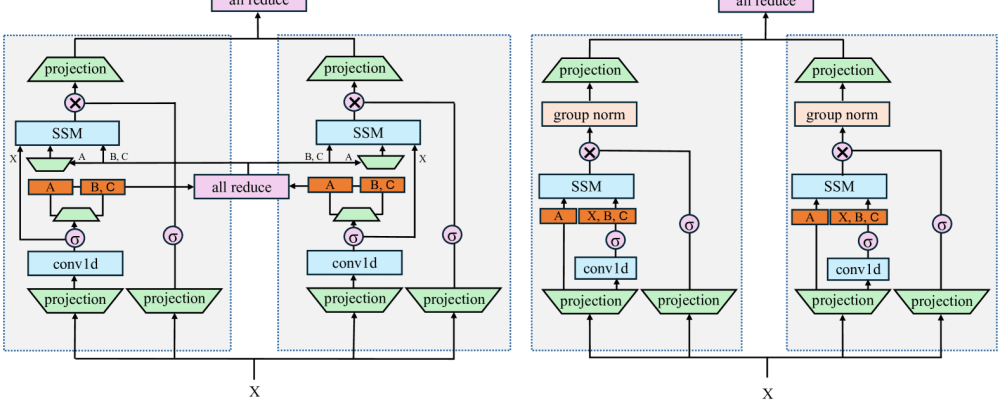
This is a Plain English Papers summary of a research paper called An Empirical Study of Mamba-based Language Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper presents an empirical study on Mamba-based language models, which are a type of state-space model used for sequence modeling.
- The researchers investigate the performance of Mamba-based models on various language tasks and compare them to other popular model architectures like Transformers.
- The paper provides insights into the strengths and limitations of Mamba-based models, as well as their potential applications in the field of natural language processing.
Plain English Explanation
Mamba-based language models are a type of machine learning model that can be used for tasks like text generation, translation, and summarization. They work by breaking down language into a sequence of states, which allows them to capture the underlying structure and patterns in the data.
The researchers in this study wanted to see how well Mamba-based models perform compared to other popular model architectures, like Transformers, on a variety of language tasks. They tested the models on things like predicting the next word in a sentence, translating between languages, and summarizing longer passages of text.
Overall, the results suggest that Mamba-based models can be quite effective for certain language tasks, particularly those that involve modeling long-term dependencies or hierarchical structures in the data. However, they may struggle in areas where Transformers excel, like handling large-scale parallelism or capturing complex semantic relationships.
The key takeaway is that Mamba-based models represent a promising alternative approach to language modeling, with their own unique strengths and weaknesses. By understanding the tradeoffs between different model architectures, researchers and practitioners can make more informed choices about which ones to use for their specific applications.
Technical Explanation
The paper begins by providing an overview of Mamba-based language models, which are a type of state-space model for sequence modeling. These models work by representing language as a series of latent states, which evolve over time according to a specified transition function.
The researchers then describe a series of experiments designed to assess the performance of Mamba-based models on various language tasks, including next-word prediction, machine translation, and text summarization. They compare the Mamba-based models to Transformer models, which have become the dominant architecture in many natural language processing applications.
The results of the experiments show that Mamba-based models can outperform Transformers on certain tasks, particularly those that involve long-range dependencies or hierarchical structure in the language. However, Transformers tend to have an advantage when it comes to tasks that require large-scale parallelism or the capture of complex semantic relationships.
The paper also discusses some of the limitations of Mamba-based models, such as their sensitivity to hyperparameter tuning and the difficulty of scaling them to very large datasets. The researchers suggest that further research is needed to address these challenges and fully unlock the potential of Mamba-based language models.
Critical Analysis
The paper presents a well-designed and thorough empirical study of Mamba-based language models, which is a valuable contribution to the literature. The researchers have clearly put a lot of thought into the experimental setup and the selection of appropriate baselines for comparison.
However, one potential limitation of the study is that it focuses primarily on a relatively narrow set of language tasks, such as next-word prediction and machine translation. It would be interesting to see how Mamba-based models perform on a wider range of language understanding and generation tasks, such as question answering, dialogue systems, or text summarization.
Additionally, the paper does not delve deeply into the underlying mechanisms and architectural choices that give Mamba-based models their unique strengths and weaknesses. A more detailed analysis of the model components and their interactions could provide additional insights into the model's inner workings and help guide future research and development.
Overall, this paper represents an important step forward in our understanding of Mamba-based language models and their potential applications in natural language processing. By encouraging further research and critical analysis in this area, the authors have laid the groundwork for more advanced and impactful applications of these models in the years to come.
Conclusion
This paper provides an in-depth empirical study of Mamba-based language models, a promising alternative to the dominant Transformer architecture in natural language processing. The researchers found that Mamba-based models can outperform Transformers on certain tasks, particularly those involving long-range dependencies or hierarchical structure in the language.
However, the paper also highlights some of the limitations of Mamba-based models, such as their sensitivity to hyperparameter tuning and challenges in scaling to very large datasets. Further research is needed to address these issues and fully unlock the potential of this approach to language modeling.
Overall, this work represents an important contribution to the ongoing efforts to develop more powerful and versatile language models, with applications ranging from text generation and translation to dialogue systems and question answering. By understanding the tradeoffs between different model architectures, researchers and practitioners can make more informed choices about which approaches to use for their specific needs and applications.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)