
Este post faz parte da seguinte série sobre estudo de HTTP2 e protocolos binários:
Recomendações (Opcional)
Listo aqui algumas recomendações que podem ajudar vocês:
- Se você usa Windows, eu recomendo que usem o WSL2 com alguma distro de sua preferência, caso goste ou queira testar o Ubuntu, só seguir este artigo, que possui um passo a passo bem intuitivo;
- SDKMAN para gerenciar várias versões de vários softwares, dentre eles JDK, e até mesmo alterar qual versão quer usar. Aproveite e já instale o Java 11;
- a IDE eu não vou opinar, pois vai muito de gosto pessoal, mas eu uso VSCode com algumas extensões do Spring, Java e para o WSL.
Criando aplicação Java + Spring Boot
Como iremos criar uma aplicação Spring Boot, obviamente iremos usar o site oficial para gerar o boilerplate inicial e já configurado com algumas dependências. Existe também o CLI e plugins em algumas IDEs que fazem o mesmo, mas o site acredito que seja o mais atualizado.
Nesta parte é importante apenas selecionar a opção "Java 11" e incluir as seguintes dependências:
- Spring Web;
- Spring Boot Actuator;
- Prometheus.
Mas porquê adicionar essas dependências?

Estas dependências servem respectivamente para criar uma aplicação com um servidor web embarcado que iremos expor a API, seguindo de outras dependências que irão expor métricas desta aplicação.

E agora sem mais delongas.
Criando a API
Como dito no post anterior, iremos usar a lib Java Faker e o código está representado abaixo.


Ô amigão, o código fonte tá como imagem. Tu tá de brinqueichon uite me?

Na seção final irei deixar o link do repositório no Github.

Habilitando HTTP2
Como já é hábito (cof cof, ou pelo menos a gente tenta XD), na hora de verificar como configurar determinada funcionalidade em um framework / biblioteca / ferramenta vamos de documentação oficial e na seção específica que trata do assunto.
Como lido na documentação e trazendo de forma bem curta e ligeira, para habilitar HTTP2 será necessário também configurar o TLS desta aplicação, que por sua vez será necessário um certificado, donde usaremos um auto-assinado conforme abaixo.
keytool -genkeypair -alias spring-http2 -keyalg RSA -keysize 2048 -storetype PKCS12 -keystore spring-http2.p12 -validity 3650
E use a senha passwd quando solicitado e copiar o arquivo criado para a pasta src/main/resources/keystore na aplicação.
PS.: Estamos colocando o certificado dentro da aplicação apenas para fins de simplicidade e demonstração, mas o mesmo deveria estar externalizado.
Abaixo as propriedades da aplicação.

A última propriedade é referente a exposição de endpoints do actuator, que para efeitos de simplicidade foram expostos todos para que o Prometheus possa fazer o scrapper destes dados e assim termos monitoramento da aplicação.
As demais propriedades são relacionadas a HTTP2, HTTPS e certificado.
Caso queira testar a aplicação, pode-se usar o Maven wrapper que vem junto ao projeto do Spring e rodar a aplicação da seguinte forma:
./mvnw spring-boot:run
Depois pode-se acessar os seguintes endpoints:
Beleza galera, agora foi a parte demorada, agora vai ser à jato.

Instalar ferramentas - Prometheus, Grafana, InfluxDB1 e k6
Vamos rever a nossa arquitetura de benchmark que foi apresentada no post anterior, mas está logo aqui abaixo para facilitar o rolê.

Vamos instalar o Prometheus, Grafana, InfluxDB1 e k6 e aqui não tem muito mistério pessoal, iremos usar as instruções de instalação e execução de acordo com o site de cada ferramenta conforme os links abaixo:

Configurando as ferramentas
Com todas as ferramentas instaladas, agora iremos verificar como configurar cada uma delas.
Configurando a aplicação
Como temos 2 profiles, então teremos que iniciar a aplicação de forma diferente a cada teste:
- 2cpu, 2Gb RAM - cujo comando será:
./mvnw spring-boot:run -Dspring-boot.run.jvmArguments="-XX:ActiveProcessorCount=2 -Xmx2g -Xms2g"
- 4cpu, 4Gb RAM - cujo comando será:
./mvnw spring-boot:run -Dspring-boot.run.jvmArguments="-XX:ActiveProcessorCount=4 -Xmx4g -Xms4g"
Foi incluído o trecho de código abaixo para exibir esses valores de CPU e memória durante a inicialização da aplicação, apenas para confirmar:

Configurando o Prometheus
No caso do prometheus, precisa apenas iniciar o serviço com um arquivo de configuração para que o mesmo possa ler as métricas da aplicação. Segue abaixo um exemplo de scrapper de métricas para esta aplicação em específico.

Configurando InfluxDB1
Nada aqui, apenas iniciar o serviço.
Configurando Grafana
Inicie o serviço do Grafana, abra sua interface web, faça login com tanto usuário e senha admin e em seguida vamos configurar 2 itens: data sources e dashboards.
Data sources
Para incluir os data sources, pode-se na tela inicial, vai ter um card para adicionar o data source ou pode-se ir no menu lateral.
Para o Prometheus basta colocar a URL do mesmo http://localhost:9090/ e se o serviço estiver rodando, pode salvar e testar.
Para o InfluxDB é necessário colocar a URL do mesmo http://localhost:8086 e informar no campo mais abaixo Database o valor myk6db, cujos valores serão utilizados na próxima seção para o k6 fazer a ingestão das métricas.
Dashboards
Quando estava visitando artigos e a própria documentação do Grafana, notei que existe lá no site oficial uma seção onde as pessoas compartilham dashboards, então usando o conceito de "Não reinvente a roda", então pensei: "deixa eu ver se num já tem um giga painel completão de tudo".
E a grande motivação de eu ter usado o InfluxDB1 foi justamente por ter encontrado um dashboard pronto pro k6 de id 4411. Quanto ao Spring Boot também achei um muito bacana de id 14430.
Para importar esses dashboards, basta vir no menu lateral, no ícone de + e ir na opção Import. Só usar os Ids acima e clicar no Load.
Estes serão os dashboards apresentados no benchmark.
Configurando k6
Como iremos executar um comparativo entre HTTP1.1 e HTTP2, além de que também teremos métricas de cliente e que sejam enviadas para o InfluxDB, então faremos a execução da seguinte forma:
- HTTP1.1
GODEBUG=http2client=0 k6 run ./k6/http_get.js -o influxdb=http://localhost:8086/myk6db
- HTTP2
k6 run ./k6/http_get.js -o influxdb=http://localhost:8086/myk6db
Como é possível perceber acima, o comando é praticamente o mesmo, porém conforme a documentação, o k6 por padrão tenta executar sempre usando HTTP2, então é necessário forçar o mesmo a usar o HTTP1.1 passando um parametro pro Go.
O comando acima referencia um aquivo JS que é como o k6 faz as execuções. Abaixo o tal arquivo que define o teste e este foi criado seguindo o exemplo de teste de carga (Load Test) da documentação oficial.
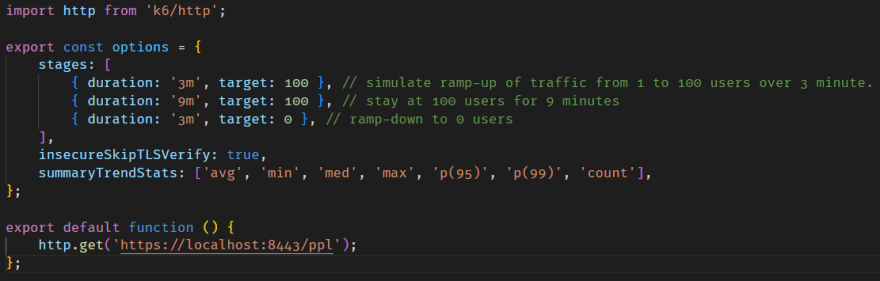
Agora finalmente, temos todos os serviços instalados e sabemos como executar cada um deles para começar as execuções.

O famigerado benchmark
Agora que instalamos tudo, sabemos como iniciar cada serviço, vem a sequência de execuções.
Iremos priorizar a mudança de protocolo diante um profile e então mudaremos para o próximo profile.

Faremos na seguinte sequência:
- HTTP1.1 e profile 1
- HTTP2 e profile 1
- HTTP1.1 e profile 2
- HTTP2 profile 2
Organizei desta forma para ficar mais fácil de visualizar os testes de cada profile. Os resultados a seguir serão sempre exibidos com os resultados do lado do cliente e depois da aplicação para cada um dos testes.
PS.: Os resultados abaixo são os mesmos que preparei para uma apresentação para colegas do trabalho. Realizei todos os testes na minha máquina mesmo para efeitos de demonstração, que devem ser realizados em um ambiente adequado sem que os serviços fiquem competindo entre si.
HTTP1.1 e profile 1
Ponto de vista cliente

Ponto de vista aplicação

HTTP2 e profile 1
Ponto de vista cliente

Ponto de vista aplicação

HTTP1.1 e profile 2
Ponto de vista cliente

Ponto de vista aplicação

HTTP2 e profile 2
Ponto de vista cliente
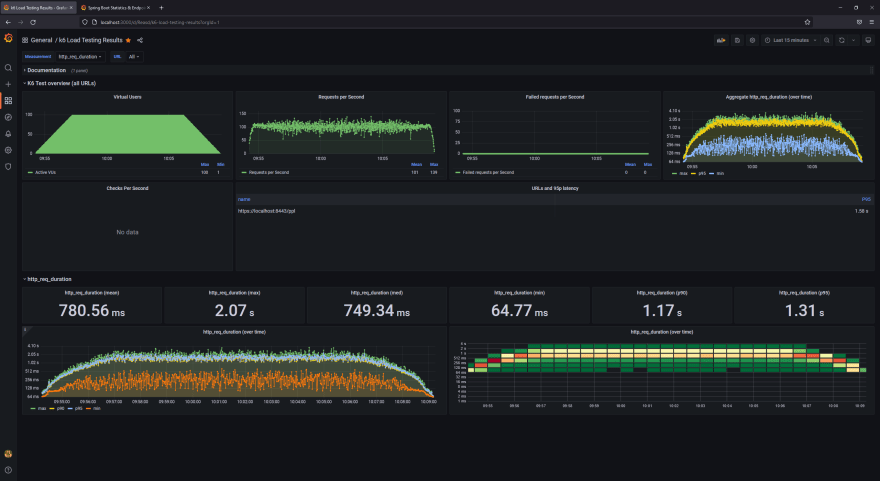
Ponto de vista aplicação

Avaliação simplória dos resultados
Analisando ambas execuções do profile 1 para HTTP1.1 e HTTP2 os resultados foram praticamente os mesmos, considerando número de requisições, tempos de resposta, uso de CPU e memória.
Comparando ambas execuções do profile 2 os resultados foram similares à análise anterior.
Ao comparar as execuções dos profiles 1 e 2, esta respondeu em torno de 10 mil requisições a mais (ou seja, a performance aumentou dado que o tempo de exeução é o mesmo para todos os testes) e consumiu mesma quantidade de CPU do que a do profile 1.
Para este caso de uso específico, não houve ganho com uso de HTTP2, mas qual seria o problema (se é que tem algum):
- falta de tuning?
- caso de uso não adequado?
- teria alguma falha no teste de carga?
- O uso da mesma máquina para rodar tudo?
Essas e outras perguntas podem surgir durante uma avaliação e acredito ser normal. Resta continuar estudando essa disciplina de engenharia de desempenho para tentar elucidar todas as questões acima.
Considerações finais
Apenas reforçando o que foi dito anteriormente e para que ninguém considere este resultado uma verdade absoluta:
- Os testes, incluindo todas as ferramentas, foram TODOS executados na minha máquina competindo entre si pelos recursos, incluindo o SO;
- O caso de uso específico tem uma quantidade mínima de processamento, apenas gerar 100 itens e retornar; não possui nenhuma dependência de recurso / serviço externo seja I/O ou de rede;
- Não foi aplicada nenhuma configuração de tuning em nenhum dos elementos, foram mantidas todas as configurações padrão.
Enfim, espero não ter sido demasiadamente longo neste post e que tudo apresentado aqui sirva de ajuda ou exemplo para que vocês possam usar de alguma forma no dia a dia.
As imagens ficaram pequenas aqui, mas irei incluir as mesmas no repositório caso queiram ver os originais.
Por falar em repositório, clique aqui para ver o código fonte.
FUTURO!?!?
Após este trabalho realizado e apresentado, um colega do trabalho mandou um: "E se a gente testar também com Undertow?".

Nos vemos na próxima parte, com os testes no Undertow.

[Atualizado 24/06] - Incluída configuração de Data Sources e IDs dos dashboards.




Top comments (0)