This is a Plain English Papers summary of a research paper called garak: A Framework for Security Probing Large Language Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Introduces a framework called "garak" for probing the security vulnerabilities of large language models (LLMs)
- Includes techniques for generating adversarial prompts and evaluating LLM responses to assess their robustness and security
- Explores how LLMs can be misused for malicious purposes, and how to safeguard against such threats
Plain English Explanation
The paper presents a framework called "garak" that allows researchers to thoroughly test the security of large language models (LLMs) - advanced AI systems that can generate human-like text. LLMs have become increasingly powerful and widespread, but they can also be vulnerable to misuse, such as generating misinformation or being exploited by bad actors.
The "garak" framework provides a way to probe these vulnerabilities by generating adversarial prompts - carefully crafted inputs designed to trick the LLM into producing harmful or unintended outputs. By evaluating how the LLM responds to these prompts, researchers can assess the model's robustness and identify potential security weaknesses.
This is an important area of research, as LLMs are becoming more prominent in a wide range of applications, from content generation to cybersecurity and beyond. Understanding the potential security risks of these models, and developing ways to mitigate them, is crucial for ensuring they are used safely and responsibly.
Technical Explanation
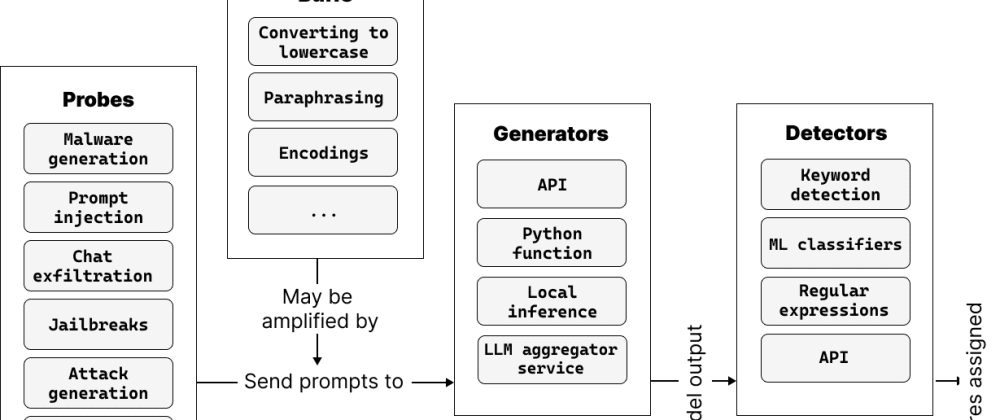
The paper introduces a framework called "garak" that provides a structured approach for probing the security vulnerabilities of large language models (LLMs). The key components of the framework include:
Prompt Generation: The framework can generate a diverse set of adversarial prompts - carefully crafted inputs designed to elicit harmful or unintended responses from the LLM. These prompts target various security aspects, such as the generation of misinformation, hate speech, or code exploits.
Response Evaluation: The framework evaluates the LLM's responses to the adversarial prompts, assessing factors like toxicity, factual accuracy, and security implications. This allows researchers to identify potential vulnerabilities and the LLM's overall robustness.
Mitigation Strategies: The paper also explores potential mitigation strategies, such as using filtering techniques or fine-tuning the LLM on curated datasets, to improve the model's security and reduce the risk of misuse.
The researchers demonstrate the effectiveness of the "garak" framework through a series of experiments on popular LLMs, including GPT-3 and DALL-E. The results highlight the ability of the framework to uncover a range of security vulnerabilities, providing valuable insights for the development of more secure and trustworthy LLMs.
Critical Analysis
The paper provides a comprehensive and well-designed framework for probing the security vulnerabilities of large language models (LLMs). The researchers have thoughtfully considered the potential risks and misuses of these powerful AI systems, and have developed a systematic approach to identify and mitigate these issues.
One potential limitation of the research is that it focuses primarily on the security aspects of LLMs, without delving deeply into the broader ethical and societal implications of these technologies. While the paper touches on the importance of developing secure and responsible LLMs, further research could explore the wider ramifications of LLM usage, such as the impact on content moderation, disinformation, and privacy.
Additionally, the paper could benefit from a more in-depth discussion of the limitations and challenges of the "garak" framework itself. While the researchers mention potential mitigation strategies, there may be other factors or considerations that could impact the effectiveness of the framework in real-world scenarios.
Overall, the "garak" framework represents a valuable contribution to the growing body of research on the security and responsible development of large language models. By continuing to explore these important issues, researchers can help ensure that these powerful AI systems are used in a safe and ethical manner.
Conclusion
The "garak" framework introduced in this paper provides a comprehensive approach for probing the security vulnerabilities of large language models (LLMs). By generating adversarial prompts and evaluating the LLM's responses, researchers can identify potential weaknesses and develop mitigation strategies to improve the robustness and security of these AI systems.
As LLMs become more prevalent in a wide range of applications, understanding and addressing their security risks is crucial. The "garak" framework offers a valuable tool for researchers and developers to assess the security of LLMs, contributing to the broader goal of ensuring these powerful AI systems are used in a safe and responsible manner.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)