
This article was written based on our research and expertise of building real-time video processing products, together with creating pipelines for applying Machine Learning and Deep Learning models.
When it comes to real time video processing, the data pipeline becomes more complex to handle. And we are striving to minimize latency in streaming video. On the other hand, we must also ensure sufficient accuracy of the implemented models.
Overall, the livestreaming industry has increased up to 99% in hours watched since last year according to dailyesports.gg statistics. So, it will totally change fan experience, gaming, telemedicine, etc. Moreover, Grand View Research reports that the Video Stream Market will be worth USD 184.27 billion by 2027.
AI-driven Live Video Processing Use Cases
Trained models, able to detect certain objects, are not an uncomplicated thing to create. However, when it comes to children in kindergarten – security is a top priority. The models may help to prevent, for example, a kid from running away or slipping out. Or, as another example, also about runaways, would be animals leaving the borders of a farm, zoo or reserve.
Organizations that store and process facial images for identification and authentication, sometimes need to implement security solutions to ensure privacy and meet GDPR data protection requirements. Some examples would be blurring faces while streaming conferences, meetings, etc. via YouTube, CCTV, private channels, or security cameras in a manufacturing building, and in shopping malls.
Another area of AI-based Visual Inspection for Defect Detection has been implemented at manufacturing facilities that are on the way to becoming fully robotic. So, computer vision makes it easier to distinguish the manufacturer’s flaws. With visual inspection technology, integration of deep learning methods allows differentiating parts, anomalies, and characters, which imitate a human visual inspection while running a computerized system.
How to Speed up Real Time Video Processing?
A Technical problem, which we are solving, is to blur faces of video subjects quickly and accurately while live streaming, and without quality loss through the use of Artificial Intelligence.
In short, video processing may be sketched as a series of consequent processes: decoding, computation and encoding. Although the criteria for this serial process, like speed, accuracy and flexibility may complicate the easiness of the first blush skim. So, the final resolution is supposed to be flexible in terms of input, output and configuration.
To make processing faster, keeping the accuracy at the reasonable level is possible in several ways: 1) to do something parallely; 2) to speed up the algorithms.
Basically, there are two approaches for ways to parallel the processes: file splitting and pipeline architecture.
The first one, file splitting, is to make the algorithms run in parallel so it might be possible to keep using slower, yet accurate models. It is implemented when video is split into parts and processed in parallels. In such a manner, splitting is a kind of virtual file generation, not a real sub-file generation. However, this process is not very suitable for real time processing, because it may be difficult to pause, resume or even move the processing at a different position in timespin.
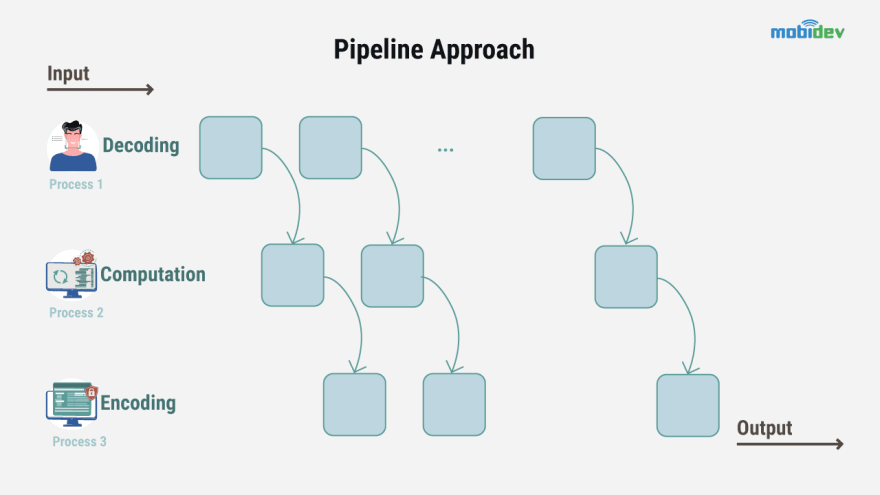
The second one, pipeline architecture, is to make a certain effort to accelerate the algorithms themselves, or their parts with no significant loss of the accuracy. Instead of splitting the video, the pipeline approach is aimed to split and parallelize the operations, which are performed during the processing. Because of this process, the pipeline approach is more flexible.
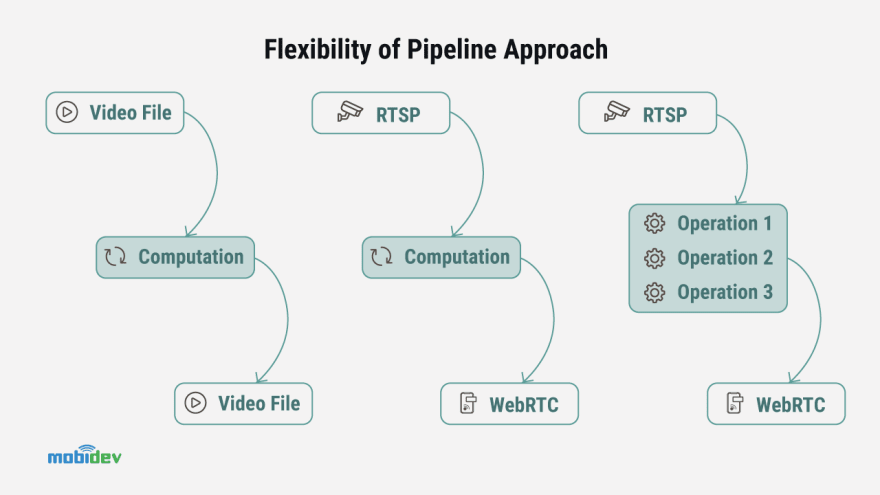
Why is the pipeline approach more flexible? One of the benefits of the pipeline is the ease of manipulation of the components due to requirements. Decoding can work using a video file to encode frames into another file.
Alternatively, input can be an RTSP stream from an IP camera. Output can be a WebRTC connection in the browser or mobile application. There is a unified architecture, which is based on a video stream for all combinations of input and output formats. The computation process is not necessarily a monolith operation.
How to Implement a Pipeline Approach
As part of one of the projects, we had to process video in real time using AI algorithms.
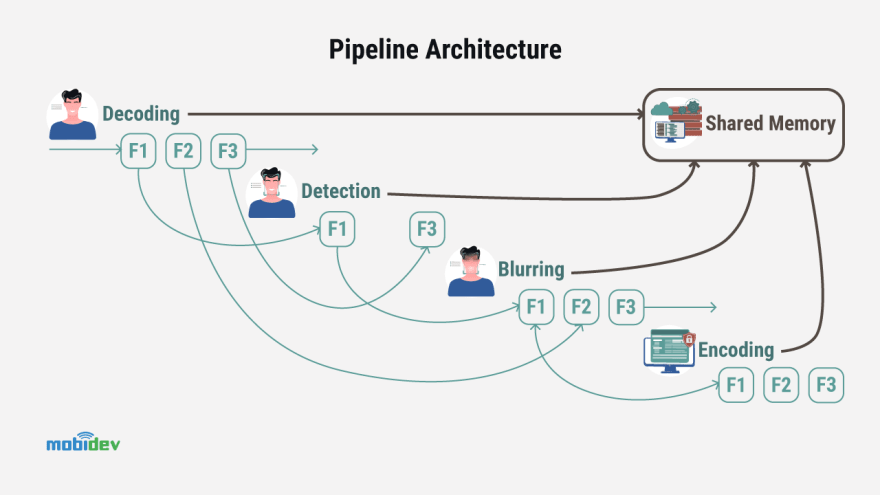
The pipeline was composed of decoding, face detection, face blurring and encoding stages. The flexibility of the system was essential in this case because it was essential to process not only video files, but also different formats of video live-stream. It showed a good FPS in range 30-60 depending on the configuration.
INTERPOLATION WITH TRACKING
We used the tracking algorithm based on centroids, because it is easier to apply. However, when there is a need – other algorithms like Deep SORT can be used. But they really impact the speed if there are too many faces on the video. That’s why interpolation should be used additionally.
What is the quality of interpolated frames? Since we need to skip some frames, we’d like to know the quality of the interpolated frames. Therefore, the F1 metric was calculated and ensured that there aren’t too many false positives and false negatives because of interpolation. F1 value was around 0.95 for most of the video examples.
SHARING MEMORY
The next stage of this process is sharing memory. Usually, it is quite slow to send data through the queue, so to do it between the processes in Python is really the best way to do this process
The PyTorch version of multiprocessing has the ability to pass a tensor handle through the queue so that another process can just get a pointer to the existing GPU memory. So, another approach was used: a system level inter-process communication (IPC) mechanism for shared memory based on POSIX API. The speed of interprocess communication was extremely improved with the help of Python libraries, providing an interface for using this memory.
MULTIPLE WORKERS OR MULTIPROCESSING
Finally, there is a need to add several workers for a pipeline component to reduce the time that is needed for processing. This was applied in the face detection stage, and may also be done for every heavy operation which doesn’t need an ordered input. The thing is that it really depends on the operations which are done inside the pipeline. In case, there is comparatively fast face detection, and FPS may be lowered after adding more detection workers.
The time which is required for managing one more process can be bigger than time we gained from adding it. Neural networks, which are used in the multiple workers, will calculate tensors in a serial CUDA stream unless a separate stream is created for each network, which may be tricky to implement.
Multiple workers, due to their concurrent nature, can’t guarantee that the order will be the same with input sequence. Therefore, it requires additional effort to fix the order in the pipeline stages while encoding, for example. Still, the skipping frames may cause the same problem.
Thus, detection time was reduced almost twice, provided that we have 2 workers running a model with MobileNetv2 backbone.
How to Develop an AI-Based Live Video Processing System
How complex is it to apply AI to live video streams? As for the basic scenario, the process of implementation consists of several stages:
- Adjusting a pre-trained neural network (or traine) to be able to perform the tasks needed
- Setting a cloud infrastructure to enable processing of the video and to be scalable to a certain point
- Building a software layer to pack the process and implement user scenarios (mobile applications, web and admin panels, etc.)
To create a product like this, using a pre-trained NN and some simple application layers, takes 3-4 months for building an MVP. However, the details are crucial and each product is unique in terms of the scope and timeline.
We strongly suggest our client start with the Proof of Concept to explore the main and/or the most complicated flow. Spending a few weeks on exploring the best approaches and gaining results, often secures further development flow and brings confidence to both the client and the engineering team.
Written by Serhii Maksymenko, Data Science Engineer at MobiDev.
Full article originally published at https://mobidev.biz. It is based on MobiDev technology research and experience providing software development services.





Top comments (0)