
Some of you might remember the classic traveling salesman problem presented in our undergrad days: "Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?" For those of you who filed this one away (in the bin) immediately upon graduation, “it is an NP-hard problem in combinatorial optimization, important in theoretical computer science and operations research.” Or in layman’s terms, it’s one of the hardest, most examined problems in optimization, and has a vast number of applications from the manufacturing of microchips to DNA sequencing. (Thank you for the refresher, Wikipedia.)

Here at Lob, we tackle this problem every single day in its purest form. As an extension of our direct mail automation, we have a network of print partners. That is, after we digitally generate the physical mailpieces, we route them to our print partners, who then hand them off to the USPS for delivery. Time-in-transit, or the time it takes for a mailpiece to travel from where it enters the mail stream to delivery, is of utmost concern.
So just like the traveling salesman problem we ask: is there a way to optimize the route? Lob has developed a routing algorithm that prioritizes printers who are closest to the destination of the mailpiece. In theory, this should cut down transit time…right?
As it happens, in a twist worthy of M. Night Shyamalan, our current approach may not be the best one. Only time and more performance results will tell, but sometimes the most obvious solution isn't necessarily the best one. Sometimes it takes creative thinking and data analysis to unearth surprising improvements.

Our project began on a whim. Like many companies, Lob has databases full of information on the mailpieces we send, but like many companies which aren't strictly machine learning-oriented, we've conducted very little analysis on this data using machine learning tools.
There's a conception that machine learning is somehow inaccessible, that it needs expert guidance and a dedicated ML team to really implement. Wrong! As someone who has taken a couple of ML classes, but is still an amateur, I saw untapped potential for improvements to a number of our systems, foremost being our routing engine. Is it possible, I wondered, that we were taking a less efficient approach to routing our mail? Would data analysis tell a different story than the one we had assumed would hold true?
The Data
It’s helpful to set baselines around the context of the data that we are talking about, and I leaned heavily on Lob Business Analyst, Anisha Biswaray. The USPS mail distribution network splits nearly 42,000 destination ZIP codes in the US among various fixed hierarchies and webs. Millions of mailpieces move through USPS systems every day, and each mailpiece can generate up to 105 different operation codes that translate to different business logic around what stage of the mailing process that mailpiece is in. As you can imagine, this results in particularly messy data.

We brainstormed to pick up the highest-fidelity signals that we could from these messy operation codes, focusing specifically on the mail entry and exit signals that help us to translate to a simple metric. What is the transit time for a given mailpiece, when it goes through a particular branch of the network? We calculated the difference between the earliest and the latest timestamps for each mailpiece in order to figure out this transit time, and that was our target metric.
The Model
Once we had determined the shape of the data and the features we should focus on, we set out to create a model. (There is a wealth of ML tools available across programming languages like Python and Julia.) We chose scikit-learn, one of the most popular ML libraries around, and plugged the data into a random forest regression. (Say what? Here’s a quick and dirty guide to random forest regression.) As input, we used the ZIP codes of the print partner and the destination of the mailpiece. Our output target was the metric we had calculated during pre-processing: the difference in days between the earliest and latest USPS events recorded for each mailpiece (the mailpiece's time in transit).
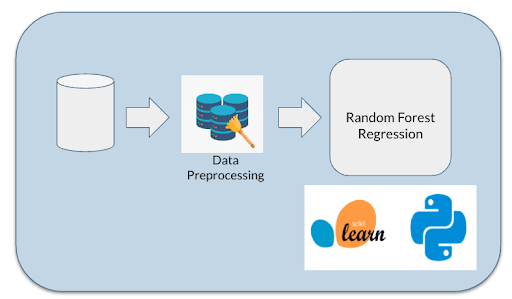
The Results
Even just using 50% of the data (about 500K data points), the difference between the model's predictions and the average error calculated using non-machine learning methods was astonishing: The error margin dropped from 1.4 three days to 0.86. Print partners which were further geographically from the destinations sometimes yielded lower times in transit, a conclusion which may not seem intuitive, but one which accounts for historical data in a way our current routing algorithm does not. This approach can also account for seasonal fluctuations in a way that geolocation doesn't, because those seasonal patterns will show up in the historical data.(Example: while one print partner might be closer to a destination, it routinely gets flooded around Christmas, so it's actually faster to send it to another print partner who’s further away.) These preliminary numbers justify our decision to analyze existing historical data, even though our routing algorithm already seemed to be optimally configured according to common sense.

This project began as something shockingly simple. No in-depth knowledge of ML was required. We didn't have to do any calculus or write our own custom model. The most challenging part was deciding which data features to use. This baseline project was finished in a matter of two days during a company hackathon, which means our efforts can—and should—easily be replicated.
In a digital world, packed with data about practically anything, a company doesn't need to have an ML focus, a dedicated ML department, or even an ML expert in order to make breakthroughs and improvements to their processes using machine learning tools. All you really need to do is pull up scikit documentation and put your data to work.
Content based on a presentation by Aditi Ramaswamy and Anisha Biswaray at Conf42-ML. Special thanks to Luke Birdeau, Staff Engineer at Lob, for his consult.





Top comments (0)