
As I'm sure many of you have seen, last week Datadog experienced an outage that affected, well, everything. The scale and duration of this outage make it pretty interesting.
DNS?
It's not DNS. There's no way it's DNS.
Overmind doesn't yet have the ability to track DNS changes over time (watch this space) so I don't know, but I'm going to assume given the behaviour and people's reports on Reddit that it's not DNS. I look forward to being proven wrong.
Cloud Outage?
We can tell quite easily if there were any known cloud outages by looking at the status of each of the cloud providers:
- https://health.aws.amazon.com/health/status
- https://azure.status.microsoft/en-gb/status
- https://status.cloud.google.com/
Turns out there weren't any incidents, but just because they weren't acknowledged doesn't mean they didn't exist, so if there was a cloud outage how would it affect Datadog? To work this out we need to have a look at Datadog's architecture. I've added all of their endpoints into Overmind and overlaid the regions and functions in Datadog terminology:
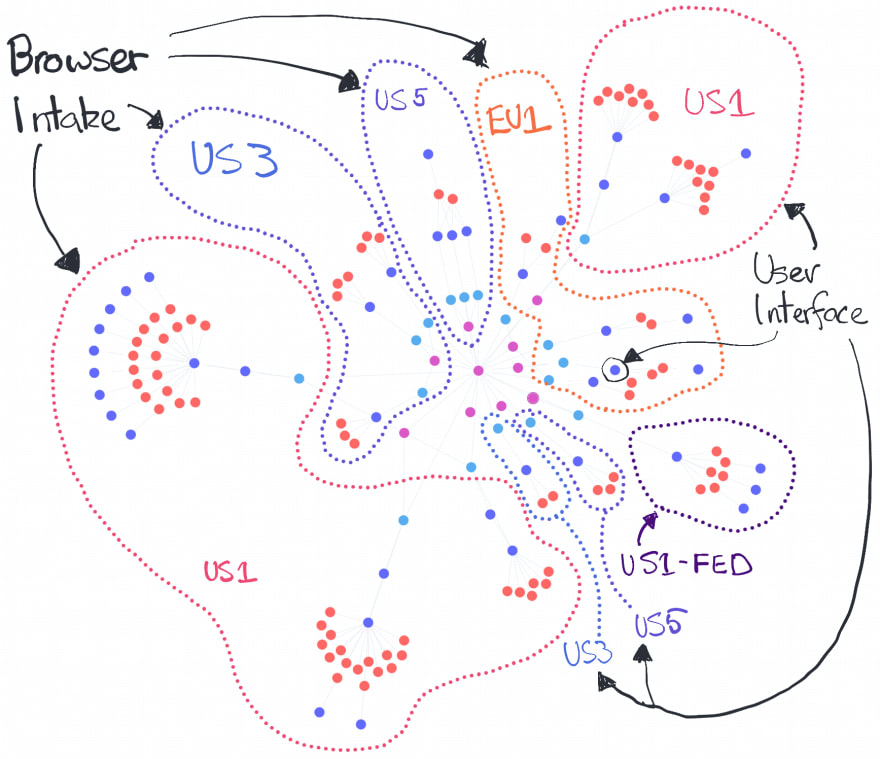
Datadog architecture
We can see that Datadog has a bunch of regions, but how do they relate to cloud providers? Much of this can be worked out using Overmind's built-in reverse-dns queries e.g.

Zoomed in view with reverse-dns results
However others required some sleuthing using whois, Azure IP Lookup and Google Cloud IP ranges. In the end though we get the following:

Full view with cloud details
So the mappings from Datadog terminology to real terminology are:
- US1: AWS (us-east-1)
- US3: Azure (westus2)
- US5: Google cloud (unknown US)
- EU1: Google cloud (unknown EU)
- US1-FED: AWS (us-gov-west-1)
As we can see Datadog's infrastructure is spread across all three major cloud providers, and in the case of AWS and GCP also different regions and likely AZs. From this we can see that at least in theory, there is no cloud outage other than some kind of mass extinction event that could explain the outage we've seen today.
There's an old proverb that says "using multi-cloud for reliability is like riding two horses at once in case one of them dies" and this is a perfect example of that. The reality is that you're probably more likely to make a catastrophic mistake than the cloud providers are, and if straddling all three adds complexity and confusion then it'll only increase your MTTR (mean time to recovery).
Config issue?
Almost certainly. Rumours on Reddit are saying:
Datadog has reported to some customers that it was an OS update that rolled out everywhere that broke networking (see some other comments). This took out important infrastructure like their k8s clusters which run all their workloads.
And I'm inclined to agree that this looks like the most likely culprit. As we've seen time and time again, config changes and the unexpected dependencies between them are almost always at the root of these large outages.
At Overmind we automatically discover all of this for you (with no sidecar containers, agents or libraries) so you can assess the potential blast radius before making a change that brings down production, even if you've never seen that part of the infrastructure before. If you'd like to use it, sign up for our Early Access:
Final Note: There are a lot of smart, tired people working hard to get Datadog back up and running (likely without any Observability tooling...), so please be kind. If you need to vent, take it out on your account manager 😜





Top comments (0)