In this article, we are going to learn how to create and explore the Frozen Lake environment using the Gym library, an open source project created by OpenAI used for reinforcement learning experiments. The Gym library defines a uniform interface for environments what makes the integration between algorithms and environment easier for developers. Among many ready-to-use environments, the default installation includes a text-mode version of the Frozen Lake game, used as example in our last post.
The Frozen Lake Environment
The first step to create the game is to import the Gym library and create the environment. The code below shows how to do it:
# frozen-lake-ex1.py
import gym # loading the Gym library
env = gym.make("FrozenLake-v0")
env.reset()
env.render()
The first instruction imports Gym objects to our current namespace. The next line calls the method gym.make() to create the Frozen Lake environment and then we call the method env.reset() to put it on its initial state. Finally, we call the method env.render() to print its state:

So, the same grid we saw in the previous post now is represented by a matrix of characters. Their meaning is as follows:
- S: initial state
- F: frozen lake
- H: hole
- G: the goal
- Red square: indicates the current position of the player
Also, we can inspect the possible actions to perform in the environment, as well as the possible states of the game:
# frozen-lake-ex1.py
print("Action space: ", env.action_space)
print("Observation space: ", env.observation_space)
In the code above, we print on the console the field action_space and the field observation_space. The returned objects are of the type Discrete, which describes a discrete space of size n. For example, the action_space for the Frozen Lake environment is a discrete space of 4 values, which means that the possible values for this space are 0 (zero), 1, 2 and 3. Yet, the observation_space is a discrete space of 16 values, which goes from 0 to 15. Besides, these objects offer some utility methods, like the sample() method which returns a random value from the space. With this method, we can easily create a dummy agent that plays the game randomly:
# frozen-lake-ex2.py
import gym
MAX_ITERATIONS = 10
env = gym.make("FrozenLake-v0")
env.reset()
env.render()
for i in range(MAX_ITERATIONS):
random_action = env.action_space.sample()
new_state, reward, done, info = env.step(
random_action)
env.render()
if done:
break
The code above executes the game for a maximum of 10 iterations using the method sample() from the action_space object to select a random action. Then the env.step() method takes the action as input, executes the action on the environment and returns a tuple of four values:
- new_state: the new state of the environment
- reward: the reward
- done: a boolean flag indicating if the returned state is a terminal state
- info: an object with additional information for debugging purposes
Finally, we use the method env.render() to print the grid on the console and use the returned "done" flag to break the loop. Notice that the selected action is printed together with the grid:

Stochastic vs Deterministic
Note in the previous output the cases in which the player moves in a different direction than the one chosen by the agent. This behavior is completely normal in the Frozen Lake environment because it simulates a slippery surface. Also, this behavior represents an important characteristic of real-world environments: the transitions from one state to another, for a given action, are probabilistic. For example, if we shoot a bow and arrow there's a chance to hit the target as well as to miss it. The distribution between these two possibilities will depend on our skill and other factors, like the direction of the wind, for example. Due to this probabilistic nature, the final result of a state transition does not depend entirely on the taken action.
By default, the Frozen Lake environment provided in Gym has probabilistic transitions between states. In other words, even when our agent chooses to move in one direction, the environment can execute a movement in another direction:
# frozen-lake-ex3.py
import gym
actions = {
'Left': 0,
'Down': 1,
'Right': 2,
'Up': 3
}
print('---- winning sequence ------ ')
winning_sequence = (2 * ['Right']) + (3 * ['Down'])
+ ['Right']
print(winning_sequence)
env = gym.make("FrozenLake-v0")
env.reset()
env.render()
for a in winning_sequence:
new_state, reward, done, info = env.step(actions[a])
print()
env.render()
print("Reward: {:.2f}".format(reward))
print(info)
if done:
break
print()
Executing the code above, we can observe different results and paths at each execution. Also, using the info object returned by the step method we can inspect the probability used by the environment to choose the executed movement:
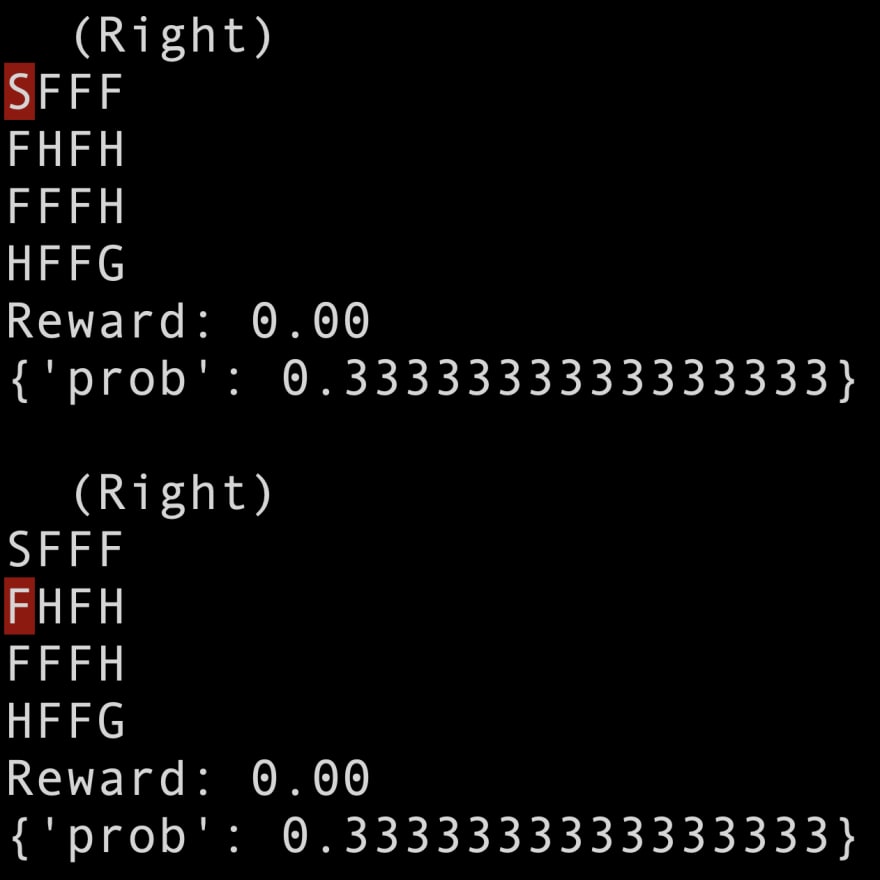
However, the Frozen Lake environment can also be used in deterministic mode. By setting the property is_slippery=False when creating the environment, the slippery surface is turned off and then the environment always executes the action chosen by the agent:
# frozen-lake-ex4.py
env = gym.make("FrozenLake-v0", is_slippery=False)
Observe that the probabilities returned in the info object is always equals to 1.0.

Map sizes and custom maps
The default 4x4 map is not the only option to play the Frozen Lake game. Also, there's an 8x8 version that we can create in two different ways. The first one is to use the specific environment id for the 8x8 map:
# frozen-lake-ex5.py
env = gym.make("FrozenLake8x8-v0")
env.reset()
env.render()
The second option is to call the make method passing the value "8x8" as an argument to the map_name parameter:
# frozen-lake-ex5.py
env = gym.make('FrozenLake-v0', map_name='8x8')
env.reset()
env.render()
And finally, we can create our custom map of the Frozen Lake game by passing an array of strings representing the map as an argument to the parameter desc:
custom_map = [
'SFFHF',
'HFHFF',
'HFFFH',
'HHHFH',
'HFFFG'
]
env = gym.make('FrozenLake-v0', desc=custom_map)
env.reset()
env.render()
Conclusion
In this post, we learned how to use the Gym library to create an environment to train a reinforcement learning agent. We focused on the Frozen Lake environment, a text mode game with simple rules but that allows us to explore the fundamental concepts of reinforcement learning.
References
A brief introduction to reinforcement learning concepts can be found at How AI Learns to Play Games. The Frozen Lake game rules and fundamental concepts of reinforcement learning can be found at Introduction to Reinforcement Learning: the Frozen Lake Example. Finally, you find instructions on how to install the Gym environment, check the post How to Install Gym.
Finally, the code examples for this post can be found at https://github.com/rodmsmendes/reinforcementlearning4fun/tree/master/gym-tutorial-frozen-lake.
Originally published at Gym Tutorial: The Frozen Lake





Top comments (1)
Good.