Tables are one of the most common elements in PDF documents, such as electronic invoices, financial reports, or whatever PDF documents that contain tabular data. Developers may encounter the situations where they need to extract data out of PDF tables and do further analysis. In this article, I am going to introduce how to programmatically extract data from tables in PDF files in seconds using Spire.PDF for Java.
Installing Spire.Pdf.jar
If you use Maven, you can easily import the Spire.Pdf.jar in your application by adding the following code to your project’s pom.xml file. For non-Maven projects, download the jar file from this link and manually add it as a dependency in your application.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId> e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<verson>4.11.2</version>
</dependency>
</dependencies>
Using the code
Spire.PDF offers the PdfTableExtractor.extractTable() method to extract tables from a specific page. Below are the main steps to extract tables from a whole PDF document.
- Load a sample PDF document while initializing the PdfDocument object.
- Loop through the pages in the document, and get the table collection from a specific page using extractTable() method.
- Loop through the rows and columns of a certain table, and get the value of a specific cell using PdfTable.getText(int rowIndex, int columnIndex) method.
- Write the extracted data in a TXT file.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTablesFromPdf {
public static void main(String[] args) throws IOException {
//Load a sample PDF document
PdfDocument pdf = new PdfDocument("C:\\Users\\Administrator\\Desktop\\Table.pdf");
//Create a StringBuilder instance
StringBuilder builder = new StringBuilder();
//Create a PdfTableExtractor instance
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
//Declare variables
PdfTable[] pdfTables = null;
int tableNumber = 1;
//Loop through the pages
for (int pageIndex = 0; pageIndex < pdf.getPages().getCount(); pageIndex++) {
//Extract tables from the current page
pdfTables = extractor.extractTable(pageIndex);
//If any tables are found
if (pdfTables != null && pdfTables.length > 0) {
//Loop through the tables in the array
for (PdfTable table : pdfTables) {
builder.append("Table " + tableNumber);
builder.append("\r\n");
//Loop through the rows in the current table
for (int i = 0; i < table.getRowCount(); i++) {
//Loop through the columns in the current table
for (int j = 0; j < table.getColumnCount(); j++) {
//Extract data from the current table cell
String text = table.getText(i, j);
//Append the text to the string builder
builder.append(text + " ");
}
builder.append("\r\n");
}
builder.append("\r\n");
tableNumber += 1;
}
}
}
//Write data into a .txt document
FileWriter fw = new FileWriter("output/ExtractTables.txt");
fw.write(builder.toString());
fw.flush();
fw.close();
}
}
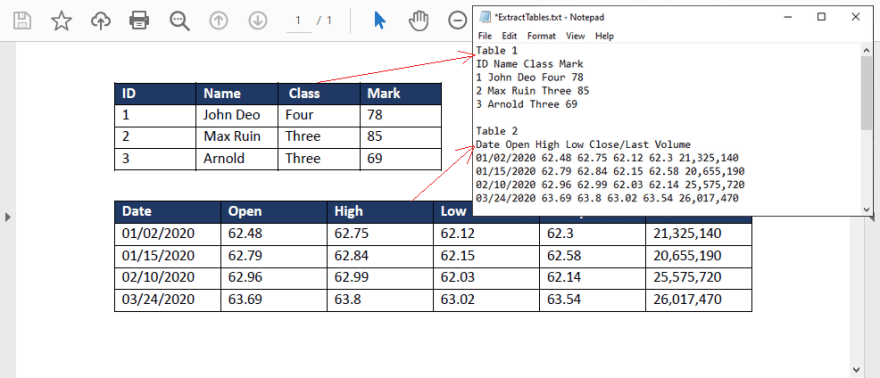
Output





Top comments (0)