
Finally, the machine learning tool is open sourced at serpapi/automatic-images-classifier-generator. Feel free to use, contribute, and have fun.
Generate machine learning models fully automatically to classify any images using SERP data
automatic-images-classifier-generator is a machine learning tool written in Python using SerpApi, Pytorch, FastAPI, and Couchbase to provide automated large dataset creation, automated training and testing of deep learning models with the ability to tweak algorithms, storing the structure and results of neural networks all in one place.
Disclaimer: This open-source machine learning software is not one of the product offerings provided by SerpApi. The software is using one of the product offerings, SerpApi’s Google Images Scraper API to automatically create datasets. You may register to SerpApi to claim free credits. You may also see the pricing page of SerpApi to get detailed information.
- Machine Learning Tools and Features provided by
automatic-images-classifier-generator - Installation
- Basic Usage of Machine Learning Tools
- Adding SERP Images to Storage Server
- Training a Model
- Testing a Model
- Getting Information on the Training and Testing of the Model
- Support for Various Elements
- Keypoints for the State of the Machine Learning Tool and Its Future Roadmap
Machine Learning Tools and Features provided by automatic-images-classifier-generator
Machine Learning Tools for automatic large image datasets creation powered by SerpApi’s Google Images Scraper API
Machine Learning Tools for automatically training deep learning models with customized tweaks for various algorithms
Machine Learning Tools for automatically testing machine learning models
Machine Learning Tools for customizing nodes within pipelines of ml models, changing dimensionality of machine learning algorithms, etc.
Machine Learning Tools for keeping the record of the training losses, employed datasets, structures of neural networks, and accuracy reports
Async Training and Testing of Machine Learning Models
Delivery of data necessary to create a visualization for cross-comparing different machine learning models with subtle changes in their neural network structure.
Various shortcuts for preprocessing with targeted data mining of SERP data
Installation
1) Clone the repository
gh repo clone serpapi/automatic-images-classifier-generator
2) Open a SerpApi Account (Free Credits Available upon Registration)
3) Download and Install Couchbase
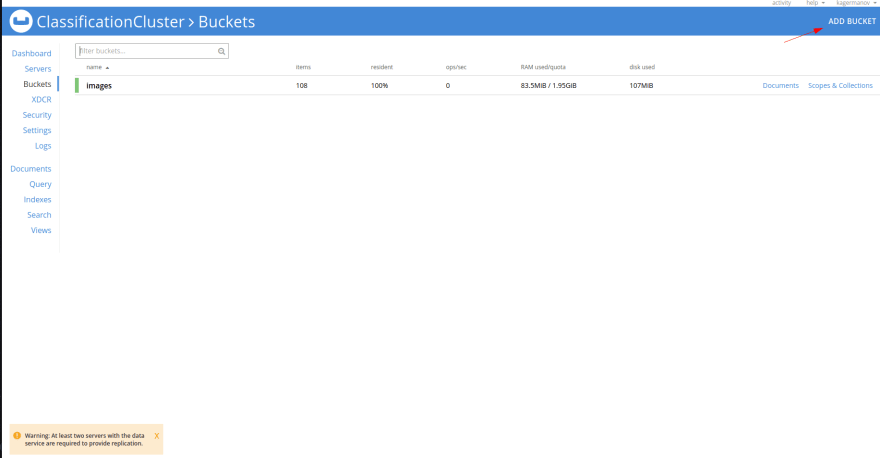
4) Head to Server Dashboard URL (Ex: http://kagermanov:8091), and create a bucket named images
5) Install required Python Libraries
pip install -r requirements.txt
6) Fill credentials.py file with your server credentials, and SerpApi credentials
7) Run Setup Server File
python setup_server.py
8) Run the FastAPI Server
uvicorn main:app --host 0.0.0.0 --port 8000
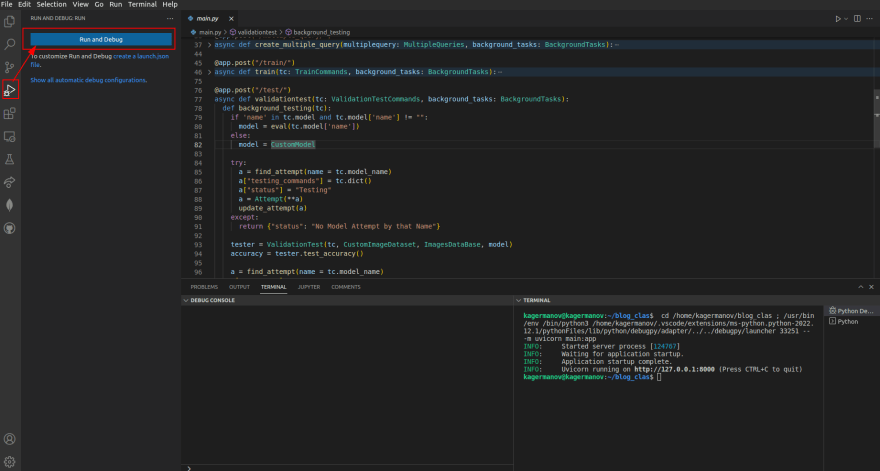
or you may simply use a debugging server by clicking on main.py and running a degugging server:
9) Optionally run the tests:
pytest test_main.py
Basic Usage of Machine Learning Tools
1) Head to localhost:8000/docs
2) Use add_to_db endpoint to call to update image database
3) Use train endpoint to train a model. The trained model will be saved on models folder when the training is complete. The training is an async process. Keep an eye out for terminal outputs for the progression.
4) Use test endpoint to test a model.
5) Use find_attempt endpoint to fetch the data on the training and testing process (losses at each epoch, accuracy etc.)
Adding SERP Images to Storage Server
add_to_db
User can make singular searches with SerpApi Images Scraper API, and automatically add them to local image storage server.
multiple_query
User can make multiple searches with SerpApi Images Scraper API, and automatically add them to local image storage server.
Training a Model
User can train a model with a customized dictionary from train endpoint.
train
Tips for Criterion
-
criterionkey is responsible for calling a loss function. - If user only provides the name of the criterion(loss function), it will be used without parameters.
- Some string inputs(especially if the user calls an external class from Pytorch), should be double quoted like
"'Parameter Value'". - User may find the information on the support for Loss Functions later in the documentation.
Tips for Optimizer
-
optimizerkey is responsible for calling an optimizer. - If user only provides the name of the optimizer, it will be used without parameters.
- Some string inputs(especially if the user calls an external class from Pytorch), should be double quoted like
"'Parameter Value'". - User may find the information on the support for Optimizers later in the documentation.
Tips for Image Operations (PIL Image Functions)
-
image_opskey is responsible for calling PIL operations on the input. - PIL integration is only supportive for Pytorch Transforms(
transform,target_transformkeys) integration. It should be used for secondary purposes. Many of the functions PIL supports is already wrapped in Pytorch Transforms. - Each dictionary represents a separate operation.
- Some string inputs(especially if user calls an external class from PIL), should be double quoted like
"'Parameter Value'" - User may find the information on the support for Optimizers later in the documentation.
Tips for Pytorch Transforms
-
transformandtarget_transformkeys are both responsible calling Pytorch Transforms. First one is for input, the second one is for label respectively. - Transforms integration is the main integration responsible for preprocessing images, and labels before training.
- Each key in the dictionary represents a separate operation.
- Order of the keys represent the order of sequential transforms to be applied.
- Transforms without a parameter should be given the value
Trueto be passed. - Some string inputs(especially if the user calls an external class from Pytorch), should be double quoted like
"'Parameter Value'" - User may find the information on the support for Transforms later in the documentation.
Tips for Label Names
-
label_namesis responsible for declaring label names. - Label Names should be present in the Image Database Storage Server created by the user.
- If the user provided
heightandwidthof images to be scraped inadd_to_dbormultiple_queriesendpoints, the label name should be written with an addendumimagesize:heightxwidth. Otherwise the images without certain classification will be fetched if they are present in the server. - Vectorized versions of labels could be transformed using
target_transform
Tips for Model
-
modelkey is responsible for the calling or creation of a model. - If
namekey is provided, a previously defined class name withinmodels.pywill be called, andlayerskey will be ignored. - If
layerskey is provided, andnamekey is not provided, a sequential layer creation will follow. - Each dictionary in the
layersarray represents a training layer. - User may use
autovalue for the input parameter to automatically get the past output layer in a limited support. For now, it is only supported for same kinds of layers. - User may use
n_labelsto indicate the number of labels in the final layer. - User may find the information on the support for Layers later in the documentation.
Testing a Model
test
User may test the trained model by fetching random images that have the same classifications as labels.
Getting Information on the Training and Testing of the Model
find_attempt
Each time a user uses train endpoint, an Attempt object is created in the database. This object is also updated on each time test endpoint is used. Also, user may automatically check the status of the training from this object.
- At the beginning of each training, the
statusof the object will beTraining. - At the end of each training, the
statusof the object will beTrained - At the end of each testing, the
statusof the object will beComplete
Support for Various Elements
Below are the different functions, and algorithms supported. Data has been derived from the results of test_main.py unit tests. Functions, and algorithms not present in the list may or may not work. Feel free to try them out.
Keypoints for the State of the Machine Learning Tool and Its Future Roadmap
For now, the scope of this software only supports image datasets, and the aim is to create image-classifying machine learning models at scale. The broader purpose is to achieve better computer vision by scalability. Future plans include adding the other basic input tensor types for data science, data analysis, data analytics, or artificial intelligence projects. The open source software could be repurposed to achieve other kinds of tasks such as regression, natural language processing, or any other popular machine learning use cases.
There are no future plans to support any other programming languages such as Java, Javascript, C/C++, etc. The only supported language will be Python for the foreseeable future. The ability to support other efficient databases on big data such as SQL on Hadoop could be a topic for discussion. Also, the ability to add multiple images from local storage to the storage server is in the future plans.
The only Machine Learning framework supported is Pytorch. There are plans to extend support for some other machine learning libraries and software such as Tensorflow, Keras, Scikit-Learn, Apache Spark, Scipy, Apache Mahout, Accord.NET, Weka, etc. in the future. Already used libraries such as google-image-results, NumPy, etc. may be utilized further in the future.
To keep the software user-friendly, the device to train the model on (GPU(CUDA), or CPU) is automatically selected. Also, there are plans to create data visualizations of different models in interactive graphs that can be understood by seasoned data scientists or beginners alike in the future. The drag-and-drop type machine learning software libraries for model creation are not anticipated to be implemented.
This is open-source software designed for local use. The effects or cost of deployment to cloud servers such as AWS, Google Cloud, etc., or integrating it for machine learning applications with the cloud solutions such as Amazon Sagemaker, IBM Watson, Microsoft’s Azure Machine Learning, and Jupyter Notebook hasn’t been tested yet. Use it at your own discretion. The future plans include some of the large-scale ml tools to be implemented.
The workflows for future plans above may or may not be implemented depending on the schedule of events, support from other contributors, and its overall use in automation. Multiple machine learning projects with a tutorial will be released explaining machine learning tools.
Conclusion
I am grateful to the readers for their attention, and Brilliant People of SerpApi for making this blog post possible. In the coming weeks, we will embark for a basic open source client tool that is not using any storage database, but using automatic-images-classifier-generator at its core.



Top comments (0)