![Cover image for [IoT - Drones] Preparando a ingestão de dados através do Filebeat- Episódio 3](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fn6y1c34i33y1kdpw34j5.png)
A Internet das Coisas (IoT) e drones estão se tornando cada vez mais populares e amplamente utilizados em muitas indústrias. A combinação de IoT e drones permite a coleta de dados em tempo real, o que é útil para análises e tomada de decisões. No entanto, armazenar e processar esses dados em grandes volumes pode ser um desafio. Aqui, mostraremos como preparar a ingestão de dados MQTT no Elasticsearch para simplificar esse processo.
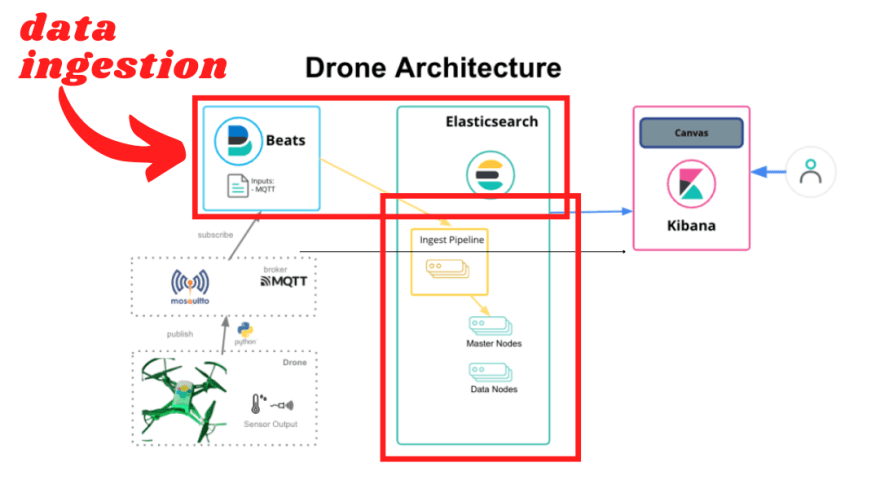
Todo o processo para configurar o MQTT broker, foi definido no episódio anterior.
Para executar essa tarefa de ingestão de dados publicados no MQTT broker, vamos utilizar o Filebeat. Instalar e configurar o Filebeat é uma tarefa simples, mas é importante seguir alguns passos para garantir que tudo esteja funcionando corretamente.
Passo 1 - Instalar e configurar Filebeat
O Filebeat pode ser instalado de acordo com as instruções da documentação oficial. Em nosso caso, estamos usando a versão Cloud da Elastic.
A seguir, precisamos dizer ao Filebeat que gostaríamos de nos inscrever no tópico o qual conterá os dados publicados pelo drone.
Edite o arquivo filebeat.yml na seção inputs, como mostrado a seguir:
filebeat.inputs:
#--- drone
- type: mqtt
hosts:
- tcp://ec2-18-204-19-124.compute-1.amazonaws.com:1883
topics:
- drones/drone01
tags:
["advent_calendar"]
fields:
fleet_id: "drone"
fields_under_root: true
Passo 2 - Recebendo e transformando os dados dentro do Elasticsearch
A partir do momento em que o Beat se inscreve no tópico "drones/drone01" do MQTT, toda vez em que alguém publicar informações no mesmo (no caso, o nosso drone), o processo de ingestão de dados é acionado. A telemetria inicial publicada pelo drone, envia dados dos sensores no formato JSON. Dessa forma, criamos um pipeline de ingestão para que transforma os atributos do JSON em campos no nosso índice dentro do Elasticsearch. Seguindo a documentação, no menu "Stack Management>Ingest Pipelines>Create Pipelines"
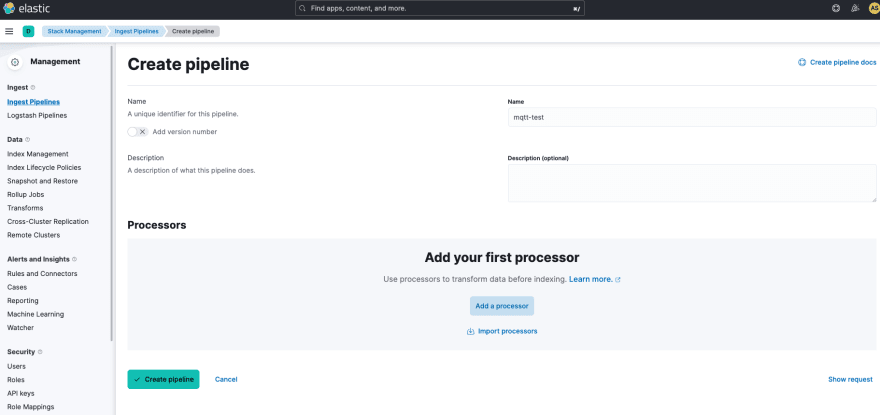
Após nomear o seu pipeline, "mqtt-test", clique em "Add processor" para definir a regra do parser.

Em nosso caso, desejamos extrair os atributos do campo "message" que está no formato JSON e transformá-los em campos do próprio índice com prefixo "data-drone". Clique em "Add" para adicionar nosso processor e em seguida "Create Pipeline".
Como vocês sabem, existem várias formas de resolver problemas semelhantes no Elastic, é uma questão de arquitetura, performance, etc. Neste caso, por exemplo, poderíamos configurar um script no próprio Filebeat, mas para me beneficiar da UI e ilustrar melhor o funcionamento do processor, resolvi utilizar esta opção dentro do próprio Elasticsearch. Qual outra opção você usaria?
Criamos então o nosso pipeline "mqtt-test" :
[
{
"json": {
"field": "message",
"target_field": "drone-data"
}
}
]
Precisamos agora dizer ao Filebeat que acione esse pipeline após a ingestão dos dados do drone. Fazemos isso editando o arquivo filebeat.yml na seguinte seção:
output.elasticsearch:
indices:
- index: "my-mqtt-%{[agent.version]}-%{+yyyy.MM.dd}"
pipeline: mqtt-test
Passo 3 - Reinicie o Filebeat
Depois de ter configurado o Filebeat para usar o pipeline de ingestão de dados, é necessário reiniciar o Filebeat para que as alterações tenham efeito.
Com estes passos, o Filebeat estará configurado para usar o pipeline de ingestão de dados do Elasticsearch para transformar os dados recebidos em campos separados no índice do Elasticsearch. Verifique o log do Filebeat periodicamente para garantir que tudo esteja funcionando corretamente e para resolver quaisquer problemas que possam ocor
Pronto, tudo configurado, hora de testar. atento ao próximo episódio :)
Abraços!
Este é o terceiro capítulo da série [IoT Drones]. Caso tenha perdido algum episódio anterior, não se preocupe, confira a lista abaixo para acompanhar a série completa.





Top comments (0)