
If you're an engineering leader, in one way or another, you're building a product that's changing the world, and you're doing it with a team that continuously strives to be better at what they do.
But engineering is not a linear process. So, how do you ensure that you're not stumping growth with faulty processes?
The key is to understand how different parts of your software delivery pipeline (and beyond) are connected and the levers you can fix to harness that full potential.
Velocity, Volume, Engagement, Quality & Outcome: I believe these are the five things you need to measure in your software delivery pipeline. By zooming in on each one, you will be able to identify those critical levers for success. Let’s explore each of these metrics and what role they play.
🏎️ Velocity
Velocity is always a measure of time, usually an average, that allows you to assess the agility and leanness of your team across all the stages of the software delivery pipeline (WIP → Review → Merge → Release → Deploy).
Lead Time is a good example of a metric that tells you how fast you're moving from starting to work on code to releasing it in production.
Lead Time is a metric borrowed from lean thinking and manufacturing disciplines. It’s defined as the amount of time between the moment work begins until it’s delivered to the end-customer.
How shorter lead times impacts the team’s output performance:
🚀 Faster feedback loop with your users
🚀 Beating competition to market
🚀 Reducing risk in the deployment process by working in smaller batches
💡 In Google's 2019 DevOps research, the authors revealed that High-Performance Organisations have a Lead Time of under a week, and Elite organizations under a day.

Athenian allows you to quickly spot which segment of the pipeline adds the most time to total lead time. Generally speaking, this segment should then be tackled first.
📦 Volume
Volume helps you understand how much was done.
Volume is a difficult metric because a single unit of work, for example a pull request or a review, cannot be compared to one another. Maybe a one line bug fix was highly complex and took 10 hours, while 500 lines of code were easily added to a low risk/complexity component. But without aggregate volumes it is hard to understand the other type of metrics.
💡 If my Lead Time is 5 hours on average for 3 pull requests, that doesn't tell me much about the speed of our team, but if it is 5 hours for 300 pull requests, it starts painting a picture.

Volume is also key to understanding your processes. If a team releases 100 Pull Requests in a sprint and I see that only 20 were reviewed, volume is again important to help me understand how we work.
🔬 Engagement
Engagement is a measure of how many contributors are involved.
My favorite example is a growing team. As we add additional members to the team, does our volume of work increase while maintaining the same speed and quality? These are the kind of questions that can only be answered by knowing how many contributors were active during a period.
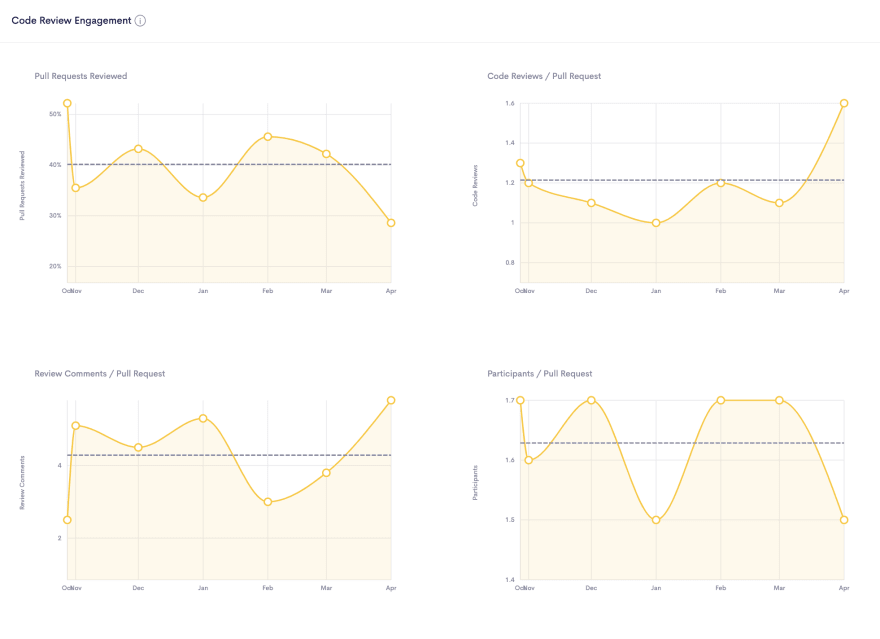
Understand how engaged developers are in the code review process.
⭐ Quality
Quality is a metric that needs to be proxied by metrics like # of bugs by priority that give an indication of the quality of the software delivered, you can also look at the Bugs Fixing Ratio and other subsequent metrics (like MTTR by bug priority).
💡 Quality metrics should be as close as possible to the end-user experience of your software.
Without quality metrics, it is easy to find yourself going at a faster speed, or increasing volume but if that is at the sake of delivering a worse user experience to your end-users. The trade-off between Quality, Velocity and Customer Impact is something I’ve written about here.
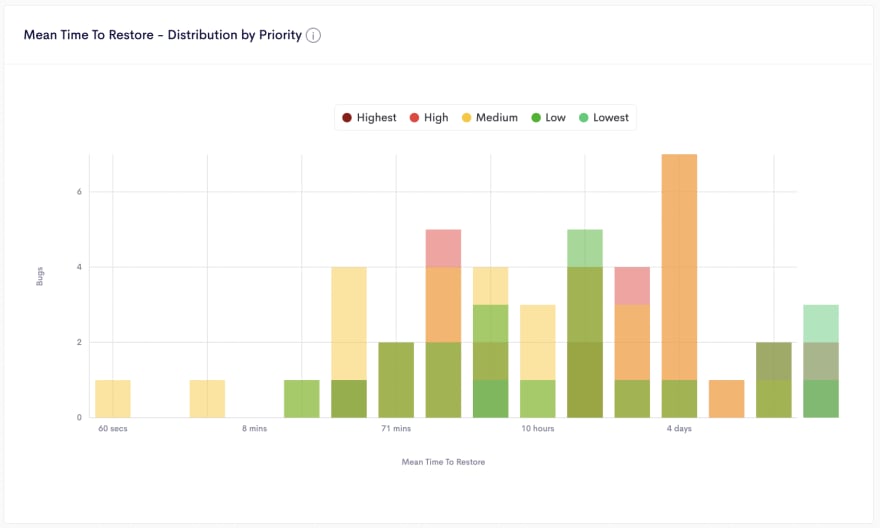
Ensure bugs are resolved in no time and set quantitative goals depending on the levels of priority.
🎯 Outcome
Outcome measures the business goals we had for the software we are delivering.
Often when we are building software it is easy to be removed from the business objectives we are impacting. For instance, refactoring a major component without changing its behavior, how does that really relate to our end user? Other times we are delivering a new feature in an application, for example, the ability to buy a book online with 1 click instead of 4, that can clearly map to the business objectives.

If you want specific teams to focus on shipping new features instead of paying tech debt, Athenian provides granular visibility.
💡 Outcome is sometimes hard to measure, but when you can, it helps align everyone.
Athenian uses the Athenian Insights Graph to automatically correlate output to outcome across the full delivery pipeline. Our platform is made for teams and doesn’t provide metrics on individual engineers.
With Athenian, organizations of all sizes can get end-to-end visibility into their software delivery pipeline, improve velocity and quality, and align teams with company priorities. Find out more!





Top comments (0)