TL;DR
Learn how to set up various databases using Aspire by building a simple social media application.
Source code : https://github.com/NikiforovAll/social-media-app-aspire
Table of Contents:
- TL;DR
- Introduction
- Application Design. Add PostgreSQL
- Application Design. Add Redis
- Application Design. Add MongoDb
- Application Design. Add Elasticsearch
- Putting everything together. Migration
- Conclusion
- References
Introduction
Polyglot persistence refers to the practice of using multiple databases or data storage technologies within a single application. Instead of relying on just one database for everything, you can choose the most suitable database for each specific need or type of data. It’s like having a toolbox with different tools for different tasks, so you can use the right tool for each job.
The importance of polyglot persistence lies in the fact that different databases excel in different areas. For example, relational databases like PostgreSQL are great for structured data and complex queries, while NoSQL databases like MongoDB are better suited for handling unstructured or semi-structured data. Similarly, Elasticsearch is optimized for full-text search, and Redis excels in caching and high-performance scenarios.
By leveraging the strengths of different databases, developers can design more efficient and scalable systems. They can choose the right tool for the job, ensuring that each component of the application is using the most suitable database technology.
The selection of the correct database depends on various factors such as the nature of the data, the expected workload, performance requirements, scalability needs, and the complexity of the queries. By carefully considering these factors, developers can ensure that the chosen databases align with the specific requirements of the application.
Case Study - Social Media App
In this post we will design social media application. It typically includes something like: Users, Posts, Follows, Likes, etc.
Overall, these components provide essential functionality for a social media app. The search functionality allows users to find other users and relevant posts, while the analytics component provides insights into user activity and engagement.
Application Design. Add PostgreSQL
In this section, we will discuss how to implement the users and follows functionality.
Relational data, such as user information and their relationships (follows), can be easily represented and managed in a relational database like PostgreSQL.
One of the main benefits of using a relational database is the ability to efficiently retrieve and manipulate data. They are well-suited for scenarios where data needs to be structured and related to each other, such as user information and their relationships.
Relational databases scale efficiently in most cases. As the amount of data and the number of users grow, relational databases can handle the increased load by optimizing queries and managing indexes. This means that as long as the database is properly designed and optimized, it can handle a significant amount of data and user activity without performance issues.
However, in some cases, when an application experiences extremely high traffic or deals with massive amounts of data, even a well-optimized relational database may face scalability challenges.
In situations where the workload grows, it is apply vertical scaling. Vertical scaling involves upgrading hardware resources or optimizing the database configuration to increase the capacity of a single database instance, such as adding more memory or CPU power. This approach is typically sufficient, but sometimes s it becomes practically impossible to further scale vertically.
At that point, a natural transition is to employ horizontal scaling through a technique called sharding. Sharding involves distributing the data across multiple database instances or servers, where each instance or server is responsible for a subset of the data. By dividing the workload among multiple database nodes, each node can handle a smaller portion of the data, resulting in improved performance and scalability.
In practice, implementing horizontal scaling with sharding in a real-world application is not as straightforward as it may seem. It requires careful planning and significant effort to ensure a smooth and successful transition.
Code
We will use Aspire PostgreSQL component. See Aspire documentation to know what is actually means to “consume” Aspire Component. See .NET Aspire components overview
Here is how to configure AppHost. Add Aspire.Hosting.PostgreSQL package and configure it:
var builder = DistributedApplication.CreateBuilder(args);
var usersDb = builder
.AddPostgres("dbserver")
.WithDataVolume()
.WithPgAdmin(c => c.WithHostPort(5050))
.AddDatabase("users-db");
var api = builder
.AddProject<Projects.Api>("api")
.WithReference(usersDb);
var migrator = builder
.AddProject<Projects.MigrationService>("migrator")
.WithReference(usersDb);
Add Aspire.Npgsql.EntityFrameworkCore.PostgreSQL and register UsersDbContext via AddNpgsqlDbContext method:
var builder = WebApplication.CreateBuilder(args);
builder.AddServiceDefaults();
builder.AddNpgsqlDbContext<UsersDbContext>("users-db");
var app = builder.Build();
app.MapUsersEndpoints();
app.MapDefaultEndpoints();
app.Run();
Use DbContext regularly:
var users = app.MapGroup("/users");
users.MapGet(
"/{id:int}/followers",
async Task<Results<Ok<List<UserSummaryModel>>, NotFound>> (
int id,
UsersDbContext dbContext,
CancellationToken cancellationToken
) =>
{
var user = await dbContext
.Users.Where(u => u.UserId == id)
.Include(u => u.Followers)
.ThenInclude(f => f.Follower)
.FirstOrDefaultAsync(cancellationToken);
if (user == null)
{
return TypedResults.NotFound();
}
var followers = user
.Followers.Select(x => x.Follower)
.ToUserSummaryViewModel()
.ToList();
return TypedResults.Ok(followers);
}
)
.WithName("GetUserFollowers")
.WithTags(Tags)
.WithOpenApi();
}
Here is how to retrieve followers of a user:
❯ curl -X 'GET' 'http://localhost:51909/users/1/followers' -s | jq
# [
# {
# "id": 522,
# "name": "Jerome Kilback",
# "email": "Jerome_Kilback12@gmail.com"
# },
# {
# "id": 611,
# "name": "Ernestine Schiller",
# "email": "Ernestine_Schiller@hotmail.com"
# }
# ]
💡 See source code for more details of how to represent a user and follower relationship.
💡 See source code to learn how to apply database migrations and use Bogus to seed the data.
Application Design. Add Redis
Redis can be used as a first-level cache in an application to improve performance and reduce the load on the primary data source, such as a database.
A first-level cache, also known as an in-memory cache, is a cache that resides closest to the application and stores frequently accessed data. It is typically implemented using fast and efficient data stores, such as Redis, to provide quick access to the cached data.
When a request is made to retrieve data, the application first checks the first-level cache. If the data is found in the cache, it is returned immediately, avoiding the need to query the primary data source. This significantly reduces the response time and improves the overall performance of the application.
To use Redis as a first-level cache, the application needs to implement a caching layer that interacts with Redis. When data is requested, the caching layer checks if the data is present in Redis. If it is, the data is returned from the cache. If not, the caching layer retrieves the data from the primary data source, stores it in Redis for future use, and then returns it to the application.
By using Redis as a first-level cache, applications can significantly reduce the load on the primary data source, improve response times, and provide a better user experience.
Code
It is very easy to setup Redis Output Caching Component.
Just install Aspire.StackExchange.Redis.OutputCaching and use it like this:
From the AppHost:
var builder = DistributedApplication.CreateBuilder(args);
var redis = builder.AddRedis("cache");
var usersDb = builder
.AddPostgres("dbserver")
.WithDataVolume()
.WithPgAdmin(c => c.WithHostPort(5050))
.AddDatabase("users-db");
var api = builder
.AddProject<Projects.Api>("api")
.WithReference(usersDb)
.WithReference(redis);
From the consuming service:
var builder = WebApplication.CreateBuilder(args);
builder.AddServiceDefaults();
builder.AddNpgsqlDbContext<UsersDbContext>("users-db");
builder.AddRedisOutputCache("cache"); // <-- add this
var app = builder.Build();
app.MapUsersEndpoints();
app.MapDefaultEndpoints();
app.UseOutputCache(); // <-- add this
app.Run();
Just add one-liner using CacheOutput method, meta-programming at this’s best 😎:
var users = app.MapGroup("/users");
users
.MapGet(
"",
async (
UsersDbContext dbContext,
CancellationToken cancellationToken
) =>
{
var users = await dbContext
.Users.ProjectToViewModel()
.OrderByDescending(u => u.FollowersCount)
.ToListAsync(cancellationToken);
return TypedResults.Ok(users);
}
)
.WithName("GetUsers")
.WithTags(Tags)
.WithOpenApi()
.CacheOutput(); // <-- add this
Here is first hit to the API, it takes ~25ms:

And here is subsequent request, it takes ~6ms:

💡Note, in the real-world scenario, the latency reduction can be quite significant when using Redis as a caching layer. For instance, consider an application that initially takes around 120ms to fetch data directly from a traditional SQL database. After implementing Redis for caching, the same data retrieval operation might only take about 15ms. This represents a substantial decrease in latency, improving the application’s responsiveness and overall user experience.
Application Design. Add MongoDb
NoSQL databases, such as MongoDB, are well-suited for storing unstructured or semi-structured data like posts and related likes in a social media application. Unlike relational databases, NoSQL databases do not enforce a fixed schema, allowing for flexible and dynamic data models.
In a NoSQL database, posts can be stored as documents, which are similar to JSON objects. Each document can contain various fields representing different attributes of a post, such as the post content, author, timestamp, and likes. The likes can be stored as an array within the post document, where each element represents a user who liked the post.
One of the key advantages of using NoSQL databases for storing posts and related likes is the ability to perform efficient point reads. Point reads refer to retrieving a single document or a specific subset of data from a database based on a unique identifier, such as the post ID.
NoSQL databases like MongoDB use indexes to optimize point reads. By creating an index on the post ID field, the database can quickly locate and retrieve the desired post document based on the provided ID. This allows for fast and efficient retrieval of individual posts and their associated likes.
Furthermore, NoSQL databases can horizontally scale by distributing data across multiple servers or nodes. This enables high availability and improved performance, as the workload is divided among multiple instances. As a result, point reads can be performed in parallel across multiple nodes, further enhancing the efficiency of retrieving posts and related likes.
MongoDB excels at this because it was designed with built-in support for horizontal scaling. This means you can easily add more servers as your data grows, without any downtime or interruption in service.
Code
Adding MongoDb Component is straightforward, the process is similar to adding other databases:
Add to AppHost:
var builder = DistributedApplication.CreateBuilder(args);
var postsDb = builder
.AddMongoDB("posts-mongodb")
.WithDataVolume()
.WithMongoExpress(c => c.WithHostPort(8081))
.AddDatabase("posts-db");
var api = builder
.AddProject<Projects.Api>("api")
.WithReference(postsDb);
Consuming service:
var builder = WebApplication.CreateBuilder(args);
builder.AddServiceDefaults();
builder.AddMongoDBClient("posts-db");
var app = builder.Build();
app.MapPostsEndpoints();
app.MapDefaultEndpoints();
app.Run();
To use it, we define a simple wrapper client over a MongoDb collection:
public class PostService
{
private readonly IMongoCollection<Post> collection;
public PostService(
IMongoClient mongoClient,
IOptions<MongoSettings> settings
)
{
var database = mongoClient.GetDatabase(settings.Value.Database);
this.collection = database.GetCollection<Post>(settings.Value.Collection);
}
public async Task<Post?> GetPostByIdAsync(
string id,
CancellationToken cancellationToken = default
) =>
await this
.collection.Find(x => x.Id == id)
.FirstOrDefaultAsync(cancellationToken);
}
Notice, IMongoClient is added to the DI by AddMongoDBClient method.
var posts = app.MapGroup("/posts");
posts
.MapGet(
"/{postId}",
async Task<Results<Ok<PostViewModel>, NotFound>> (
string postId,
PostService postService,
CancellationToken cancellationToken
) =>
{
var post = await postService.GetPostByIdAsync(postId, cancellationToken);
return post == null
? TypedResults.NotFound()
: TypedResults.Ok(post.ToPostViewModel());
}
)
.WithName("GetPostById")
.WithTags(Tags)
.WithOpenApi();
Application Design. Add Elasticsearch
Elasticsearch is a powerful search and analytics engine that is commonly used for full-text search and data analysis in applications. It is designed to handle large volumes of data and provide fast and accurate search results.
To use Elasticsearch for full-text search, you need to index your data in Elasticsearch. The data is divided into documents, and each document is composed of fields that contain the actual data. Elasticsearch indexes these documents and builds an inverted index, which allows for efficient searching.
To search for posts using Elasticsearch, you can perform a full-text search query. This query can include various parameters, such as the search term, filters, sorting, and pagination. Elasticsearch will analyze the search term and match it against the indexed documents, returning the most relevant results.
Elasticsearch is also well-suited for performing analytics tasks, such as calculating leaderboards. Elasticsearch aggregation feature allows you to group and summarize data based on certain criteria. For example, you can aggregate likes by author and calculate the number of likes for each author.
One of the key advantages of Elasticsearch is its ability to scale horizontally, allowing you to handle large volumes of data and increasing the capacity of your search and analytics system.
To achieve scalability, Elasticsearch uses a distributed architecture. It allows you to create a cluster of multiple nodes, where each node can hold a portion of the data and perform search and indexing operations. This distributed nature enables Elasticsearch to handle high traffic loads and provide fast response times.
When you add more nodes to the cluster, Elasticsearch automatically redistributes the data across the nodes, ensuring that the workload is evenly distributed. This allows you to scale your system by simply adding more hardware resources without any downtime or interruption in service.
In addition to distributing data, Elasticsearch also supports data replication. By configuring replica shards, Elasticsearch creates copies of the data on multiple nodes. This provides fault tolerance and high availability, as the system can continue to function even if some nodes fail.
Code
As for now, there is no official Elasticsearch Component for Aspire, the work is in progress. But, it is possible to define custom Aspire Component and share them as a Nuget package.
💡 For the sake of simplicity, I will not explain how to add Elasticsearch Aspire Component, please see source code for more details.
Assuming we already have Elasticsearch component, here is how to add it to AppHost:
var builder = DistributedApplication.CreateBuilder(args);
var redis = builder.AddRedis("cache");
var postsDb = builder
.AddMongoDB("posts-mongodb")
.WithDataVolume()
.WithMongoExpress(c => c.WithHostPort(8081))
.AddDatabase("posts-db");
var elastic = builder
.AddElasticsearch("elasticsearch", password, port: 9200)
.WithDataVolume();
var api = builder
.AddProject<Projects.Api>("api")
.WithReference(elastic);
Add it to consuming services:
var builder = WebApplication.CreateBuilder(args);
builder.AddServiceDefaults();
builder.AddElasticClientsElasticsearch("elasticsearch");
builder.AddMongoDBClient("posts-db");
var app = builder.Build();
app.MapPostsEndpoints();
app.MapDefaultEndpoints();
app.Run();
As result, we have ElasticsearchClient inject into the DI.
But how do we get data into Elasticsearch? Elasticsearch isn’t typically used as a primary database. Instead, it’s used as a secondary database that’s optimized for read operations, especially search. So, we take our data from our primary database (MongoDb), break it down into smaller, simpler pieces, and then feed it into Elasticsearch. This makes it easier for Elasticsearch to search through the data quickly and efficiently.
Search
💡The process of reliable data denormalization is out of scope of this article. A straightforward implementation might be to write the data to the primary database and then to the secondary one.
Assuming we already have data in Elasticsearch, let’s see how to query it:
public class ElasticClient(ElasticsearchClient client)
{
private const string PostIndex = "posts";
public async Task<IEnumerable<IndexedPost>> SearchPostsAsync(
PostSearch search,
CancellationToken cancellationToken = default
)
{
var searchResponse = await client.SearchAsync<IndexedPost>(
s =>
{
void query(QueryDescriptor<IndexedPost> q) =>
q.Bool(b =>
b.Should(sh =>
{
sh.Match(p =>
p.Field(f => f.Title).Query(search.Title)
);
sh.Match(d =>
d.Field(f => f.Content).Query(search.Content)
);
})
);
s.Index(PostIndex).From(0).Size(10).Query(query);
},
cancellationToken
);
EnsureSuccess(searchResponse);
return searchResponse.Documents;
}
}
In the code above we are performing full-text search on “Title” and “Content” fields and returning top 10 results.
And here is how to use it:
var posts = app.MapGroup("/posts");
posts
.MapGet(
"/search",
async (
[FromQuery(Name = "q")] string searchTerm,
ElasticClient elasticClient,
PostService postService,
CancellationToken cancellationToken
) =>
{
var posts = await elasticClient.SearchPostsAsync(
new() { Content = searchTerm, Title = searchTerm },
cancellationToken
);
IEnumerable<Post> result = [];
if (posts.Any())
{
result = await postService.GetPostsByIds(
posts.Select(x => x.Id),
cancellationToken
);
}
return TypedResults.Ok(result.ToPostViewModel());
}
)
.WithName("SearchPosts")
.WithTags(Tags)
.WithOpenApi();
The typical pattern in this scenario is to search for posts in Elasticsearch and retrieve the full representation from the primary database (MongoDB).
Analytics
Another interesting task that can be solved via Elasticsearch is analytics. Elasticsearch excels at analyzing large amounts of data. It provides real-time analytics, which means you can get insights from your data as soon as it is indexed. This is particularly useful for time-sensitive data or when you need to monitor trends, track changes, and make decisions quickly. Its powerful aggregation capabilities allow you to summarize, group, and calculate data on the fly, making it a great tool for both search and analytics.
Here is how to calculate Leader Board for the social media application:
public async Task<AnalyticsResponse> GetAnalyticsDataAsync(
AnalyticsRequest request,
CancellationToken cancellationToken = default
)
{
const string Key = "user_likes";
var aggregationResponse = await client.SearchAsync<IndexedLike>(
s =>
s.Index(LikeIndex)
.Size(0)
.Query(q =>
{
q.Range(r =>
r.DateRange(d =>
{
d.Gte(request.start.Value.ToString("yyyy-MM-dd"));
d.Lte(request.end.Value.ToString("yyyy-MM-dd"));
})
);
})
.Aggregations(a =>
a.Add(Key,
t => t.Terms(f => f.Field(f => f.AuthorId).Size(request.top)))),
cancellationToken
);
EnsureSuccess(aggregationResponse);
// processes aggregation result and returns UserId to NumberOfLikes dictionary
return new AnalyticsResponse(aggregationResponse);
}
And here is how to retrieve the users with the highest number of likes and enrich the data from the primary database:
posts
.MapPost(
"/analytics/leaderboard",
async (
[FromQuery(Name = "startDate")] DateTimeOffset? startDate,
[FromQuery(Name = "endDate")] DateTimeOffset? endDate,
ElasticClient elasticClient,
UsersDbContext usersDbContext,
CancellationToken cancellationToken
) =>
{
var analyticsData =
await elasticClient.GetAnalyticsDataAsync(new(startDate, endDate),cancellationToken);
var userIds = analyticsData
.Leaderboard.Keys.Select(x => x)
.ToList();
var users = await usersDbContext
.Users.Where(x => userIds.Contains(x.UserId))
.ToListAsync(cancellationToken: cancellationToken);
return TypedResults.Ok(
users
.Select(x => new
{
x.UserId,
x.Name,
x.Email,
LikeCount = analyticsData.Leaderboard[x.UserId],
})
.OrderByDescending(x => x.LikeCount)
);
}
)
.WithName("GetLeaderBoard")
.WithTags(Tags)
.WithOpenApi();
Putting everything together. Migration
The AppHost serves as the composition root of a distributed system, where high-level details about the system’s architecture and components are defined and configured.
In the AppHost, you can define and configure various components that make up the distributed system. These components can include databases, message brokers, caching systems, search engines, and other services that are required for the system to function.
As result, AppHost looks like following:
var builder = DistributedApplication.CreateBuilder(args);
var usersDb = builder
.AddPostgres("dbserver")
.WithDataVolume()
.WithPgAdmin(c => c.WithHostPort(5050))
.AddDatabase("users-db");
var postsDb = builder
.AddMongoDB("posts-mongodb")
.WithDataVolume()
.WithMongoExpress(c => c.WithHostPort(8081))
.AddDatabase("posts-db");
var elastic = builder
.AddElasticsearch("elasticsearch", port: 9200)
.WithDataVolume();
var redis = builder.AddRedis("cache");
var messageBus = builder
.AddRabbitMQ("messaging", port: 5672)
.WithDataVolume()
.WithManagementPlugin();
var api = builder
.AddProject<Projects.Api>("api")
.WithReference(usersDb)
.WithReference(postsDb)
.WithReference(elastic)
.WithReference(redis)
.WithReference(messageBus);
var migrator = builder
.AddProject<Projects.MigrationService>("migrator")
.WithReference(postsDb)
.WithReference(elastic)
.WithReference(usersDb);
builder.Build().Run();
As you can see, it quite easy to put everything together.
When working on a project, it is generally a good practice to maintain consistency in how you organize and structure your code. This includes how you reference and use resources within your project.
For example, we have the “migrator” service that references other resources in the same way as “api” service does.
Migration
The MigrationService is responsible for databases migration and seeding.
Here is how to generate test data:
private static (List<Post>, List<IndexedLike>) GeneratePosts()
{
var faker = new Faker<Post>()
.RuleFor(p => p.Title, f => f.Lorem.Sentence())
.RuleFor(p => p.Content, f => f.Lorem.Paragraph())
.RuleFor(p => p.ExternalId, f => f.Random.AlphaNumeric(10))
.RuleFor(p => p.CreatedAt, f => f.Date.Past())
.RuleFor(p => p.AuthorId, f => f.Random.Number(1, numberOfUsers));
var posts = faker.Generate(numberOfPosts).ToList();
var likeFaker = new Faker<IndexedLike>()
.RuleFor(l => l.PostId, f => f.PickRandom(posts).ExternalId)
.RuleFor(l => l.LikedBy, f => f.Random.Number(1, numberOfUsers))
.RuleFor(l => l.CreatedAt, f => f.Date.Past());
var likes = likeFaker
.Generate(numberOfLikes)
.GroupBy(l => l.PostId)
.ToDictionary(g => g.Key, g => g.ToList());
foreach (var post in posts)
{
var postLikes = likes.GetValueOrDefault(post.ExternalId) ?? [];
post.Likes.AddRange(postLikes.Select(x => x.LikedBy));
foreach (var l in postLikes)
{
l.AuthorId = post.AuthorId;
}
}
return (posts, likes.Values.SelectMany(x => x).ToList());
}
The migration process is instrumented via OpenTelemetry and you can inspect how much it takes to execute the migration and seeding process per-database.
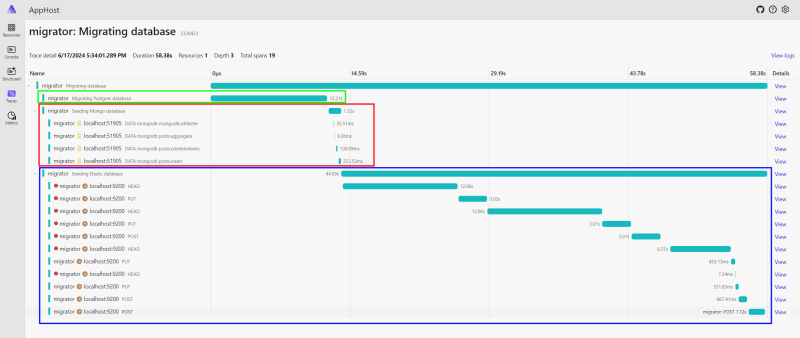
💡As you can see, it takes some time for Elasticsearch to boot up. This is one of the examples that demonstrate why it is important to use resiliency patterns to build more robust and reliable systems.
Conclusion
Polyglot persistence is a powerful approach to designing data storage solutions for applications. By leveraging the strengths of different databases, developers can build efficient and scalable systems that meet the specific requirements of their applications.
In this post, we explored how to implement polyglot persistence in a social media application using PostgreSQL, Redis, MongoDB, and Elasticsearch. Each database was used for a specific purpose, such as storing user data, caching, storing posts, and performing search and analytics tasks.
By carefully selecting the appropriate databases for each use case, developers can design robust and performant applications that deliver a great user experience. The flexibility and scalability provided by polyglot persistence enable applications to handle diverse workloads and data requirements, ensuring that they can grow and evolve over time.




Top comments (0)