
Really? Why?
To keep your mind off the severity of the current situation. To stay busy, and to use your skills to keep your family and friends informed. To learn something new while you keep your busy behind at home.
So… a week or so ago, out of nowhere, I decided that I wanted to be able to get the most recent COVID-19 numbers without having to use a browser. There were a few states in particular that were important to me, and I wanted to be able to see the number of confirmed cases in those states by typing a command in a terminal.
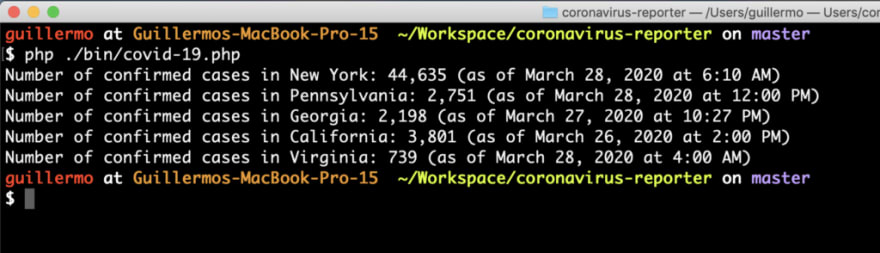
That’s all there was to it when I started. I figured I could ping the CDC’s site to get the info, but I noticed that the department of health websites seemed to have the most up-to-date information. I took a look at a few of those DOH sites, viewed the source (the way only very cool people do when they surf the Interwebs), and determined that I could easily scrape some pages to get the info I wanted using regular expressions, DOM traversal, and super fancy string parsing.
What started out as a CLI became a CLI + web API because I couldn’t help myself. An HTML page came to be because my wife wanted to know what I was working on, and I didn’t think she’d be too impressed by a JSON string. I went serverless because this was a green field project and it’s 2020 and my free time is too precious to be spent OS patching and because why in the world would I pay for a server and because come on already!
What’s Involved
PHP… again
I wanted to do this quickly, so I used the language that I knew best: PHP. I threw together a PHP skeleton to start the millions of unfinished projects I tend to bring to life, and I used it for this project. I also used Flysystem’s PSR-6 implementation for filesystem caching — I was actually unaware of the PSR-6 vs. PSR-16 discussions that popped up over the years; I chose PSR-6 because I thought the provided CacheItemPoolInterface would work well in this situation, allowing me to easily change cache storage options if I felt the need.
Other Stuff
An older version of Bref (I’m not ready to make the jump over to the version that leverages the Serverless framework) made it easy for me to use AWS SAMto deploy an AWS Lambda function. I used Amazon API Gateway to serve up the endpoint, and used Amazon CloudWatch to schedule the population of the cache, which lives in Amazon S3.
Scraping
This was the most interesting challenge because it required me to keep up with the way each state rolled out their changes. New York, for instance, made several changes to the way they displayed their data over time. Every few updates, they’d wrap the count in a different set of tags, or surround it with different characters. In most cases, though, it came down to doing some simple pattern matching:
$page = file_get_contents('https://the.url'); // grab the HTML
preg_match('/total to (.*) confirmed cases/', $page, $matches);
I invariably ended up having to do some cleanup on whatever existed in $matches[1], but that ended up being pretty simple. I did some similar matching to get the timestamps for the updates.
Putting it All Together
Deploying with Travis CI and AWS SAM
To get the code deployed up to a Lambda function, I followed the steps I walked though in an older post about Bref and Lambda. The one new thing to note is that I had to set the Python version in the .travis.yml file to 3.6.7 or 3.7.1 due to updates in the AWS tools.
API Gateway Setup
Once the Lambda function was deployed, I created a REST API endpoint using the API Gateway.

When I clicked on “ Build ” in the REST API box, I was led to a screen where I was able to add resources and methods to the API. Using the “ Actions ” dropdown, I created a resource named casesby choosing the “ Create resource ” option. I enabled CORS for good measure.
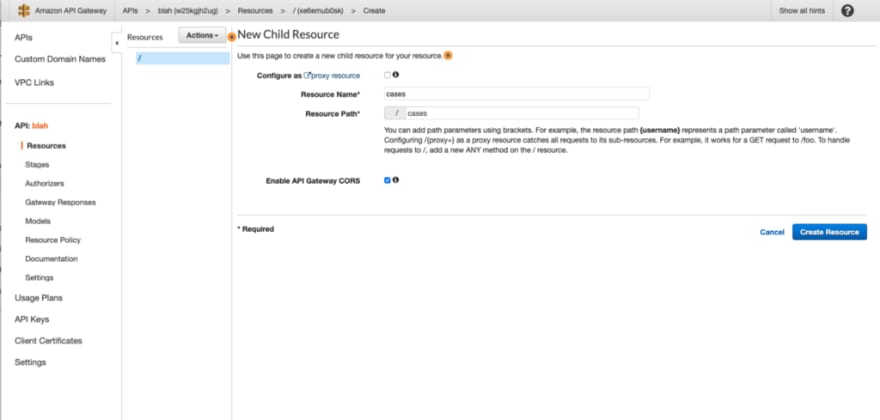
I then chose “ Create method ” from the same dropdown to associate the GET HTTP method with that resource. I was able to point to my Lambda function from the screen that appeared. I used Lambda Proxy Integration to proxy incoming requests straight through to the Lambda function.
Once it was all set up, I saw a no-fuss GET method configuration.

I deployed the API by choosing “ Deploy API ” from the “ Actions ” dropdown, chose a stage name, and added additional stage meta data.

Once I was done deploying the API, I saw a screen that featured a link to it, and was also presented with options for things like caching and client certificates.
If you’re following along because you’re building an API of your own, then you’ll probably want to associate it with a customized domain name — if so, follow the steps in the AWS docs.
Use This as a Starting Point…
I really didn’t do much for this project, and I’m sure you can do much, much more with it. If you’re interested, you can save the data to a DynamoDB table and use that data to build visualizations. You can ditch the scraping altogether and just use the data provided by The COVID Tracking Project (thanks for making me aware of it, Branden). You can build a more engaging application using React or Vue. Whatever you do, though, do it from the safety of your home.
If you end up using the code, or find this post useful, please let me know.





Top comments (0)