
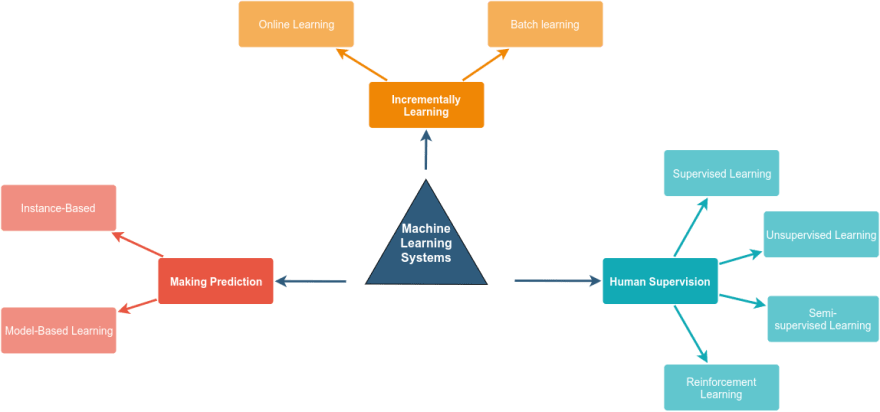
Many people classified the machine learning system into supervised learning and unsupervised learning, but the truth, the machine learning systems can be categorized into many categories and the criteria of categorizing them not exclusive in one way.
Some of the factors which the systems classified based on it are:
- Human Supervision (Supervised, Unsupervised, Semisupervised, and Reinforcement Learning).
- Incrementally Learning (Online and Batch learning).
- Making Prediction (Instance-Based and Model-Based Learning).
Let's look deeper into each of these criteria …
Human Supervision
Machine learning systems can be classified based on the type of supervision into four major categories:
Supervised Learning
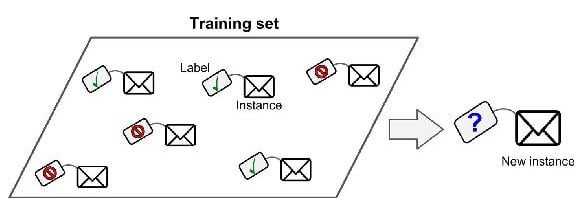
In supervised learning, the training data introduced to the system have to include the label of each sample. For example in a spam classifier, the algorithm needs each message with its label, to know if this message is spam or not to learn how to classify new messages, and this task called classification.
And in another example with house prices prediction, the algorithm needs every house specifications, the label of the house and this case will be the price, to make the system able to predict the new house price and this task called Regression.
Unsupervised Learning
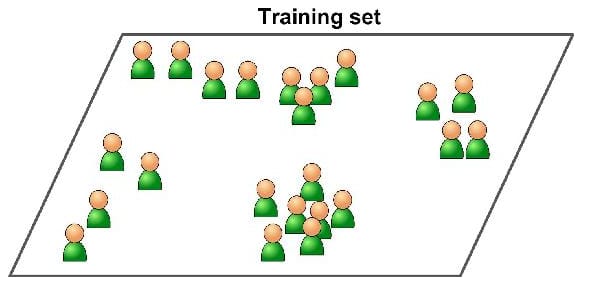
In unsupervised learning, the training data fed to the system haven't any label describes the sample belongs to which class, and for that it's must rely on itself to determine patterns of samples, which reduces the accuracy of the algorithm, However, it is the most important of these categories because most the data unlabeled and need to find patterns between them.
Some of the most used tasks in unsupervised learning are Clustering (split the dataset into groups, based on similar patterns between data points), Anomaly detection (discover unusual data points in the dataset and used it, is useful for finding fraudulent transactions, and finding outliers in data preprocessing phase) and Dimensionality reduction (also used in data preprocessing phase to reduce the number of features in the dataset).
Semi-supervised Learning
In supervised learning, the mix of labeled and unlabeled data make the model combines between the supervised and unsupervised techniques, for example by using labeled data in model training, and then use the trained model to classify the unlabeled data, and then feed all the high probability predicted data to re-train the model, with a larger amount of labeled data, this technique called pseudo-labeling.

Reinforcement Learning
In reinforcement learning, the system is very different the learning system called agent can observe the environment and learn from it, by performing actions then get a reward for a good action or penalty for a bad action, this strategy schema called policy which defines what action the agent should choose when it is in a given situation.

Incrementally Learning
Another criterion to classify machine learning systems is based on the ability to learn incrementally from a stream of coming data.
Batch Learning
This type of systems need to train on all of the available data and take more time and computation resources and calling offline learning because it learns offline and then launched into production and runs without learning, after that when we need to train new version of the system, we have to retrain the model from scratch away from production version on all data (old & new) then replace the trained model with the new one.
The simple example on this type of systems, when you try to build cat vs not cat image classifier trained on cats images on the day and after some time we need to introduce the night images, then we need to take all night and day cat images and retrain our model then deploy the new model in new release.
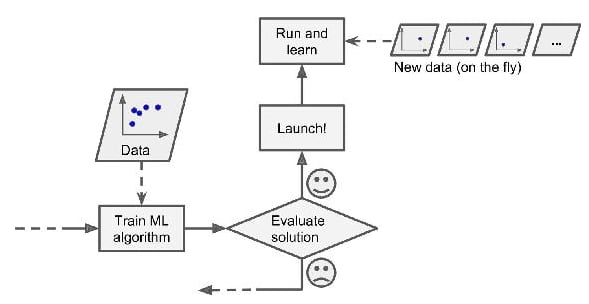
Online Learning
The idea of online learning is to train the system incrementally by feeding it data points sequentially, or by a small group called mini-batches, online learning is great for systems that receive data as continues flow and need to adapt quickly with new changes, and don't care too much with a long history, and the most known example of this systems is "Stocks prices prediction model" which learns on the fly to adapt with recent changes in stocks prices with less importance to too old reading.
But one of the big challenges in this type of systems is the bad quality data fed to the system, the system's performance will gradually decline, some examples of the bad data are wrong readings in stock prices or someone spamming a search engine in a try to rank high in search results, and to reduce this risk we need to add monitoring layer like anomaly detection algorithm able to detect any abnormal data can affect model performance, and switch learning off until the quality of data improving.
Making Prediction
The last factor that can separate machine learning systems into two types is how the model generalizes to making predictions for new data has never seen before.
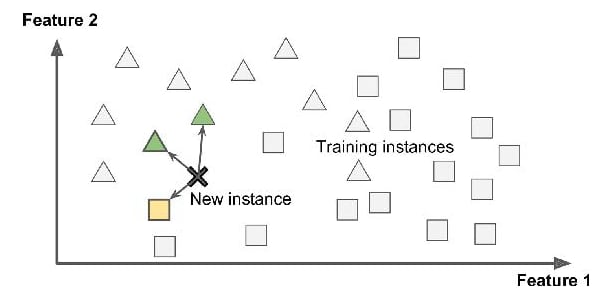
Instance-based Learning
To be able to classify a new data point the algorithm calculates the distance between the new data point, and all the points in your data set and predict the class in which the new data point belongs.
Model-based Learning
Another way to generalize from a set of examples is to build a model of these examples, then use that model to make predictions. This is called model-based learning, and build the model here means some equation has parameters to tune alternate the instance-based learning which depends on similarity as the main choice.

If we look for the house prices prediction problem and try to fit it in these types we can find two scenarios for learning:
1st scenario: take the unknown house that we need to find its price, and measure the similarity between house features, and all labeled data points, then set the new house price based on the most similar house in our data, or average of the most similar k houses, that called model-based learning.
2nd scenario: by building equation from features and use an algorithm to tune these parameters the can fit, and generalize the house prices data, then get the feature values, and substitute with it in the equation to get the new house price.
Finally, all of these most common categories is a try to look for machine learning systems from multiple perspectives.





Top comments (0)