Understanding and Optimizing Python multi-process Memory Management
This post will focus on lowering your memory usage and increase your IPC at the same time
This blog post will focus on POSIXoriented OS like Linux or macOS
To avoid the GIL bottleneck, you might have already used multi-processing with python, be it using a pre-fork worker model (more on that here), or just using the multiprocessingpackage.
What that does, under the hood, is using the OS fork() function that will create a child process with an exact virtual copy of the parent’s memory.
The OS is really clever while doing this since it doesn’t copy the memory right away. Instead, it will expose it to each process as its own isolated memory, keeping all the previous addresses intact.

This is possible thanks to the concept of virtual memory.
Let’s take a small detour just to refresh your memory on some of the underlying concepts, feel free to skip this section if it’s old news to you.
So how can you have two processes with the exact same memory addresses holding different values?
Your process does not interact directly with your computer RAM, in fact, the OS abstracts memory through a mechanism called Virtual Memory. This has many advantages like:
- You can use more memory than the available RAM in your system (using disk)
- Memory address isolation and protection from other processes
- Contiguous address space
- No need to manage shared memory directly
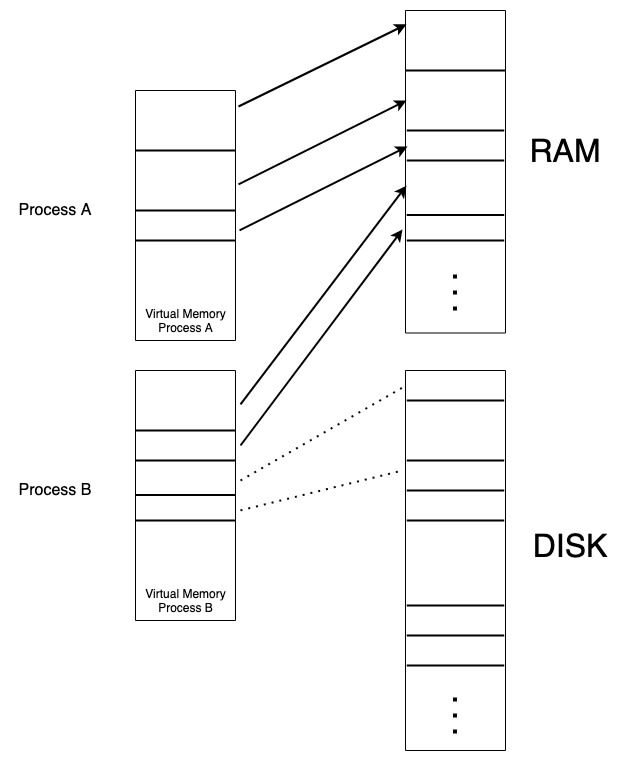
In the above picture, you can see two independent processes that have their isolated memory space.
Each process has its contiguous address space and does not need to manage where each page is located.
You probably noticed some of the memory pages are located on disk. This can happen if your process never had to access that page since it was started (the OS will only load pages into RAM when a process needs them) or they were evicted from RAM because it needed that space for other processes.
When the process tries to access a page, the OS will serve it directly from RAM if it is already loaded or fetch it from disk, load it into RAM and then serve it to the process, with the only difference being the latency.
Sorry for the detour, now let’s get back to our main topic!
After you fork(), you end up with two processes, a child and a parent that share most of their memory until one of them needs to write to any of the shared memory pages.
This approach is called copy on write (COW), and this avoids having the OS duplicating the entire process memory right from the beginning, thus saving memory and speeding up the process creation.
COW works by marking those pages of memory as read-only and keeping a count of the number of references to the page. When data is written to these pages, the kernel intercepts the write attempt and allocates a new physical page, initialized with the copy-on-write data. The kernel then updates the page table with the new (writable) page, decrements the number of references, and performs the write.
What this means is that one easy way to avoid bloating your memory is to make sure you load everything you intend to share between processes into memory before you fork().
If you’re using gunicorn to serve your API, this means using the preload parameter for example.
Not only you can avoid duplicating memory but it will also avoid costly IPC.
Loading shared read-only objects before the fork() works great for “well behaved” languages since those object pages will never get copied, unfortunately with python, that’s not the case.
One of python’s GC strategies is reference counting and python keeps track of references in each object header.
What this means in practice is that each time you read said object, you will write to it.
Be it using gunicorn with the preload parameter or just loading your data and then forking using the multiprocessing package, you’ll notice that, after an amount of time, your memory usage will bloat to be almost 1:1 with the number of processes. This is the work of the GC.
I have some good and bad news… you’re not alone in this and it will be a bit more trouble but there are some workarounds to the issue.
Let’s establish a baseline and run some benchmarks first, and then explore our options. To run these benchmarks, I created a small Flask server with gunicorn to fork the process into 3 workers. You can check the script here.

In the above chart, gunicorn will fork before running the server code, this means each worker will run this script:
self.big_data = [item _for_ item _in_ range(10000000)]
As we can see, memory usage grows linearly with each worker.

In the above chart, since I’m using the preload option, gunicorn will load everything before forking. We can see COW in action here since the memory usage stays constant.
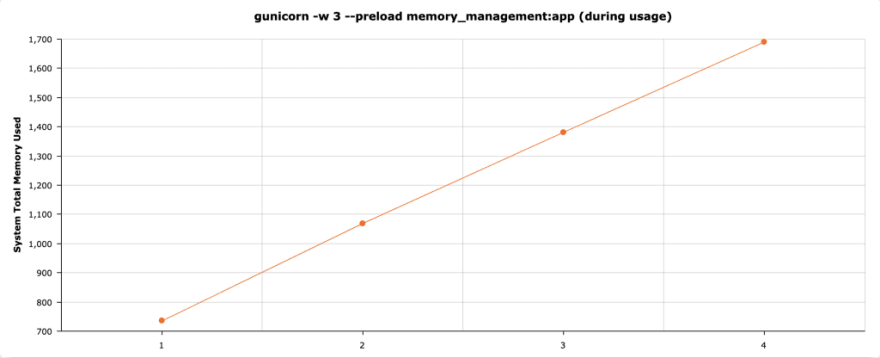
Unfortunately, as we can see here, as soon as each worker needs to read the shared data, GC will try to write into that page to save the reference count, provoking a copy on write.
In the end, we end up with the same memory usage as if we didn’t use the preload option!
Ok, we have our baseline, how can we improve?
Using joblib
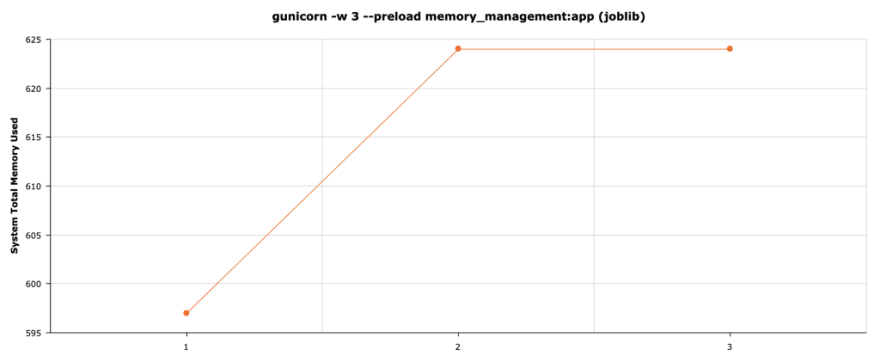
Joblib is a python library that is mainly used for data serialization and parallel work. One really good thing about it is that it enables easy memory savings since it won’t COW when you access data loaded by this package.
_import_ joblib
# previously created with joblib.dump()
self.big_data = joblib.load('test.pkl') # big_data is a big list()
Using numpy
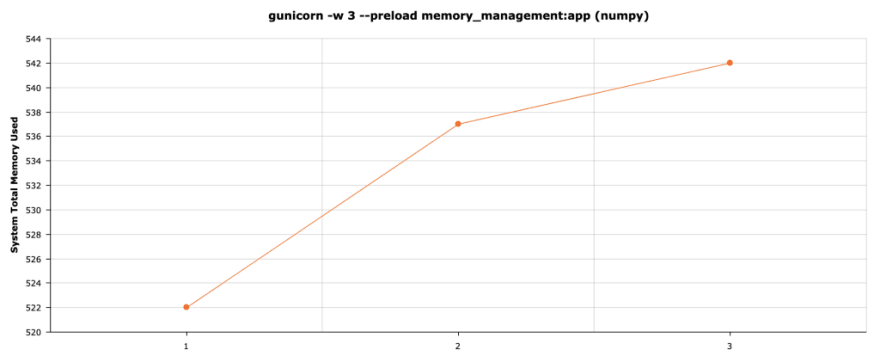
If you’re doing data science, I have really good news for you! You get memory savings for “free” just by using numpy data structures. And this includes if you use pandas or another library as long as the inner data structure is a numpy array.
The reason for this is how they manage memory. Since this package is basically C with python bindings, they have the liberty (and responsibility) of managing everything without the interference of cpython.
They made the clever choice of not saving the reference counts in the same pages those large data structures are kept, avoiding COW when you access them.
_import_ numpy _as_ np
self.big_data = np.array([[item, item] _for_ item _in_ range(10000000)])
Using mmap

mmap is a POSIX-compliant Unix system call that maps files or devices into memory. This allows you to interact with huge files that exist on disk without having to load them into memory as a whole.
Another big advantage is that you can even create a block of shared “unmanaged” memory without a file reference passing -1 instead of a file path like this:
_import_ mmap
mmap.mmap(-1, length=....)
Another great advantage is that you can write to it as well without incurring COW. As long as you deal with concurrency, it is an efficient way to share memory/data between processes, although it’s probably easier/safer to use multiprocessing.shared_memory.
How does this all sound? Is there anything you’d like me to expand on? Let me know your thoughts in the comments section below (and hit the clap if this was useful)!
Conclusions
- Python will generally copy shared data to each process when you access it
- “Preload” is a great way to save memory if you need to share a read-only big data structure in your API
- To avoid COW when you read data, you’ll need to use joblib, numpy, mmap, shared_memory or similar
- Sharing data instead of communicating data between processes can save you a lot of latency
Stay tuned for the next post. Follow so you won’t miss it!





Top comments (0)