
Nucleoid is a low-code framework, which tracks given statements in JavaScript and creates relationships between variables, objects, and functions etc. in the graph. So, as writing just like any other codes in Node.js, the runtime translates your business logic to fully working application by managing the JS state as well as storing in the built-in data store, so that your application doesn't require external database or anything else.


const nucleoid = require("nucleoidjs");
const app = nucleoid();
class Item {
constructor(name, barcode) {
this.name = name;
this.barcode = barcode;
}
}
nucleoid.register(Item);
// 👍 Only needed a business logic and 💖
// "Create an item with given name and barcode,
// but the barcode must be unique"
app.post("/items", (req) => {
const barcode = req.body.barcode;
const check = Item.find((i) => i.barcode === barcode);
if (check) {
throw "DUPLICATE_BARCODE";
}
return new Item(name, barcode);
});
app.listen(3000);
This is pretty much it, thanks to the Nucleoid runtime, only with this 👆, you successfully persisted your first object with the business logic 😎
What is the On-Chain Data Store?
One important objective of Nucleoid project is to combine logic and data under the same runtime. Nucleoid has a built-in on-chain data store persists sequent transactions with the blockchain style encryption. Each transaction is sequentially encrypted with each other and the data store saves those hashes in managed-files. Each transaction is completed in sub-millisecond and any changes in hashes throws an error so that the final state of objects is guaranteed, and objects cannot be visible without ordered hashes and the initial key.
Each call to the runtime is considered a transaction even though it contains multiple statements, and it rolls back the transaction if there is an error thrown.
nucleoid.run(() => {
a = 1;
b = a + 2;
c = b + 3;
});
The runtime returns something like this; result (if any), timestamp and a transaction hash.
{
"date": 1672179318252,
"time": 1,
"hash": "d3af6bdae8e8ff1eeb1f0f1ea8aaf02e:8b23f8ec493a16cee484f44a6e09a543a62b5e535b8c16ad5f8484766eed686d"
}
Important different is the on-chain data store doesn't store value, instead it persists transactions like in CQRS, Event Store etc. and it is expected that the runtime builds up values in memory along with. This algorithm provides fast-read and fast-write with larger space complexity as well as requiring computing values in memory at boot up as a trade off.
For example, this table is built in the memory as a part of transaction:
Values in Memory
| State | |
|---|---|
var a |
1 |
var b |
3 |
var c |
6 |
Transactions in Data Store
but actual the data store looks like this 👇 (This is decoded transaction objects though):
{ "s": "var a = 1" ... }
{ "s": "var b = a + 2" ... }
{ "s": "var c = b + 3" ... }
How is a hash generated?
The runtime uses the hard-coded genesis token as a first hash in the chain. As it receives more transactions, the data store uses the previous hash as well as the key to generate next hash in the chain. It uses Node.js built-in crypto package with a configurable algorithm.
Example of on-chain data in managed-files ~/.nuc/data/:
ff2024a65a339abd3c77bb069da38717:10812ca4ed497e3167684f9b0316b5cf72992adffd9ed8bd97e08f321e117daf367b012
a1a521479a43e1b16ce0ecc1671fbd8d:1ceb5211efadecc791c22a010752ecdf626764a71c4bc80c74f9d3ba6adb88d2e7cedcf
20033f1556383ce5b911436aa76381a8:543a50ae5072aa64acb0ef7c307aa53f3aaea042023704362305bedfafd721c9f918740
ee8a894958d4bb372d1a9e63335ccee7:4834d1e04e6b234135ae896c0057186df4c820b9b25fa6ce153e03f89c63b905208ba07
dc2d6d47071db41845fa8631b131bef5:0ec5427dd957ccb46fbd6884290eb0de9696102405fc606d2acf56e059ed3e827610e6a
3ef42a5927c4e231f17323619d6a60d1:e793031d12c9e5b10708c62d49a56c77fd9ef463606609036d22af83490106c213224e5
3a016c3e71238462f8b42ebb733e5856:cb1595d06424c7e1ec3c353f5eee2d6cf1b804306dcdadb09a6be9a066b89581270464d
Scalability
Nucleoid follows single-threaded multi-process paradigm. The sharding handler takes a JavaScript function and lets developers create own scalability policies. The function receives additional data such as request headers, body etc. and it also comes with Nucleoid runtime along with the built-in data store, so that the sharding function can persist user data in order to support memtable like in Cassandra.
npx nucleoidjs start --cluster
This npx command starts specialized Nucleoid instance and acts like a front door to the cluster. The default sharding function takes Process header from REST and looks up in process list for IP and port information, and cluster instances can be added with calling terminal with process1 = new Process("127.0.0.1", 8448).
The default function can be altered with including a function in ~/.nuc/handlers/cluster.js and returning process id from the function. For example:
// cluster.js
const jwt = require("jsonwebtoken");
function run(req, fn) {
const bearer = req.headers["authorization"];
const token = bearer.split();
const decoded = jwt.verify(token, "secret");
return decoded.company_id; // This returns company id as a process id
}
module.export = run;
Benchmark
This is the comparation our sample order app in Nucleoid IDE against MySQL and Postgres with using Express.js and Sequelize libraries.
https://nucleoid.com/ide/sample
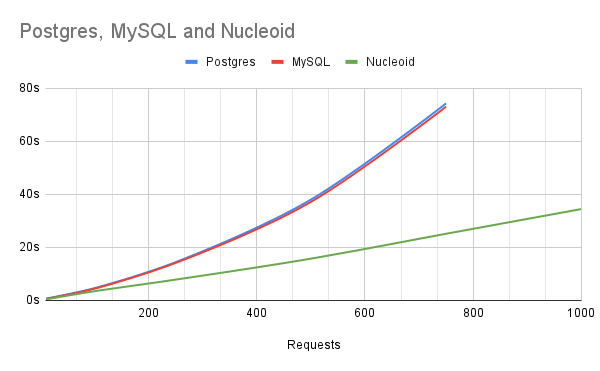
Performance benchmark is run in t2.micro of AWS EC2 instance and both databases had dedicated servers with no indexes and default configurations. For applications with average complexity, Nucleoid's performance is close to linear because of on-chain data store, in-memory computing model as well as limiting the IO process.
Thanks to declarative programming, we have a brand-new approach to data and logic. As we are still discovering what we can do with this powerful programming model, please join us with any types of contribution!
![]()





Top comments (1)
👏 great post!