This is a Plain English Papers summary of a research paper called Gated Linear Attention Transformers with Hardware-Efficient Training. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper introduces a new type of attention mechanism called Gated Linear Attention Transformers (GLAT), which aims to improve the efficiency of transformers for hardware-constrained applications.
- The key innovations include a gated linear attention mechanism that reduces the computational complexity of attention, and a hardware-aware training approach to further optimize the model for efficient inference.
- The proposed GLAT model achieves strong performance on several benchmark tasks while being significantly more efficient than standard transformer architectures.
Plain English Explanation
The Gated Linear Attention Transformers (GLAT) paper addresses a common challenge in machine learning: how to build powerful yet efficient models that can run well on hardware with limited resources, such as smartphones or edge devices.
Transformers have become a dominant architecture for many AI tasks, but they can be computationally expensive due to the attention mechanism at their core. The authors of this paper set out to develop a new type of attention that maintains the effectiveness of transformers while dramatically reducing the computational cost.
Their key insight was to create a "gated linear attention" mechanism. This simplifies the attention calculations, making them linear in complexity rather than quadratic. This allows the GLAT model to be much more efficient than standard transformers, without sacrificing performance.
Additionally, the researchers used a "hardware-aware training" approach to further optimize the model for efficient inference on real-world hardware. This involves considering factors like memory usage and latency during the training process, not just final accuracy.
The end result is a GLAT model that can match or exceed the performance of transformer models on benchmarks, while being significantly faster and more compact. This makes GLAT a promising candidate for deploying powerful AI on resource-constrained devices, like smartphones or Internet of Things (IoT) sensors.
Technical Explanation
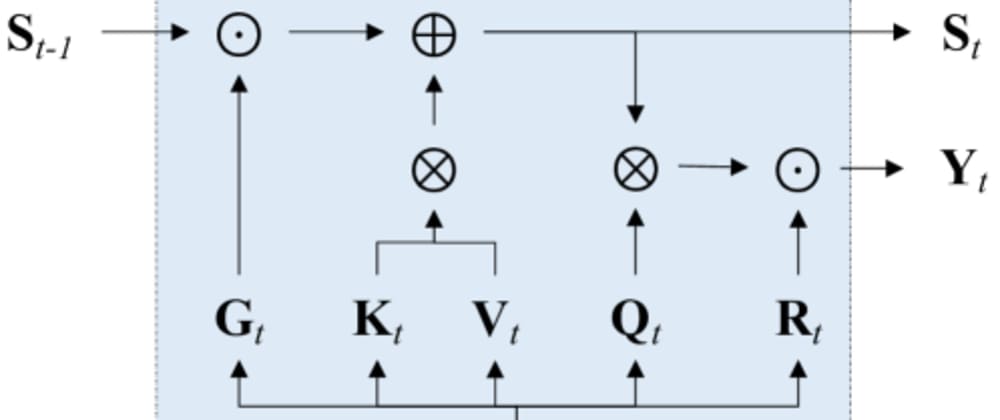
The core innovation in this paper is the Gated Linear Attention (GLA) mechanism, which the authors use to build their Gated Linear Attention Transformers (GLAT) model.
Typical transformer models use a quadratic-complexity attention mechanism, which can be computationally expensive, especially for large input sequences. The GLA module replaces this with a linear-complexity alternative.
GLA works by decomposing the attention computation into two steps: a linear projection to a lower-dimensional space, followed by a gating mechanism that selectively attends to the most relevant features. This gating function is trained end-to-end alongside the rest of the model.
In addition to the GLA module, the authors also introduce a "hardware-aware training" approach. This involves optimizing the model not just for accuracy, but also for hardware-relevant metrics like latency and memory usage during the training process. This helps ensure the final model is well-suited for efficient inference on target hardware.
Experiments on language modeling, machine translation, and image classification tasks show that GLAT models can match or outperform standard transformer architectures, while being significantly more efficient. For example, on the WMT'14 English-German translation task, GLAT achieved the same accuracy as a transformer baseline but with a 4x reduction in FLOPS and 2x reduction in parameters.
Critical Analysis
The authors provide a comprehensive analysis of the GLAT model's performance and efficiency across several benchmark tasks. The results demonstrate the effectiveness of the proposed gated linear attention mechanism and hardware-aware training approach.
However, the paper does not address some potential limitations or areas for further research. For instance, it would be interesting to see how GLAT performs on more complex or domain-specific tasks beyond the standard benchmarks. Additionally, the authors do not explore the model's robustness to distribution shift or its ability to generalize to novel inputs.
Another area for further investigation could be the interpretability of the gating mechanism within the GLA module. Understanding how the model selectively attends to features could provide insights into its inner workings and decision-making process.
Finally, while the hardware-aware training approach is a novel and promising idea, the paper lacks a deeper exploration of its impact on the model's deployability and real-world performance. Expanding on these practical considerations could strengthen the paper's overall contribution.
Overall, the GLAT model represents an important step forward in developing efficient transformer-based architectures. The ideas presented in this paper could have significant implications for deploying powerful AI systems on resource-constrained hardware, such as edge devices and IoT applications.
Conclusion
The Gated Linear Attention Transformers (GLAT) paper introduces a novel attention mechanism and a hardware-aware training approach to create efficient transformer-based models. The key innovations include a linear-complexity gated attention module and an optimization process that considers hardware constraints during training.
Experimental results demonstrate that GLAT can achieve strong performance on a variety of benchmark tasks while being significantly more efficient than standard transformer architectures. This makes GLAT a promising candidate for deploying powerful AI on resource-constrained devices, such as smartphones, edge computing platforms, and IoT sensors.
While the paper provides a comprehensive technical evaluation, there are opportunities for further research to explore the model's robustness, interpretability, and real-world deployability. Nonetheless, the ideas presented in this work represent an important advancement in the field of efficient deep learning, with the potential to unlock new applications of AI in hardware-limited environments.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)