The rowversion data type is simple to implement, but provides some powerful functionality.
Consider the following, where we create a pair of simple tables.
CREATE TABLE ExampleTable2 (PriKey int PRIMARY KEY, Other uniqueidentifier, VerCol rowversion) ;
GO
insert into ExampleTable2(PriKey, Other)
values
(1, newid()),
(2, newid()),
(3, newid()),
(4, newid()),
(5, newid()),
(6, newid()),
(7, newid()),
(8, newid()),
(9, newid()),
(10, newid())
GO
CREATE TABLE ExampleTable3 (PriKey int PRIMARY KEY, Other uniqueidentifier, VerCol rowversion) ;
GO
insert into ExampleTable3(PriKey, Other)
values
(11, newid()),
(12, newid()),
(13, newid()),
(14, newid()),
(15, newid()),
(16, newid()),
(17, newid()),
(18, newid()),
(19, newid()),
(20, newid())
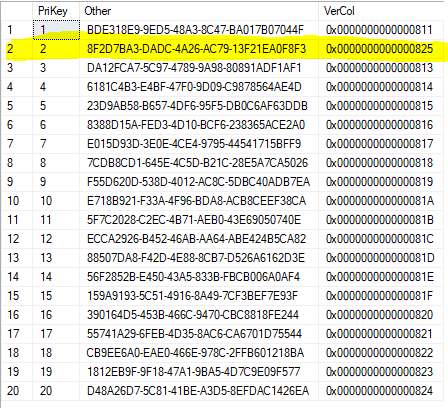
As we can see, the VerCol column is populated with sequential data. Note that the value is sequential across the database, not the table

If we update a row
update ExampleTable2 set Other = NEWID() where PriKey = 2
We can see that the VerCol was automatically updated to the next number in the sequence.
The usefulness is immediateley obvious in two scenarios that come to mind. The first would be a scenario where a user is editing a record that another user is also editing. If User A saves the record, the VerCol will be updated. When User B goes to save the record, we could check the value of this column against the record User B is working with and prevent the save operation with a warning that the data is out of date.
The second scenario is around batch jobs and/or data exports. If CustomerA and CustomerB occasionally ask for exports of data that have changed since they last asked, we can provide the data and the Max(VerCol) at the time the export happens. When they next ask for a new set of data, we can simply add criteria stating where VerCol > 0x00000 00000000824.





Top comments (0)