
Model evaluation is a critical, yet often under looked, step in data science. Much time is dedicated to obtaining, cleaning, and analyzing large amounts of structured and unstructured data, in order to then build models that may generate new insights. In the rush to extract value from data and to put such insights to work in a fast-paced world, the process of evaluating the performance of the model can be dismissed altogether. Recent examples showcase the need for model evaluation. Most notably, Zillow shut down its home buying business after it paid too much for houses by relying on an algorithm that could not accurately forecast prices during a period of rapid price changes. The algorithm did not perform well with new, changing data.
This blog post will highlight how to incorporate evaluation into modeling time series--such as real estate prices, FX rates, stock prices, retail sales, temperature readings, and numbers of subscribers--in Python.
Train-test splits
The first step is to split the data set into a training subset (to train the model) and a testing subset (to test the trained model). This is referred to as a 'train-test split', where the training data typically accounts for 80% of the sample and the test data accounts for 20% of the sample. In non-time series machine learning, the train-test split function partitions the data randomly.
With time series, however, the data is not split into random subsets. Rather, the testing subset is comprised of the observations towards the end of the dataset. For example, in a dataset with 60 records (let's say these are months), the training set would be comprised of the first 48 months and the test set would be comprised of the last 12 months. The test set is sometimes described as the 'hold-out' set since this data is withheld from the dataset that is used for fitting the model. Importantly, a model should not be trained on test data.

A function can be defined in Python to perform such a split on multiple time series, and the slicing notation can be used to slice the dataset accordingly.
# Define function to apply train_test_split to all selected dfs
def tt_split(df_list, names):
tts_list = []
for i, df in enumerate(df_list):
train_data = df[:-12] #all data except last 12 months
test_data = df[-12:] #last 12 months of data
tts_list.extend([train_data, test_data])
print(names[i],':', df.shape, ' // Train: ', train_data.shape,
'Test: ', test_data.shape)
return tts_list #return list of train, test dfs
Once the data has been split into training and testing subsets, the developed model will be fit to the training set. Evaluation metrics relevant to the use case can then be assessed. Residuals are calculated on the training set, and forecasts are calculated on the test set.
Workflow visualization
A simplified workflow to develop a time series model could look like this, according to Google's Machine Learning guide:
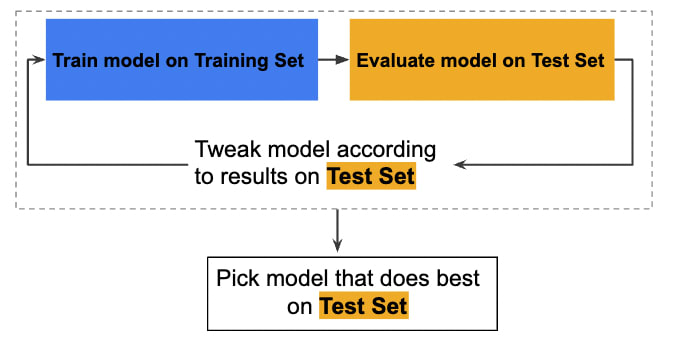
Benchmark models
Another key step in the model validation process is to build a baseline (ie, benchmark) model followed by iterative modeling with different assumptions, inputs, hyper-parameters and even with varying models to compare results. At this point, models can be compared on relevant evaluation metrics (such as RMSE and AIC) and how well the model generalizes to new data, which is known as over- and under-fitting. This matters because models are developed on sample data, which is usually not fully representative of the new data that the model will encounter in the real world. The model should ultimately learn well enough that it can be applied to examples it did not see during the training phase.
Conclusion
Incorporating model evaluation practices--through train-test splits, building benchmark models, and iterating on them--is a good practice that should be part of every time series analysis, especially when such models inform decision-making.




Top comments (0)