01 Background
Unisound is an AI company focused on speech and natural language processing technology. The technology stack has grown to a full-stack AI capability with images, natural language processing, signals, etc. It is the head AI unicorn company in China. The company embraces cloud computing and has corresponding solutions in healthcare,hotels, education industry etc.
Atlas is Unisound’s internal HPC platform, which supports Unisound with basic computing capabilities such as training acceleration for model iterations.
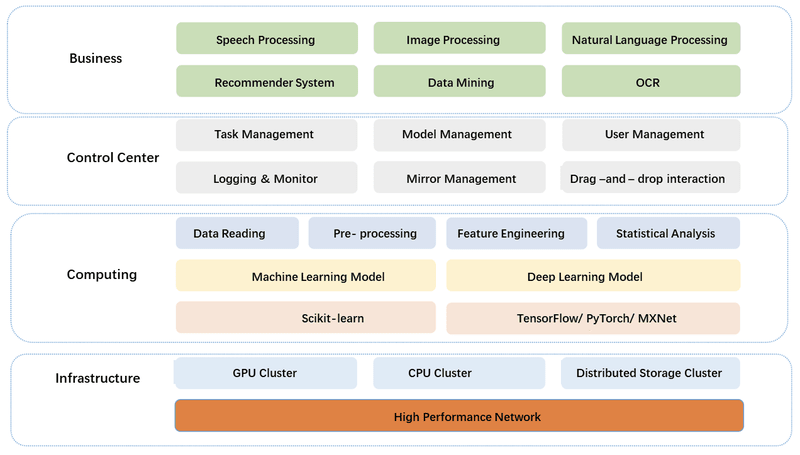
(Atlas Architecture)
- The top layer is the business layer, which handles speech processing, image processing, natural language processing, etc.
- The second layer is the control center, which is responsible for data production, data access and model release.
- The third layer is the core computing layer, which supports deep learning, and data pre-processing.
- The bottom layer is the infrastructure layer, which consists of GPU cluster, computing cluster and distributed storage. all machines are interconnected with 100 Gbps InfiniBand high-speed network.
02 Scenarios and Storage Challenges
The initial goal of Atlas is to build a one-stop AI platform, including AI model production, data pre-processing, model development, model training, and model launch.

As shown above, each step in the pipeline deals with data, data pre-processing and model training require relatively large IO.
- Data pre-processing: speech processing extracts speech features and converts the features into numpy format files; While image processing transforms the data for training.
- Model development: algorithm engineers edit code and debug model algorithms.
- Model training: There will be multiple rounds of data reading, and the model will be output to the corresponding storage. This step requires a very large IO.
When the model is launched, the service will read the model file in the storage system.
To summarize our requirements for storage:First: it can work with the entire model development pipeline.
Second: it can support CPU and GPU data read tasks.
Third: our scenario is mainly voice, text and image data processing. These scenarios are characterized by relatively small file size, so we need to support high-performance small file processing.
Fourth: in the phase of model training, we usually have lots of data to read rather than write.
Based on these requirements, we need a high-performance and reliable distributed storage system.
03 History and evolution of storage
In the early days, we only had about a dozen GPUs, and we used NFS to make a small-scale cluster. Meanwhile we evaluated CephFS in 2016. At that time, CephFS did not perform well in small file scenarios, so we did not bring CephFS into the production environment.
Then we continued research and found that Lustre is the most commonly used file system in the HPC space. Tests showed that Lustre performed well at scale, so from 2017 to 2022, we used Lustre to host all our data operations.
But as more and more GPUs are used, now with 57 PFLOPS, the IO of the underlying storage can no longer keep up with the computing capabilities of the application layers.
So, we started exploring new solutions for storage expansion, while encountering some problems with Lustre.
- First: Maintenance, Lustre is based on the kernel, sometimes troubleshooting the problem will involve the reboot of the machine.
- Second: technology stack, our cloud platform uses golang, so it is more inclined to use storage that fits better with the development language.Lustre uses the C language, which requires more human effort in customization and optimization.
- Third: data reliability, Lustre mainly relies on hardware reliability (such as RAID technology), and ensuring HA for metadata nodes and data nodes. Compared to these, we still prefer to use more reliable software solutions such as triple replicas or erasure coding.
- Fourth: The need for multi-level caching capabilities. In 2021, we used Fluid + Alluxio as a distributed acceleration for Lustre, and Alluxio was able to do a better job of speeding up our cluster and reducing the pressure on the underlying storage. But we've been exploring the idea of doing client-side caching directly from the storage system, so that the operation can be more transparent to the user.

When JuiceFS was first open sourced in 2021, we did research on its features.
- First, features: JuiceFS supports POSIX and can be mounted by HostPath, which is exactly the same as the way we use NAS, so users basically do not have to make any changes; Users can choose metadata and object storage flexibly according to their seniors. For metadata engines,AI users can choose Redis and TiKV. And there will be lots of options for object storage : Ceph, MinIO etc.
- Second, scheduling: JuiceFS supports not only HostPath, but also CSI-driven ,which enables users to access the storage in a more cloud-native way.
- Third, framework adaptation: the POSIX interface is suitable for adapting deep learning frameworks.
- Fourth, O&M: there are lots of mature solutions for metadata engine and object storage. And JuiceFS has automatic metadata backup and recycle bin function.
Since JuiceFS is a good fit for business, we conducted a POC test.
The test environment is shown in the figure below.

It turns out that compared to Lustre's direct access to mechanical disks, there is a significant performance improvement using JuiceFS (the smaller the better, as shown in the figure below), thanks to JuiceFS' use of kernel page caching.
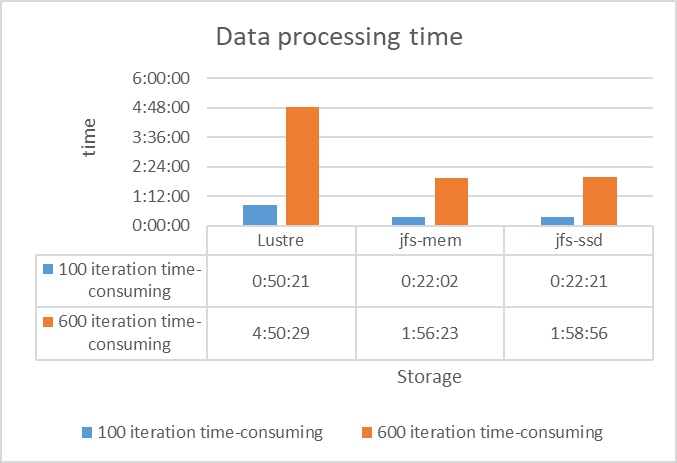
After POC, we decided to bring JuiceFS into the production environment. The JuiceFS client is currently installed on all GPU compute nodes of the entire Atlas cluster, as well as all development nodes.

JuiceFS is directly connected to redis clusters and ceph, and most of the compute nodes are accessed by HostPath. At the same time, Atlas cluster also deployed JuiceFS CSI Driver, thus users can use JuiceFS in a cloud-native way.
04 How JuiceFS was used in Atlas
To ensure data security, each group on Atlas belongs to a different directory, and under each directory are the members within their respective groups or departments, and the directories between different groups are not visible.

The directory permissions are based on the Linux permission model. When a user submits a training task in Atlas cluster, the task submission tool of the cluster will automatically read the UID and GID information of the user on the system, and then inject it into the SecurityContext field of the task Pod submitted by the user, so that the UIDs of all the container processes running in the container Pod on Atlas cluster are consistent with the information on the storage system to ensure the security of permissions.

Node access to JuiceFS, which implements a multi-level cache.
- The first level of cache is the page cache of memory.
- The second tier is multiple SSDs for all the compute nodes to provide the second level of acceleration.
- The third tier is ceph. If three 1t SSDs still can't support the user's data, then it will read from ceph.
At the beginning of 2021, we integrated JuiceFS Runtime into Fluid together with the JuiceFS team. Because cache resides in bare-metal, we found that the user's visibility of the cache is not good, and the cache cleanup is all done automatically by the system, so the user's customizability is not that high, that's why we integrated JuiceFS into Fluid.
Fluid launches JuiceFS-related components, including FUSE and Worker Pod, where FUSE Pod provides caching capabilities for JuiceFS clients and Worker Pod enables cache lifecycle management. Nodes, while users are able to visualize cache usage (e.g., size of cached datasets, percentage of cache, cache capacity, etc.).
When in model training, the JuiceFS FUSE client is used to read the entire metadata engine and object storage data.
05 Adopting and building JuiceFS
Currently Atlas does not have access to the public network, it is on a private, isolated network, so we are deploying it all privately.

We use Redis as the metadata engine for our production environment. In 2020, TiKV is not very mature, so we used Redis for transition first, and Ceph for object storage. The data is persisted once per second.
The object storage is a self-hosted Ceph cluster. Ceph clusters are deployed using Cephadm, and the current production environment is using the Octopus version. We borrowed a lot of industry solutions and made some optimizations to the storage at the memory level, as well as the corresponding tuning at the software level, mainly as follows.
Server(reference).
- 42 Cores 256GB 24*18T HDD
- System Disk: 2* 960G SAS SSD
- BlueStore
- Disable NUMA
- Upgrade kernel: 5.4.146, io_uring enabled
Kernel pid max, modify /proc/sys/kernel/pid_max
Ceph configurationCeph RADOS: direct call to librados interface, no S3 protocol
Bucket shard
Disable auto-tuning of pg
OSD log storage (bluestore, recommended bare capacity ratio - block : block.db : block.wal = 100:1:1, SSD or NVMe SSD recommended for the last two)
3 Copy
In particular, we need to upgrade the kernel of the Ceph cluster to a newer version and turn on the io_uring feature, so that the performance will be greatly improved. In terms of software, we directly call the rados interface, so we don't use the S3 protocol, which is a little more efficient.
JuiceFS is connected to Ceph RADOS, which is the object storage in UniSound’s environment.JuiceFS uses librados to interact with Ceph, so you need to recompile the JuiceFS client, and it is recommended that the version of librados should correspond to that of Ceph, so pay attention to that.
If you use CSI Driver, the creation of PV/PVC will read /etc/ceph/ceph.conf and also pay attention to the version support.
Complete monitoring system
Now the whole chain is longer. The bottom layer has a metadata engine cluster, Ceph object storage cluster, and the upper layer of clients , each layer should have a corresponding monitoring solution.
In the client node, we mainly do the log collection. It is important to note that each mount point JuiceFS client logs should be collected and monitored, properly rotate the logs so that disks are not filled full. .
Each JuiceFS client should also have the appropriate monitoring means. For example, check the .stat file and logs of each mount point to observe whether the indicators are normal, and then look at the IO and logs of redis and ceph clusters to ensure that the entire link is controllable, so that it is easier to locate the problem.

The above diagram is the monitoring diagram of ceph, because our client node is using SSD cache, now the data is basically not read to Ceph, most of it is read by cache, so the traffic of Ceph is not much.

The above figure is the data intercepted from JuiceFS monitoring, you can see that the nodes are basically 100% to 90% hit, the cache hit rate is still relatively high.
Participate in JuiceFS community

In the process of using JuiceFS Community Edition, we have been actively involved in building the community. In 2021, we worked with Juicedata team to develop Fluid JuiceFS Runtime. And recently, we found that the community version of directory-based quota has not been developed, so we developed a version a few months ago to limit the number of files and file size of the directory, the PR has been submitted, and now we are working with JuiceFS community to merge.
06 Scenarios and benefits of JuiceFS in Atlas
JuiceFS client’s multi-level cache is currently used in text recognition, speech noise suppression and speech recognition scenarios. Since the data access patterns of AI model training are characterized by more reads and fewer writes, we make full use of the client-side cache to bring the acceleration benefit of IO reads.
AI model training acceleration
1) Noise Suppression Test
The data used in the test of noise reduction scenario are unmerged raw files, each data is a small file of less than 100KB and in WAV format. We tested the I/O performance of the data load phase with a memory cache of 512G on the JuiceFS client node and a batch size of 40 for a 500 hours size data.

According to the test results, in terms of data reading efficiency alone, JuiceFS is 6.45 it/s for small WAV files, while Lustre is 5.15 it/s, a 25% performance improvement. JuiceFS effectively accelerates our end-to-end model training and reduces model output time overall.
2)Text recognition scenarios
In the text recognition scenario, the model is CRNN and the backbone is MobileNetV2. The test environment is as follows:

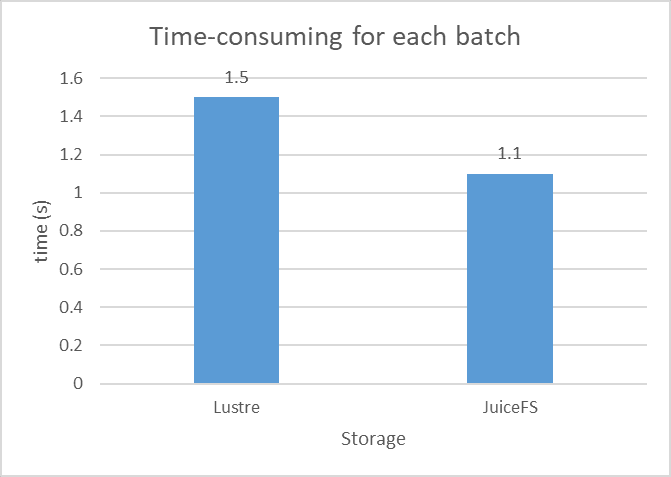
In this test, we have done the speed comparison between JuiceFS and Lustre. From the experimental results, it takes 1.5s to read each batch from Lustre and 1.1s to read each batch from JuiceFS, which is a 36% improvement. In terms of model convergence time, it decreases from 96 hours for Lustre to 86 hours for JuiceFS. Using JuiceFS can reduce the output time of CRNN model by 10 hours.
Model debugging & data processing

When doing code debugging, multiple users would run model tests and code traversal on a debugging machine at the same time. At that time, statistics showed that most users would use some remote IDEs to connect to debug nodes and then build their own virtual environments, and would install a large number of installation packages on Lustre in advance.
Most of them are small files of tens or hundreds of kilobytes, and we have to import these packages on our memory. Previously, when using Lustre, the demand throughput was high because there were too many users, and the performance requirements for small files were high, so we found that the results were not very good, and we were stuck when importing packages, which led to slower debugging of code and lower overall efficiency.
Later, we used the cache of the JuiceFS client, which was also slow in the first compilation, but the second compilation was faster and more efficient because the data had all fallen on the cache, the code jump was faster, and the code hint import was faster. There is about 2~4 times speedup after user testing.
07 Summary
From Lustre to JuiceFS
From 2017 to 2021, it was stable to use Lustre, especially when the cluster storage was less than 50%. As the veteran storage system in the HPC domain, Lustre has powered many world's largest HPC systems, with years of experience in production environments.
But there are some drawbacks.
- First, Lustre cannot support the cloud-native CSI Driver.
- Second, Lustre's requirements for maintenance staff are relatively high, because it’s written in c, sometimes some bugs can not be quickly resolved, and the overall openness and activity of the community is not very high.
And the advantages of JuiceFS are as follows:
- First, JuiceFS is a cloud-native distributed storage system, providing CSI Driver and Fluid for better integration with Kubernetes.
- Second, it is quite flexible to deploy JuiceFS. There are many options for metadata engine and object storage services.
- Third, the maintenance of JuiceFS is simple. Full compatibility with the POSIX allows deep learning applications to migrate seamlessly, but due to the characteristics of the object storage, JuiceFS random write latency is high.
- Fourth, JuiceFS supports local caching, kernel page caching, which enables layering and acceleration of hot and cold data. This is something we value and is more appropriate in our scenario, but not so much when it comes to random writes. The community version currently does not provide distributed caching yet either.
Planning
- First,upgrade the metadata engine. TiKV is suitable for scenarios with more than 100 million files (up to 10 billion files) and high requirements for performance and data security. We have finished the internal testing of TiKV and are actively following up the progress of the community. We will migrate the metadata engine to TiKV.
- Second, optimize the directory quota. The features of the basic version have been merged into the JuiceFS community version. And we also discussed with the JuiceFS community in order to optimize in some scenarios.
- Third, we want to do some non-root features. Currently JuiceFS requires root privileges in all nodes. We want to restrict root privileges to specific nodes.
- Finally, we will also see if the community has a QoS solution, such as UID-based or GID-based speed limits.
About Author
Dongdong Lv, Architect of Unisound HPC Platform
He is responsible for the architecture design and development of the large-scale distributed machine learning platform, as well as application optimization of deep learning algorithms and acceleration of AI model training. His research areas include large-scale cluster scheduling, high-performance computing, distributed file storage, distributed caching, etc. He is also a fan of the open source community, especially cloud native related. And he has contributed several important features to the JuiceFS community.
From Juicedata/JuiceFS ! (0ᴗ0✿)




Top comments (0)