Table of contents:
- We see the world from our perspective at a particular point in time, go to canonical section
- Websites as a content mashup, go to canonical section
- GraphQL as the content mesh composition tool, go to canonical section
- Asynchronous content mesh system for the Web, go to canonical section
After a year using GatsbyJS to build what I thought was a “simple static site”, I had a kerpow: GatsbyJS is NOT a static site generator, but an asynchronous content mesh system for the modern Web, powered by GraphQL. There were two concepts that together helped me realize that: content & time.
For those who don’t know what having a kerpow means (it’s a concept I’ve only come across recently), it means, in two simple words, “holy shit". Let me show you the path that brought me to the realization that I was not simply building a static site.
We see the world from our perspective at a particular point in time
If I look at how I’ve spent my time while using GatsbyJS during the last year, the most time (approximately 70%) was spent looking at JSX code, followed by looking at JSON (data), followed by looking at GraphQL queries, and finally, the least amount of time was spent looking at Node.js code. Bear in mind that this is not a very rigorous 1-year analysis.
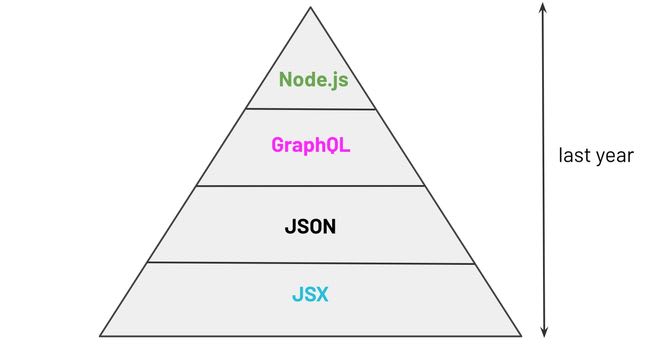
Distribution of code & time I’ve been dealing with while using GatsbyJS in the last year.
If your diagram would look similar to mine, you might also be under the impression that GatsbyJS is a static site generator. Whatever the case, feel free to tweet me if you want to share your experience :)
What was my main focus this year? We wanted our users to have the best user experience and we iterated this process for one year.
Interestingly, the more I reduce the span of time I analyse, and get closer to the present, the more the pyramid shifts. If I look at the past few weeks, the pyramid looks like this:

What has changed? I’ve focused on content, which gave me a new perspective. I believe our capacity to come to a realisation of something correlates to our exposure to it. Let me share with you what I’ve been exposed to recently, and how it made me change the way I think about GatsbyJS.
Websites as a content mashup

Websites as a content mashup is not a new thing. Ten years ago I was creating “widgets” using JSONP to display content from different sources on a website. The mashup concept has even made it to a prestigious dictionary:

In the past, the mashup was focused on the browser. Why? Because cross-domain requests were complicated, and we developers like complicated things. Just kidding 😜, I don’t know why 😄. What I do know is that the world has changed since then. For instance:
- There are many more APIs to pull content from.
- We’ve got better tooling to create that mashup.
- Ten years ago we had mainly desktops on the client and relatively expensive servers. Now we have a huge variety of devices and different types of networks, as well as cheap cloud computing, compared to the on-premise data centres we used to have to use.
An observation from reading the Cambridge Dictionary. It defines a mashup as using “from different websites”. I wouldn’t say that a headless CMS is a website, and neither is gatsby-image. So these days that definition doesn’t quite fit. The modern term is content mesh.
What I find very interesting is that now the mashup content mesh is created in different places, at different points in time. For instance, this page https://reactgraphql.academy/react/training/bootcamp/london/ uses two stages to pull data: 1) build time, and 2) client time.
Build time
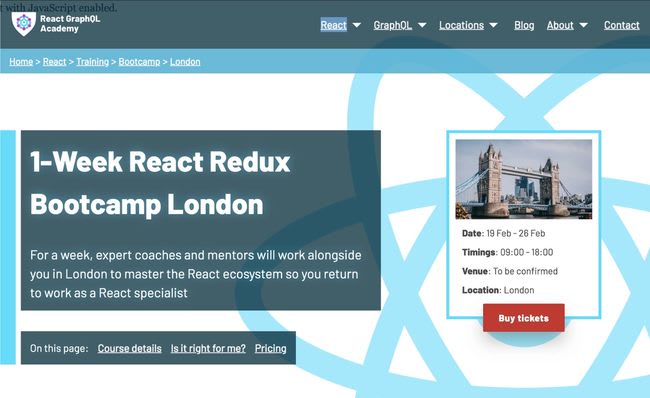
This is what you’ll see if you disable JavaScript on the browser and navigate to this link. What you see is the data that was pulled at build time, which is everything but the price. You see a landing page that explains a training, but you can’t actually buy the training instance yet. If you click on “Buy tickets” with JS disabled you’ll see the following:
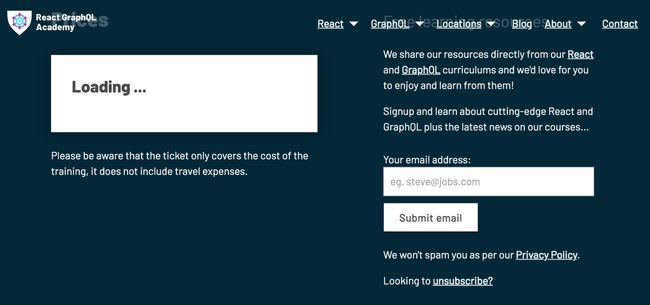
No matter how long you wait, no JavaScript, no price.
Client time

This is what you’ll see if you enable JavaScript on the browser, navigate to the same page, and click on the “Buy tickets” button at the top of the page. The browser will scroll down to the price section, and then you’ll be able to see the price at that point in time. The reason fetching the price is delayed until run-time being that the price depends on certain conditions, such as sales promotions, and if the course is sold out, or cancelled, there might be no tickets on sale.
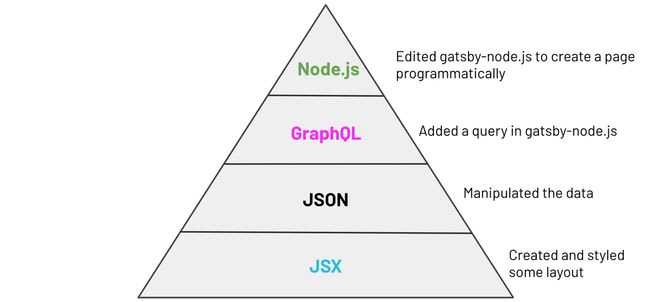
The following pyramid is an approximation of my time spent on building that page
GraphQL as the content mesh composition tool
Things changed when we decided to integrate this blog to a headless CMS. Prior to that, writing an article was a matter of writing some markdown, and merging a PR into master. The CI would then do the rest:
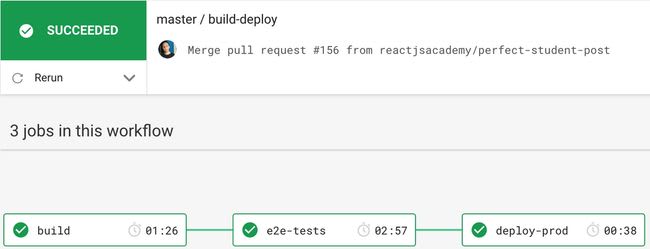
This blog post you are reading right now was created and published using Sanity.io (our headless CMS of choice). This CMS adds the following task to our workflow: posts are published on Sanity.io, and is subsequently available via an API. To be published doesn’t mean it’s displayed on the website. How do we display that post on the website? GatsbyJS plugins.
GatsbyJS plugins, the building blocks we can configure AND extend
GatsbyJS plugins are a very powerful way to source and/ or transform almost any kind of data in a GatsbyJS website. All the data in GatsbyJS become nodes in a graph. By using GraphQL to expose all the data GatsbyJS makes it very easy to query. Being able to easily query data is just the tip of the iceberg. GraphQL is a powerful mechanism to compose and extend data across all the plugins.
First, let me show you what I did to make all my CMS data available on my website. We can connect a GatsbyJS website to Sanity.io using the gatsby-source-sanity plugin. The following 5 lines of code gave me access to all my Sanity content at build time:
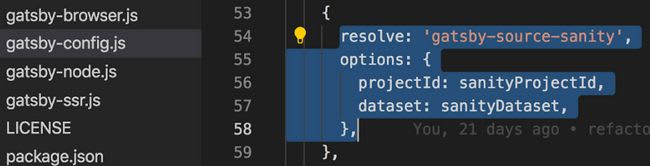
But I encountered a problem, that plugin didn’t have a feature I needed. I wanted to download images from Sanity.io at build time to my local so I could distribute them using my CDN of choice. Contentful (another headless CMS) provides a localFile field in their schema that implements that.
query MyQuery {
# Example is for a `ContentType` with a `ContentfulAsset` field
# You could also query an asset directly via
# `allContentfulAsset { edges{ node { } } }`
# or `contentfulAsset(contentful_id: { eq: "contentful_id here" } ) { }`
contentfulMyContentType {
myContentfulAssetField {
# Direct URL to Contentful CDN for this asset
file { url }
# Query for a fluid image resource on this `ContentfulAsset` node
fluid(maxWidth: 500){
...GatsbyContentfulFluid_withWebp
}
# Query for locally stored file(e.g. An image) - `File` node
localFile {
# Where the asset is downloaded into cache, don't use this
absolutePath
# Where the asset is copied to for distribution, equivalent to using ContentfulAsset `file {url}`
publicURL
# Use `gatsby-image` to create fluid image resource
childImageSharp {
fluid(maxWidth: 500) {
...GatsbyImageSharpFluid
}
}
}
}
}
https://www.gatsbyjs.org/packages/gatsby-source-contentful/#download-assets-for-static-distribution
Unfortunately, Sanity.io didn’t have that field in their GraphQL schema. One solution to this problem is to switch CMS. The problem with switching to another CMS is that it might take a considerable amount of effort and it doesn’t guarantee that the new one will provide all the functionality that I might need in the future. A better solution would be to extend the GraphQL schema and implement the use case I need. These were my requirements:
- Crop an image using Sanity cloud image service.
- Download the image from the Sanity CDN to my local machine at build time.
- Pipe the image file, downloaded at build time, to an ImageSharp type to get an ImageSharpFluid version of it.
- Pass the ImageSharpFluid data to a gatsby-image React component.
- Deploy images to my CDN of choice at build time.
- Download images from my CDN of choice at client time.
You might get lost with the terms and think it’s a lot of work, just bear with me for a second. My distribution of time/type of code to implement that:
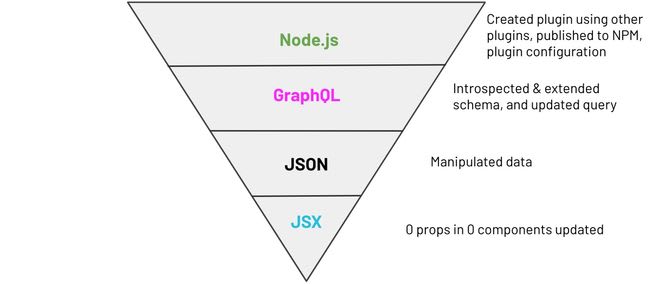
We can map that pyramid to the following code:
JSX, 0 props or JSX updated: https://github.com/reactgraphqlacademy/reactgraphqlacademy/blob/master/src/components/blog/PostCard.js#L24
JSON, manipulated data:
if (fluidImage) {
imageProps.fluid = fluidImage
} else {
imageProps.src = imageUrl
}
GraphQL, updated query:
fragment SanityPostItemFragment on SanityPost {
title
excerpt
category
mainImage {
asset {
localFile(width: 500, height: 333) {
publicURL
childImageSharp {
fluid {
...GatsbyImageSharpFluid
}
}
}
}
}
slug {
current
}
}
Node.js code:
To me, this is the most mind-blowing part. Only 61 lines of code (considering that we are using the verbose GraphQL JS reference implementation) to solve the whole problem by creating a plugin that extends another plugin (gatsby-source-sanity) using a third plugin (gatsby-source-filesystem) 🤯.
import { GraphQLInt, GraphQLString } from "gatsby/graphql";
import { createRemoteFileNode } from "gatsby-source-filesystem";
export const setFieldsOnGraphQLNodeType = ({ type }) => {
if (type.name === `SanityImageAsset`) {
return {
localFile: {
type: `File`,
args: {
width: {
type: GraphQLInt,
defaultValue: 600
},
format: {
type: GraphQLString,
defaultValue: "jpg"
},
height: {
type: GraphQLInt
},
fit: {
type: GraphQLString,
defaultValue: "crop"
}
}
}
};
}
// by default return empty object
return {};
};
export const createResolvers = ({
actions: { createNode },
cache,
createNodeId,
createResolvers,
store,
reporter
}) => {
const resolvers = {
SanityImageAsset: {
localFile: {
resolve: (source, { width, height, fit, format }) => {
return createRemoteFileNode({
url: `${source.url}?w=${width}&fm=${format}${
height ? `&h=${height}` : ""
}&fit=${fit}`,
store,
cache,
createNode,
createNodeId,
reporter
});
}
}
}
};
createResolvers(resolvers);
};
Asynchronous content mesh system for the Web
I submitted my plugin to the GatsbyJS plugin library following the GatsbyJS docs steps. Soon after I typed “sanity” on their plugin search input and there it was! Mmm, or it wasn’t?
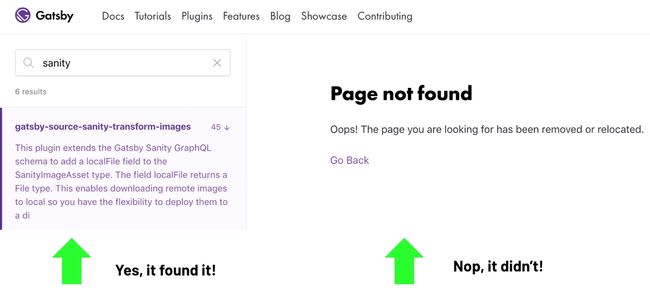
Then I read in their docs: “Algolia will take up to 12 hours to add it to the library search index (the exact time necessary is still unknown), and wait for the daily rebuild of https://gatsbyjs.org to automatically include your plugin page to the website.”
Algolia is a Software as a Service (SaaS) product that specializes in search and discovery. It took about an hour for Algolia to index my plugin. So after an hour, the plugin showed up in the search result. It took over a day for the GatsbyJS build to run again, and finish. That time in between the Algolia index and the GatsbyJS build I was in limbo, the technical name for which is 'eventual consistency’.
That’s not unique to Gatsbyjs.org. We have a similar issue in this blog. When we publish a blog post in Sanity.io, the post is immediately available on the API. Then we need to build the site. The time in between publishing and building, the editor is in limbo.
We can use webhooks to solve the issue. An editor publishes a document and then a webhook triggers a build. Unfortunately, I don’t think that’s currently cost-effective at scale.
With the battle for content very intense right now between so many players, maybe it’s time to start focusing on the next frontier: incremental build on the cloud.





Top comments (0)