This is a Plain English Papers summary of a research paper called DataComp-LM: In search of the next generation of training sets for language models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Examines the need for new, high-quality training datasets for language models
- Introduces DataComp-LM, a framework for developing and evaluating such datasets
- Highlights the importance of dataset composition and quality in advancing language model capabilities
Plain English Explanation
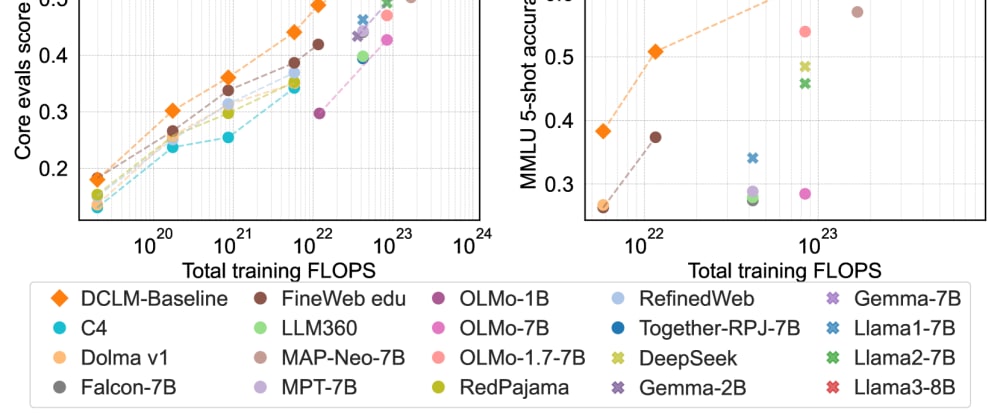
This paper explores the challenge of finding the right training data to build the next generation of powerful language models. The researchers argue that the datasets commonly used today, while large, may not be diverse or high-quality enough to help language models truly understand and engage with human language.
The paper introduces DataComp-LM, a framework for developing and evaluating new training datasets that could address these limitations. The key idea is to create datasets that not only have a vast amount of text, but also capture the breadth and nuance of how people actually communicate.
By focusing on dataset composition and quality, the researchers hope to push the boundaries of what language models can do - from engaging in more natural conversations to demonstrating deeper reasoning and understanding. This work could have important implications for fields like question answering, language evaluation, and even multimodal AI.
Technical Explanation
The paper argues that while existing language model training datasets are impressively large, they may not capture the full breadth and nuance of human communication. The researchers propose the DataComp-LM framework as a way to develop and evaluate new, high-quality training datasets that could help address this challenge.
Key elements of the DataComp-LM framework include:
- Comprehensive evaluation metrics to assess dataset quality, diversity, and suitability for training language models
- Techniques for systematically curating datasets that span a wide range of domains, styles, and perspectives
- Procedures for ensuring dataset integrity and minimizing potential biases or contamination
Through experiments and case studies, the paper demonstrates how DataComp-LM can be used to create training datasets that enable language models to perform better on a variety of tasks, including those involving Chinese-centric content.
Critical Analysis
The paper makes a compelling case for the importance of dataset quality and composition in advancing language model capabilities. However, it also acknowledges several caveats and areas for further research:
- Developing comprehensive evaluation metrics for dataset quality is a complex challenge, and the researchers note that more work is needed in this area.
- Curating diverse, high-quality datasets at scale can be resource-intensive, and the paper does not fully address the practical challenges involved.
- The paper focuses primarily on textual data, but language models are increasingly being trained on multimodal inputs, which may require different approaches to dataset development.
Additionally, while the paper highlights the potential benefits of the DataComp-LM framework, it does not provide a thorough comparison to alternative approaches or address potential limitations or drawbacks of the proposed methodology.
Conclusion
The DataComp-LM framework introduced in this paper represents an important step towards developing the next generation of training datasets for language models. By emphasizing the importance of dataset composition and quality, the researchers aim to push the boundaries of what language models can achieve in terms of natural language understanding, reasoning, and engagement.
While the paper leaves some open questions, it lays the groundwork for a more systematic and rigorous approach to dataset curation and evaluation. As language models continue to play an increasingly central role in a wide range of applications, this work could have significant implications for the future of natural language processing and artificial intelligence.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)