
Este é o terceiro artigo de uma série sobre Git. É um assunto extenso que será dividido em:
I - Controle de versão
II - Configuração
III - O que há por baixo dos panos
IV - Comandos mais comuns
V - Fluxo de trabalho
VI - Serviços Git na web
VII - Contribuindo com código aberto
O que há por baixo dos panos
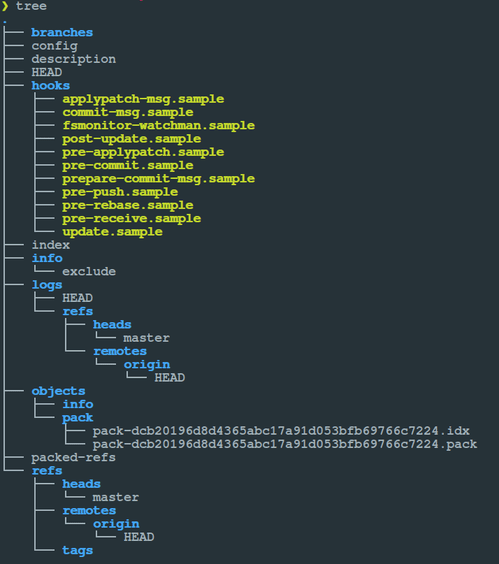
O Repositório do Git é uma pasta, denominada .git/, criada pelo comando git init numa pasta "raiz", em que se quer rastrear mudanças.
O repositório é controlado pelo Git, e raramente o usaremos diretamente. Através de um sistema de arquivos "paralelo" ao do sistema operacional e um banco de dados do tipo "chave-valor", são gerenciados os elementos necessários para o controle de versões.
Cada elemento no repositório tem um identificador único (hash), para manter a integridade dos dados. Ali, os dados serão sempre incluídos (não há exclusão). Pastas e arquivos rastreados, marcações sobre as alterações, metadados e objetos internos, usados pelo Git para cumprir suas funções.
Uma das maiores contribuições do Git, em relação ao controle de versão, é a forma como armazena as alterações, cujas consequências principais são a economia de espaço em disco e a capacidade de "ramificar" facilmente o trabalho, muito menos custoso que as ferramentas anteriores (CVS, SVN).
Commit
Um dos elementos principais do controle de versão são as confirmações de alterações selecionadas, comumente chamadas "commits", que são tratadas pelo Git como instantâneos ou "snapshots", que propiciam a maior parte da funcionalidade da ferramenta.
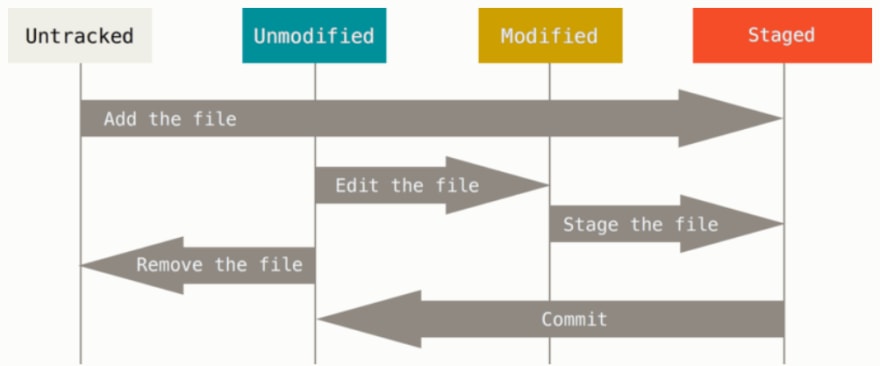
Os arquivos da pasta em que se encontra o repositório, também chamada área de trabalho (working area), podem estar em algum desses estados:
Não rastreado (untracked): enquanto não for adicionado, ao menos uma vez, ao índice de confirmações (Stage index)
Não modificado (unmodified): já é rastreado pelo repositório, mas não teve alteração, do último "commit" até o momento
Modificado (modified): já é rastreado pelo repositório e teve alteração, desde o último "commit"
Confirmado (staged): novo arquivo adicionado ao rastreameno do repositório ou arquivo já rastreado, modificado desde o último "commit" e adicionado ao índice de confirmações (stage index)
Vale ressaltar, aos falantes de português, que a palavra "stage" significa "palco" e "to stage", "encenar". Por que traduzir como "confirmação", ou "confirmado"? "Entrar em cena" é **confirmar a participação do ator no espetáculo**...
O "commit" registra, num formato interno, as confirmações adicionadas ao índice, atribuindo-lhes um identificador único (hash), e associando a uma mensagem fornecida que, geralmente, explica as alterações enviadas ao repositório.
O instantâneo do repositório registra os arquivos não modificados, através do identificador (hash) do último "commit" daquele arquivo, e, dos arquivos modificados, além da última modificação até então, registra "o que" mudou (a diferença entre o anterior e o atual).
A economia de espaço em disco é notória, com essa opção. Não é necessário replicar o arquivo em diferentes instantâneos. Com os identificadores é possível obter um histórico completo do que aconteceu àquele arquivo, e se necessário, reverter a um momento anterior, de qualquer arquivo rastreado.
As alterações armazenadas seguem a seguinte diagramação:
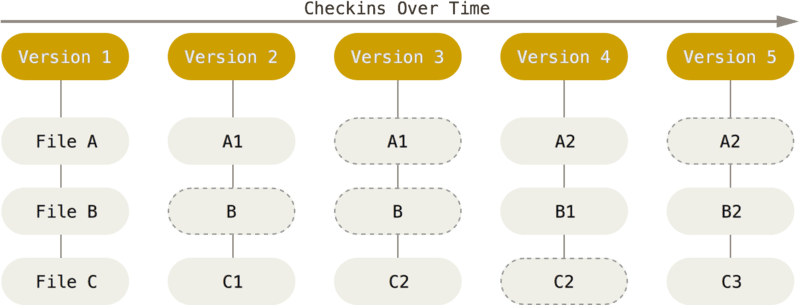
O registro de inclusão, o primeiro commit de um arquivo, vai armazená-lo completo. As alterações seguintes armazenarão apenas o que foi modificado (inclusões, alterações e exclusões de texto, arquivo renomeado, excluído, etc.), sempre através de identificadores únicos (hashs), em cada confirmação.
Ramificações
Outro elemento crucial do Git, favorecido pela arquitetura da ferramenta, é a facilidade de criar ramificações (branches) do trabalho no repositório. Tais ramificações são criadas com o identificador do commit de origem, e terão seus próprios commits, separados do ramo principal.
Novamente, um ganho de espaço em disco considerável. Nas ferramentas anteriores, o custo de uma ramificação era altíssimo (duplicação), além da complexidade para reunir a ramificação ao ramo principal, equivalentemente custosa. Isso foi superado pelo Git e sua arquitetura.
Trabalhar numa ramificação significa ter todos os elementos do ramo principal disponíveis e, sobre eles, construir novidades e alterações sem afetar diretamente o que já existia.
Num determinado momento, em que a ramificação evolui ao ponto em que se quer que faça parte do ramo principal, a reunião (merge) do trabalho é feita de maneira praticamente transparente.
Geralmente, as ramificações são polêmicas entre os desenvolvedores. Entre os que não usam em nenhuma ocasião e os que usam para tudo, há que se ter boa noção de que o trabalho remoto, em equipe, necessita de uma organização ajustada, e que as ramificações ajudam a minimizar a complexidade de tal tarefa.
Distribuído
Outra distinção do Git em relação aos seus concorrentes é a sua natureza distribuída. As operações locais podem ser sincronizadas num repositório remoto.
Essa sincronização, quase sempre, é de ramificações e instantâneos, bem menos custosos para transmissão em rede, por não replicarem os arquivos de forma completa.
Falaremos sobre as ramificações e a distribuição do trabalho, com mais detalhes, em artigo posterior.
Referência:
- Git internals, no Git Book
No próximo artigo, uma geral sobre os comandos mais usados.


Top comments (0)