code that may catch your attention is the custom_settings attribute we have included. This adds a 1-second delay between requests. Since we are now sending multiple requests to access different pages on the website, having this additional delay between the requests can be useful in preventing the target website from being overwhelmed with too many requests at once.
Next, we defined a set of rules to follow when crawling the website using the rules attribute:
rules = (
Rule(LinkExtractor(allow=[r'news\\.ycombinator\\.com/news$']), callback='parse_article'),
Rule(LinkExtractor(restrict_css='.morelink'), callback='parse_article', follow=True),
)
Each rule is defined using the Rule class, which takes two arguments: a LinkExtractor instance that defines which links to follow; and a callback function that will be called to process the response from each crawled page. In this case, we have two rules:
The first rule uses a
LinkExtractorinstance with anallowparameter that matches URLs that end with "news.ycombinator.com/news". This will match the first page of news articles on Hacker News. We set thecallbackparameter toparse_article, which is the function that will be called to process the response from each page that matches this rule.The second rule uses a
LinkExtractorinstance with arestrict_cssparameter that matches themorelinkclass. This will match the "More" link at the bottom of each page of news articles on Hacker News. Again, we set thecallbackparameter toparse_articleand thefollowparameter toTrue, which tells Scrapy to follow links on this page that match the provided selector.
Finally, we defined the parse_article function, which takes a response object as its argument. This function is called to process the response from each page that matches one of the rules defined in the rules attribute.
def parse_article(self, response):
for article in response.css('tr.athing'):
yield {
"URL": article.css(".titleline a::attr(href)").get(),
"title": article.css(".titleline a::text").get(),
"rank": article.css(".rank::text").get().replace(".", "")
}
In this function, we use the response.css method to extract data from the HTML of the page. Specifically, we look for all tr elements with the athing class and extract the URL, title, and rank of each article. We then use the yield keyword to return a Python dictionary with this data.
Remember that the yield keyword is used instead of return because Scrapy processes the response asynchronously, and the function can be called multiple times.
It's also worth noting that we've named the function parse_article instead of the default parse function that's used in Scrapy Spiders. This is because when you use the CrawlSpider class, the default parse function is used to parse the response from the first page that's crawled. If you define your own parse function in a CrawlSpider, it will override the default function, and your spider will not work as expected.
To avoid this problem, its considered good practice to always name our custom parsing functions something other than parse. In this case, we've named our function parse_article, but you could choose any other name that makes sense for your Spider.
Running the CrawlSpider
Great, now that we understand whats happening in our code, its time to put our spider to the test by running it with the following command:
scrapy crawl hackernews -o hackernews.json
This will start the spider and scrape data from all the news items on all pages of the Hacker News website. We also already took the opportunity to tell Scrapy to output all the scraped data to a JSON file, which will make it easier for us to visualize the obtained results.
🕸 How to scrape JavaScript-heavy websites
Scraping JavaScript-heavy websites can be a challenge with Scrapy alone since Scrapy is primarily designed to scrape static HTML pages. However, we can work around this limitation by using a headless browser like Playwright in conjunction with Scrapy to scrape dynamic web pages.
Playwright is a library that provides a high-level API to control headless Chrome, Firefox, and Safari. By using Playwright, we can programmatically interact with our target web page to simulate user actions and extract data from dynamically loaded elements.
To use Playwright with Scrapy, we have to create a custom middleware that initializes a Playwright browser instance and retrieves the HTML content of a web page using Playwright. The middleware can then pass the HTML content to Scrapy for parsing and extraction of data.
Luckily, the scrapy-playwright library lets us easily integrate Playwright with Scrapy. In the next section, we will build a small project using this combo to extract data from a JavaScript-heavy website, Mint Mobile. But before we move on, lets first take a quick look at the target webpage and understand why we wouldnt be able to extract the data we want with Scrapy alone.
Mint Mobile requires JavaScript to load a considerable part of the content displayed on its product page, which makes it an ideal scenario for using Playwright in the context of web scraping:
Mint Mobile product page with JavaScript disabled:
![]()
Mint Mobile product page with JavaScript enabled:
![]()
As you can see, without JavaScript enabled, we would lose a significant portion of the data we want to extract. Since Scrapy cannot load JavaScript, you could think of the first image with JavaScript disabled as the "Scrapy view," while the second image with JavaScript enabled would be the "Playwright view.
Cool, now that we know why we need a browser automation library like Playwright to scrape this page, it is time to translate this knowledge into code by building our next project: the Mint Mobile scraper.
🛠 Project: Building a web scraper using Scrapy and Playwright
In this project, well scrape a specific product page from the Mint Mobile website: https://www.mintmobile.com/product/google-pixel-7-pro-bundle/
Project setup
We start by creating a directory to house our project and installing the necessary dependencies:
# Create new directory and move into it
mkdir scrapy-playwright
cd scrapy-playwright
Installation:
# Install Scrapy and scrapy-playwright
pip install scrapy scrapy-playwright
# Install the required browsers if you are running Playwright for the first time
playwright install
Next, we start the Scrapy project and generate a spider:
scrapy startproject scrapy_playwright_project
scrapy genspider mintmobile https://www.mintmobile.com/
Now let's activate scrapy-playwright by adding a few lines of configuration to our DOWNLOAD_HANDLERS middleware.
# scrapy-playwright configuration
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
Great! Were now ready to write some code to scrape our target website.
Code
import scrapy
from scrapy_playwright.page import PageMethod
class MintmobileSpider(scrapy.Spider):
name = 'mintmobile'
def start_requests(self):
yield scrapy.Request('<https://www.mintmobile.com/product/google-pixel-7-pro-bundle/>',
meta= dict(
# Use Playwright
playwright = True,
# Keep the page object so we can work with it later on
playwright_include_page = True,
# Use PageMethods to wait for the content we want to scrape to be properly loaded before extracting the data
playwright_page_methods = [
PageMethod('wait_for_selector', 'div.m-productCard--device')
]
))
def parse(self, response):
yield {
"name": response.css("div.m-productCard__heading h1::text").get().strip(),
"memory": response.css("div.composited_product_details_wrapper > div > div > div:nth-child(2) > div.label > span::text").get().replace(':', '').strip(),
"pay_monthly_price": response.css("div.composite_price_monthly > span::text").get(),
"pay_today_price": response.css("div.composite_price p.price span.amount::attr(aria-label)").get().split()[0],
};
In the start_requests method, the spider makes a single HTTP request to the mobile phone product page on the Mint Mobile website. We initialize this request using the scrapy.Request class while passing a meta dictionary setting the options we want to use for Playwright to scrape the page. These options include playwright set to True to indicate that Playwright should be used, followed by playwright_include_page also set to True to enable us to save the page object so that it can be used later, and playwright_page_methods set to a list of PageMethod objects.
In this case, theres only one PageMethod object, which uses Playwright's wait_for_selector method to wait for a specific CSS selector to appear on the page. This is done to ensure that the page has properly loaded before we start extracting its data.
In the parse method, the spider uses CSS selectors to extract data from the page. Four pieces of data are extracted: the name of the product, its memory capacity, the pay_monthly_price, as well as the pay_today_price.
Expected output:
Finally, lets run our spider using the command scrapy crawl mintmobile -o data.json to scrape the target data and store it in a data.json file:
[
{
"name": "Google Pixel 7 Pro",
"memory": "128GB",
"pay_monthly_price": "50",
"pay_today_price": "589"
}
]
Deploying Scrapy spiders to the cloud
Next, well learn how to deploy Scrapy Spiders to the cloud using Apify. This allows us to configure them to run on a schedule and access many other features of the platform.
To demonstrate this, well use the Apify SDK for Python and select the Scrapy development template to help us kickstart the setup process. Well then modify the generated boilerplate code to run our CrawlSpider Hacker News scraper. Let's get started.
Installing the Apify CLI
To start working with the Apify CLI, we need to install it first. There are two ways to do this: via the Homebrew package manager on macOS or Linux or via the Node.js package manager (NPM).
Via homebrew
On macOS (or Linux), you can install the Apify CLI via the Homebrew package manager.
brew install apify/tap/apify-cli
Via NPM
Install or upgrade the Apify CLI by running:
npm -g install apify-cli
Creating a new Actor
Once you have the Apify CLI installed on your computer, simply run the following command in the terminal:
apify create scrapy-actor
Then, go ahead and select Python Scrapy Install template
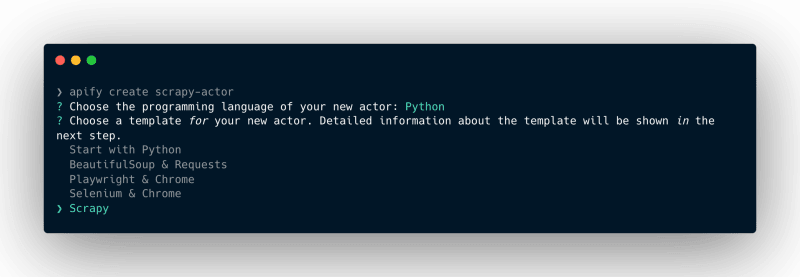
This command will create a new folder named scrapy-actor, install all the necessary dependencies, and create a boilerplate code that we can use to kickstart our development using Scrapy and the Apify SDK for Python.
Finally, move into the newly created folder and open it using your preferred code editor, in this example, Im using VS Code.
cd scrapy-actor
code .
Configuring the Scrapy Actor template
The template already creates a fully functional scraper. You can run it using the command apify run. If youd like to try it before we modify the code, the scraped results will be stored under storage/datasets .
Now that were familiar with the template, we can modify it to accommodate our HackerNews scraper.
To make our first adjustment, we need to replace the template code in src/spiders/title_spider.py with our own code. After the replacement, your code should look like this:

# Add imports CrawlSpider, Rule and LinkExtractor 👇
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
# Change the spider from "scrapy.Spider" to "CrawlSpider"
class HackernewsSpider(CrawlSpider):
name = 'hackernews'
allowed_domains = ['news.ycombinator.com']
start_urls = ['<https://news.ycombinator.com/news>']
custom_settings = {
'DOWNLOAD_DELAY': 1 # Add a 1-second delay between requests
}
# Define a rule that should be followed by the link extractor.
# In this case, Scrapy will follow all the links with the "morelink" class
# And call the "parse_article" function on every crawled page
rules = (
Rule(LinkExtractor(allow=[r'news\\.ycombinator\\.com/news$']), callback='parse_article'),
Rule(LinkExtractor(restrict_css='.morelink'), callback='parse_article', follow=True),
)
# When using the CrawlSpider we cannot use a parse function called "parse".
# Otherwise, it will override the default function.
# So, just rename it to something else, for example, "parse_article"
def parse_article(self, response):
for article in response.css('tr.athing'):
yield {
"URL": article.css(".titleline a::attr(href)").get(),
"title": article.css(".titleline a::text").get(),
"rank": article.css(".rank::text").get().replace(".", "")
}
Finally, before running the Actor, we need to make some adjustments to the main.py file to align it with the modifications we made to the original spider template.

from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from apify import Actor
from .pipelines import ActorDatasetPushPipeline
from .spiders.hackernews_spider import HackernewsSpider
async def main():
async with Actor:
actor_input = await Actor.get_input() or {}
max_depth = actor_input.get('max_depth', 1)
start_urls = [start_url.get('url') for start_url in actor_input.get('start_urls', [{ 'url': '<https://news.ycombinator.com/news>' }])]
settings = get_project_settings()
settings['ITEM_PIPELINES'] = { ActorDatasetPushPipeline: 1 }
settings['DEPTH_LIMIT'] = max_depth
process = CrawlerProcess(settings, install_root_handler=False)
# If you want to run multiple spiders, call `process.crawl` for each of them here
process.crawl(HackernewsSpider, start_urls=start_urls)
process.start()
Running the Actor locally
Great! Now we're ready to run our Scrapy actor. To do so, lets type the command apify run in our terminal. After a few seconds, the storage/datasets will be populated with the scraped data from Hacker News.

Deploying the Actor to Apify
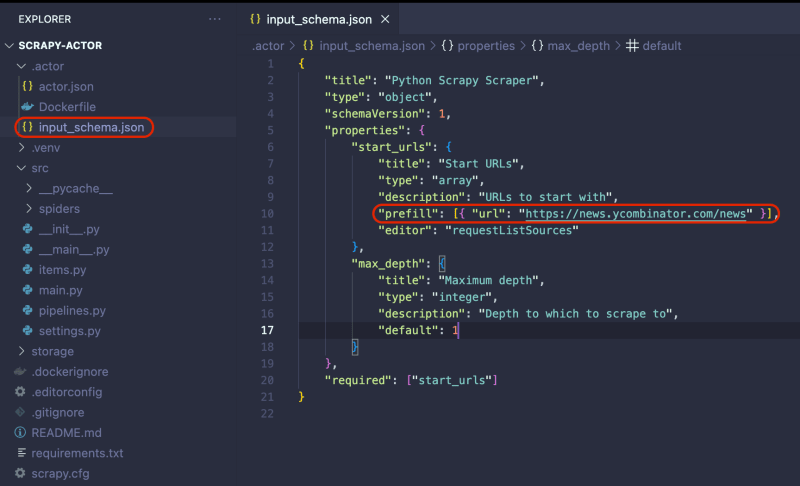
Before deploying the Actor to Apify, we need to make one final adjustment. Go to .actor/input_schema.json and change the prefill URL to https://news.ycombinator.com/news. This change is important when running the scraper on the Apify platform.
Now that we know that our Actor is working as expected, it is time to deploy it to the Apify Platform. You will need to sign up for a free Apify account to follow along.
Once you have an Apify account, run the command apify login in the terminal. You will be prompted to provide your Apify API Token. Which you can find in Apify Console under Settings Integrations.
The final step is to run the apify push command. This will start an Actor build, and after a few seconds, you should be able to see your newly created Actor in Apify Console under Actors My actors.

Perfect! Your scraper is ready to run on the Apify platform. To begin, click the Start button. Once the run is finished, you can preview and download your data in multiple formats in the Storage tab.

Scrapy alternatives: other web scraping libraries to try
5 Scrapy alternatives for web scraping you need to try.
blog.apify.com
Next steps
If you want to take your web scraping projects to the next level with the Apify SDK for Python and the Apify platform, here are some useful resources that might help you:
More Python Actor templates
Web Scraping Python tutorials
Web Scraping community on Discord
Finally, don't forget to join the Apify & Crawlee community on Discord to connect with other web scraping and automation enthusiasts. 🚀





Top comments (0)