This is a Plain English Papers summary of a research paper called Transformers are Multi-State RNNs. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Examines the relationship between transformers and recurrent neural networks (RNNs)
- Proposes that transformers can be viewed as a type of multi-state RNN
- Explores the implications of this perspective for understanding transformer models
Plain English Explanation
Transformers are a type of deep learning model that have become very popular in recent years, particularly for tasks like language modeling and machine translation. At a high level, transformers work by [attention] - they can "focus" on the most relevant parts of their input when generating an output.
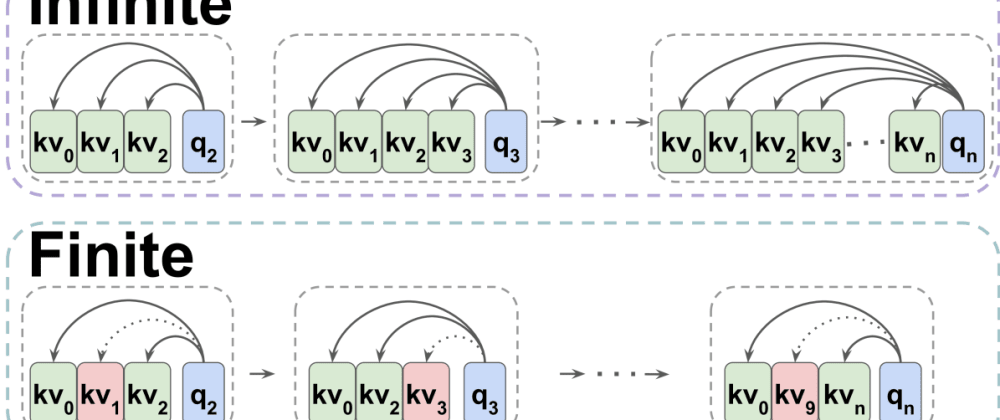
This paper argues that transformers can actually be thought of as a special type of [recurrent neural network (RNN)]. RNNs are a class of models that process sequential data one element at a time, maintaining an internal "state" that gets updated as the sequence is processed. The authors suggest that transformers can be viewed as a multi-state RNN, where the attention mechanism allows the model to dynamically update multiple distinct states as it processes the input.
This new perspective on transformers has some interesting implications. It may help us better [understand the inner workings of transformer models] and how they differ from traditional RNNs. It could also lead to new ways of [designing and training transformer-based models], drawing on the rich history and techniques developed for RNNs.
Technical Explanation
The paper first provides background on [RNNs] and [transformers]. RNNs are a class of neural network models that process sequences one element at a time, maintaining an internal state that gets updated as the sequence is processed. Transformers, on the other hand, use an [attention mechanism] to dynamically focus on relevant parts of the input when generating an output.
The key insight of the paper is that transformers can be viewed as a type of multi-state RNN. The attention mechanism in transformers allows the model to dynamically update multiple distinct internal states as it processes the input sequence. This is in contrast to traditional RNNs, which maintain a single, monolithic state.
To support this claim, the authors [analyze the mathematical structure of transformers] and show how it can be expressed as a multi-state RNN. They also [demonstrate empirically] that transformers exhibit behaviors characteristic of multi-state RNNs, such as the ability to remember and utilize past information in a targeted way.
Critical Analysis
The authors make a compelling case that transformers can be fruitfully viewed as a type of multi-state RNN. This perspective may [help bridge the gap between transformer and RNN research], allowing insights and techniques from the well-established RNN literature to be applied to transformers.
However, the paper does not fully [address the limitations of this analogy]. Transformers have many unique architectural features, like the use of self-attention, that may not have direct analogues in traditional RNNs. The extent to which this analogy can be pushed, and what insights it can actually yield, remains an open question.
Additionally, the [experimental evidence] provided, while suggestive, is somewhat limited. More thorough investigations, perhaps comparing the performance and behaviors of transformers and multi-state RNNs on a wider range of tasks, would help strengthen the claims made in the paper.
Conclusion
This paper presents a novel perspective on transformer models, suggesting they can be viewed as a type of multi-state RNN. This insight could [lead to new ways of understanding and designing transformer-based models], drawing on the rich history and techniques developed for RNNs.
While the paper makes a compelling case, there are still open questions and limitations to this analogy that warrant further exploration. Nonetheless, this work represents an important step in [bridging the gap between transformers and other sequential modeling approaches], and could have significant implications for the future development of deep learning architectures.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)