
This blog post gives an overview of regular expression syntax and features supported by JavaScript. Examples have been tested on Chrome/Chromium console (version 81+) and includes features not available in other browsers and platforms. Assume ASCII character set unless otherwise specified. This post is an excerpt from my JavaScript RegExp book.
Elements that define a regular expression
| Note | Description |
|---|---|
| MDN: Regular Expressions | MDN documentation for JavaScript regular expressions |
/pat/ |
a RegExp object |
const pet = /dog/ |
save regexp in a variable for reuse, clarity, etc |
/pat/.test(s) |
Check if given pattern is present anywhere in input string |
returns true or false
|
|
i |
flag to ignore case when matching alphabets |
g |
flag to match all occurrences |
new RegExp('pat', 'i') |
construct RegExp from a string |
| second argument specifies flags | |
use backtick strings with ${} for interpolation |
|
source |
property to convert RegExp object to string |
| helps to insert a RegExp inside another RegExp | |
flags |
property to get flags of a RegExp object |
s.replace(/pat/, 'repl') |
method for search and replace |
s.search(/pat/) |
gives starting location of the match or -1
|
s.split(/pat/) |
split a string based on regexp |
| Anchors | Description |
|---|---|
^ |
restricts the match to start of string |
$ |
restricts the match to end of string |
m |
flag to match the start/end of line with ^ and $ anchors |
\r, \n, \u2028 and \u2029 are line separators |
|
dos-style files use \r\n, may need special attention |
|
\b |
restricts the match to start/end of words |
| word characters: alphabets, digits, underscore | |
\B |
matches wherever \b doesn't match |
^, $ and \ are metacharacters in the above table, as these characters have special meaning. Prefix a \ character to remove the special meaning and match such characters literally. For example, \^ will match a ^ character instead of acting as an anchor.
| Feature | Description |
|---|---|
pat1|pat2|pat3 |
multiple regexp combined as OR conditional |
| each alternative can have independent anchors | |
(pat) |
group pattern(s), also a capturing group |
a(b|c)d |
same as abd|acd
|
(?:pat) |
non-capturing group |
(?<name>pat) |
named capture group |
. |
match any character except line separators |
[] |
Character class, matches one character among many |
| Greedy Quantifiers | Description |
|---|---|
? |
match 0 or 1 times |
* |
match 0 or more times |
+ |
match 1 or more times |
{m,n} |
match m to n times |
{m,} |
match at least m times |
{n} |
match exactly n times |
pat1.*pat2 |
any number of characters between pat1 and pat2
|
pat1.*pat2|pat2.*pat1 |
match both pat1 and pat2 in any order |
Greedy here means that the above quantifiers will match as much as possible that'll also honor the overall regexp. Appending a ? to greedy quantifiers makes them non-greedy, i.e. match as minimally as possible. Quantifiers can be applied to literal characters, groups, backreferences and character classes.
| Character class | Description |
|---|---|
[ae;o] |
match any of these characters once |
[3-7] |
range of characters from 3 to 7
|
[^=b2] |
negated set, match other than = or b or 2
|
[a-z-] |
- should be first/last or escaped using \ to match literally |
[+^] |
^ shouldn't be first character or escaped using \
|
[\]\\] |
] and \ should be escaped using \
|
\w |
similar to [A-Za-z0-9_] for matching word characters |
\d |
similar to [0-9] for matching digit characters |
\s |
similar to [ \t\n\r\f\v] for matching whitespace characters |
use \W, \D, and \S for their opposites respectively |
|
u |
flag to enable unicode matching |
\p{} |
Unicode character sets |
\P{} |
negated unicode character sets |
| see MDN: Unicode property escapes for details | |
\u{} |
specify unicode characters using codepoints |
| Lookarounds | Description |
|---|---|
| lookarounds | allows to create custom positive/negative assertions |
| zero-width like anchors and not part of matching portions | |
(?!pat) |
negative lookahead assertion |
(?<!pat) |
negative lookbehind assertion |
(?=pat) |
positive lookahead assertion |
(?<=pat) |
positive lookbehind assertion |
| variable length lookbehind is allowed | |
(?!pat1)(?=pat2) |
multiple assertions can be specified next to each other in any order |
| as they mark a matching location without consuming characters | |
((?!pat).)* |
Negates a regexp pattern |
| Matched portion | Description |
|---|---|
m = s.match(/pat/) |
assuming g flag isn't used and regexp succeeds, |
| returns an array with matched portion and 3 properties | |
index property gives the starting location of the match |
|
input property gives the input string s
|
|
groups property gives dictionary of named capture groups |
|
m[0] |
for above case, gives entire matched portion |
m[N] |
matched portion of Nth capture group |
s.match(/pat/g) |
returns only the matched portions, no properties |
s.matchAll(/pat/g) |
returns an iterator containing details for |
| each matched portion and its properties | |
| Backreference | gives matched portion of Nth capture group |
use $1, $2, $3, etc in replacement section |
|
$& gives entire matched portion |
|
$` gives string before the matched portion |
|
$' gives string after the matched portion |
|
use \1, \2, \3, etc within regexp definition |
|
$$ |
insert $ literally in replacement section |
$0N |
same as $N, allows to separate backreference and other digits |
\N\xhh |
allows to separate backreference and digits in regexp definition |
(?<name>pat) |
named capture group |
use \k<name> for backreferencing in regexp definition |
|
use $<name> for backreferencing in replacement section |
Regular expression examples
-
testmethod
> let sentence = 'This is a sample string'
> /is/.test(sentence)
< true
> /xyz/.test(sentence)
< false
> if (/ring/.test(sentence)) {
console.log('mission success')
}
< mission success
-
new RegExp()constructor
> new RegExp('dog', 'i')
< /dog/i
> new RegExp('123\\tabc')
< /123\tabc/
> let greeting = 'hi'
> new RegExp(`${greeting.toUpperCase()} there`)
< /HI there/
- string and line anchors
// string anchors
> /^cat/.test('cater')
< true
> ['surrender', 'newer', 'door'].filter(w => /er$/.test(w))
< ["surrender", "newer"]
// use 'm' flag to change string anchors to line anchors
> /^par$/m.test('spare\npar\nera\ndare')
< true
// escape metacharacters to match them literally
> /b\^2/.test('a^2 + b^2 - C*3')
< true
-
replacemethod and word boundaries
> let items = 'catapults\nconcatenate\ncat'
> console.log(items.replace(/^/gm, '* '))
< * catapults
* concatenate
* cat
> let sample = 'par spar apparent spare part'
// replace 'par' only at the start of word
> sample.replace(/\bpar/g, 'X')
< "X spar apparent spare Xt"
// replace 'par' at the end of word but not whole word 'par'
> sample.replace(/\Bpar\b/g, 'X')
< "par sX apparent spare part"
- alternations and grouping
// replace either 'cat' at start of string or 'cat' at end of word
> 'catapults concatenate cat scat'.replace(/^cat|cat\b/g, 'X')
< "Xapults concatenate X sX"
// same as: /\bpark\b|\bpart\b/g
> 'park parked part party'.replace(/\bpar(k|t)\b/g, 'X')
< "X parked X party"
-
MDN: Regular Expressions doc provides
escapeRegExpfunction, useful to automatically escape metacharacters.- See also XRegExp utility which provides XRegExp.escape and XRegExp.union methods. The union method has additional functionality of allowing a mix of string and RegExp literals and also takes care of renumbering backreferences.
> function escapeRegExp(string) {
return string.replace(/[.*+\-?^${}()|[\]\\]/g, '\\$&')
}
> function unionRegExp(arr) {
return arr.map(w => escapeRegExp(w)).join('|')
}
> new RegExp(unionRegExp(['c^t', 'dog$', 'f|x']), 'g')
< /c\^t|dog\$|f\|x/g
- dot metacharacter and quantifiers
// matches character '2', any character and then character '3'
> '42\t33'.replace(/2.3/, '8')
< "483"
// 's' flag will allow line separators to be matched as well
> 'Hi there\nHave a Nice Day'.replace(/the.*ice/s, 'X')
< "Hi X Day"
// same as: /part|parrot|parent/g
> 'par part parrot parent'.replace(/par(en|ro)?t/g, 'X')
< "par X X X"
> ['abc', 'ac', 'abbc', 'xabbbcz'].filter(w => /ab{1,4}c/.test(w))
< ["abc", "abbc", "xabbbcz"]
-
matchmethod
// entire matched portion
> 'abc ac adc abbbc'.match(/a(.*)d(.*a)/)[0]
< "abc ac adc a"
// matched portion of 2nd capture group
> 'abc ac adc abbbc'.match(/a(.*)d(.*a)/)[2]
< "c a"
// get location of matching portion
> 'cat and dog'.match(/dog/).index
< 8
// get all matching portions with 'g' flag
// no properties or group portions
> 'par spar apparent spare part'.match(/\bs?par[et]\b/g)
< ["spare", "part"]
// useful for debugging purposes as well before using 'replace'
> 'that is quite a fabricated tale'.match(/t.*?a/g)
< ["tha", "t is quite a", "ted ta"]
-
matchAllmethod
// same as: match(/ab*c/g)
> Array.from('abc ac adc abbbc'.matchAll(/ab*c/g), m => m[0])
< ["abc", "ac", "abbbc"]
// get index for each match
> Array.from('abc ac adc abbbc'.matchAll(/ab*c/g), m => m.index)
< [0, 4, 11]
// get only capture group portions as an array for each match
> let s = 'xx:yyy x: x:yy :y'
> Array.from(s.matchAll(/(x*):(y*)/g), m => m.slice(1))
< (4) [Array(2), Array(2), Array(2), Array(2)]
0: (2) ["xx", "yyy"]
1: (2) ["x", ""]
2: (2) ["x", "yy"]
3: (2) ["", "y"]
length: 4
__proto__: Array(0)
- function/dictionary in replacement section
> function titleCase(m, g1, g2) {
return g1.toUpperCase() + g2.toLowerCase()
}
> 'aBc ac ADC aBbBC'.replace(/(a)(.*?c)/ig, titleCase)
< "Abc Ac Adc Abbbc"
> '1 42 317'.replace(/\d+/g, m => m*2)
< "2 84 634"
> let swap = { 'cat': 'tiger', 'tiger': 'cat' }
> 'cat tiger dog tiger cat'.replace(/cat|tiger/g, k => swap[k])
< "tiger cat dog cat tiger"
-
splitmethod
// split based on one or more digit characters
> 'Sample123string42with777numbers'.split(/\d+/)
< ["Sample", "string", "with", "numbers"]
// include the portion that caused the split as well
> 'Sample123string42with777numbers'.split(/(\d+)/)
< ["Sample", "123", "string", "42", "with", "777", "numbers"]
// split based on digit or whitespace characters
> '**1\f2\n3star\t7 77\r**'.split(/[\d\s]+/)
< ["**", "star", "**"]
// use non-capturing group if capturing is not needed
> '123handed42handy777handful500'.split(/hand(?:y|ful)?/)
< ["123", "ed42", "777", "500"]
- backreferencing with normal/non-capturing/named capture groups
// remove consecutive duplicate words separated by space
// use \W+ instead of space to cover cases like 'a;a<-;a'
> 'aa a a a 42 f_1 f_1 f_13.14'.replace(/\b(\w+)( \1)+\b/g, '$1')
< "aa a 42 f_1 f_13.14"
// add something around the entire matched portion
> '52 apples and 31 mangoes'.replace(/\d+/g, '($&)')
< "(52) apples and (31) mangoes"
// duplicate first field and add it as last field
> 'fork,42,nice,3.14'.replace(/,.+/, '$&,$`')
< "fork,42,nice,3.14,fork"
// use non-capturing groups when backreferencing isn't needed
> '1,2,3,4,5,6,7'.replace(/^((?:[^,]+,){3})([^,]+)/, '$1($2)')
< "1,2,3,(4),5,6,7"
// named capture groups, same as: replace(/(\w+),(\w+)/g, '$2,$1')
> 'good,bad 42,24'.replace(/(?<fw>\w+),(?<sw>\w+)/g, '$<sw>,$<fw>')
< "bad,good 24,42"
- examples for lookarounds
// change 'foo' only if it is not followed by a digit character
// note that end of string satisfies the given assertion
// note that 'foofoo' has two matches
> 'hey food! foo42 foot5 foofoo'.replace(/foo(?!\d)/g, 'baz')
< "hey bazd! foo42 bazt5 bazbaz"
// change whole word only if it is not preceded by : or --
> ':cart apple --rest ;tea'.replace(/(?<!:|--)\b\w+/g, 'X')
< ":cart X --rest ;X"
// extract digits only if it is preceded by - and followed by , or ;
> '42 foo-5, baz3; x83, y-20; f12'.match(/(?<=-)\d+(?=[;,])/g)
< ["5", "20"]
// words containing all vowels in any order
> let words = ['sequoia', 'questionable', 'exhibit', 'equation']
> words.filter(w => /(?=.*a)(?=.*e)(?=.*i)(?=.*o).*u/.test(w))
< ["sequoia", "questionable", "equation"]
// replace only 3rd occurrence of 'cat'
> 'cat scatter cater scat'.replace(/(?<=(cat.*?){2})cat/, 'X')
< "cat scatter Xer scat"
// match if 'do' is not there between 'at' and 'par'
> /at((?!do).)*par/.test('fox,cat,dog,parrot')
< false
Debugging and Visualization tools
As your regexp gets complicated, it can get difficult to debug if you run into issues. Building your regexp step by step from scratch and testing against input strings will go a long way in correcting the problem. To aid in such a process, you could use various online regexp tools.
regex101 is a popular site to test your regexp. You'll have first choose the flavor as JavaScript. Then you can add your regexp, input strings, choose flags and an optional replacement string. Matching portions will be highlighted and explanation is offered in separate panes. There's also a quick reference and other features like sharing, code generator, quiz, etc.

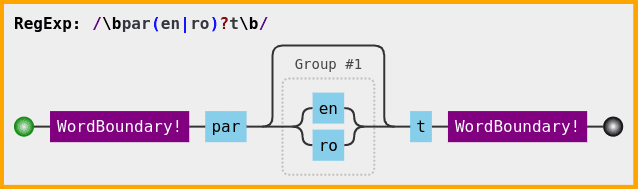
Another useful tool is jex: regulex which converts your regexp to a rail road diagram, thus providing a visual aid to understanding the pattern.
JavaScript RegExp book
Visit my repo learn_js_regexp for details about the book I wrote on JavaScript regular expressions. The ebook uses plenty of examples to explain the concepts from the basics and includes exercises to test your understanding. The cheatsheet and examples presented in this post are based on contents of this book.





Top comments (1)
A long article, but very impressive. Thanks you!