Hi, this is the first article from Ath, hope it is not boring or duplicate with someone’s work =]
Lately, I am working on a patient information system revamp project (from MS Access to web form). The input form developed using React.JS, accepts data type ranging from number to string. Numbers should have no concern, just be aware of the range, or type, i.e. the min, max, positive, negative, integer, float, etc. One thing I want to enhance is the user experience on the string input.
After reviewing data in the as-is database, I found that there are typos, different patterns/formats referring to the same thing, this makes the users confused or makes the data mining complicated.
For example, the existing DB shows something like ar-8, AR -8 , AR- 8, etc. Since they are from the same column, these “variances" have a very high chance that means the same thing. SQL servers do have REGEX to find those variances , but it needs some time to optimize.
My idea is simple and straight, similar to google search box, when you type one word, the data-list returns word(s) that match with the input string. This can hopefully solve the formatting issue and suggests word(s) for users to reduce their typing time.
However, the suggestion approach works with limitations.
For the input box, modern browsers or mobile devices record what you input. If the hit rate of a typo is high, this will be used as a suggestion, this will be a problem.
On the other hand, if the project uses a static suggestion list, we can ensure the suggested list is valid at the time when constructed. However, with the development of business and the growth of data-size, the suggestion list cannot predict the input of users. Finally, the data list can have just a little help with the data input.
As a result, I am designing a mechanism to build a word-suggestion list with valid words. This is separated into 2 phases, the first phase is to find a suggestion list and to build an initial list (as of today, it is finished with the result below). And also, with the result, draws the blueprint which can be used in the phase II. In the second phase, I want to automate the first phase to make the list growth dynamically, also with additional word validity checks.
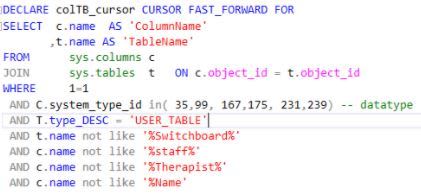
In phase I, since the data-size is not gigantic, I can use simple SQL with acceptable performance. I wrote a SQL to find words with a high hit rate, this list is the candidate of suggested words. This SQL contains 3 parts:
1) extract the table schema definition on certain data type to extract target data
2) fetch data in the tables on value count >1
3) post-process the extracted data
To construct these 3 steps, repetitive execute-review-tuning performed.
The data column from this phase is considered as the blueprint of phase II.
Finding of the phase I
For 1), awaring the data privacy , derived value , “repetitive value” were found. After few cycles, I decide not to extract those columns
For 3), repetitive patterns observed. So, I applied filters not to show irrelevant patterns, they are date (in string), prefix of certain value, or some path.
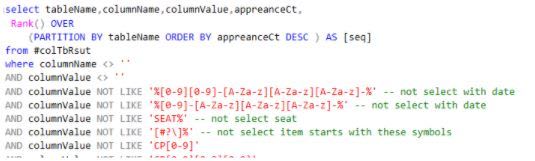
After reviewing the list, there are few findings:
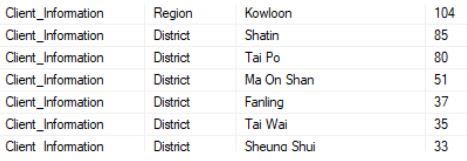
*I found a high frequency of district and sub-district in a column
**For this, I use the government district and sub-district list as reference, however, there are suburbs which are not covered. Work still needs to add more suburbs.
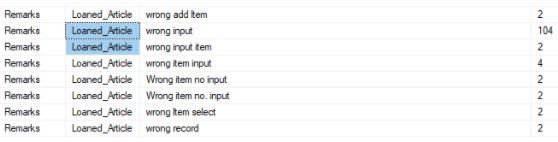
I found the phrases “wrong input”, “wrong item input”, etc in a column
**I think the original form design can explain this pattern. Since the form only shows a part number, it is hard for an ordinary user to imagine what the number presents. As a remedy, I redesign the form by adding more descriptive fields, hopes to lower the wrong input rate by illustrating more info to user
Color “PURPLE”, “GREEN”, “Yellow”is frequent in a column
**For this, just add static color in that column

Different pattern with same meaning
**For this, just add static suggestion in that column

The next move…
In phase II, I want to automate the above. However, to tackle the typo issue, i have to check the word spelling.
A scheduled job needs to be set to extract the new frequent words in the database periodically (say one month).
To tackle with typo, another job reads the raw result from the 1st step, and query the dictionary API. If the word is spelled incorrectly either drop it or takes the word suggestion (if the API provides such capability).
Record the added suggested words, review periodically, tune the SQL, ensuring the quality.





Top comments (0)