
What will be scraped

Preparation
First, we need to create a Node.js* project and add npm packages cheerio to parse parts of the HTML markup, and axios to make a request to a website. To do this, in the directory with our project, open the command line and enter npm init -y, and then npm i cheerio axios.
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
Process
SelectorGadget Chrome extension was used to grab CSS selectors by clicking on the desired element in the browser which then returns a matched CSS selector. If you have any struggles understanding this, we have a dedicated Web Scraping with CSS Selectors blog post at SerpApi.
The GIF below illustrates the approach of selecting different HTML elements using SelectorGadget to get a CSS selector which we'll be calling using cheerio.
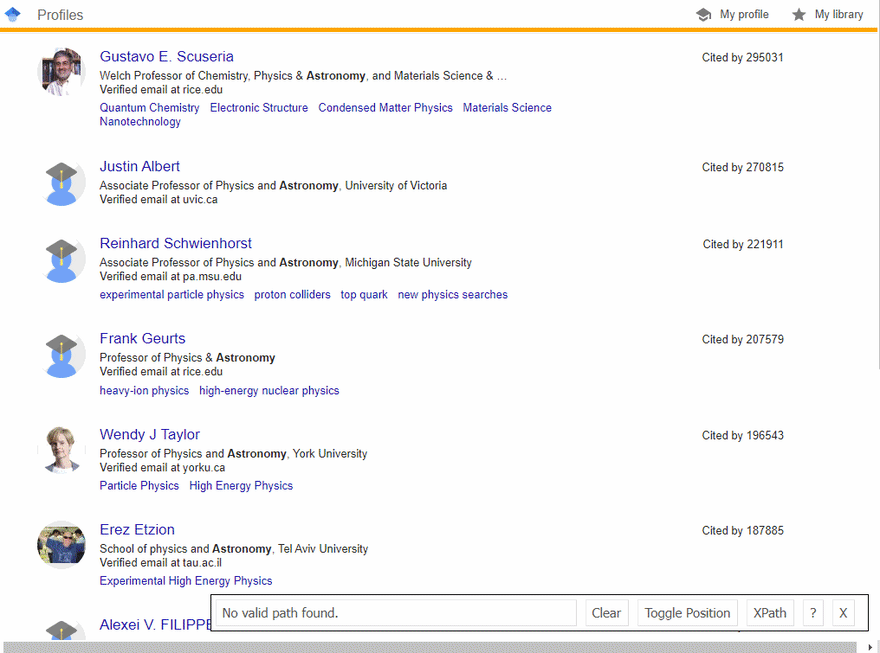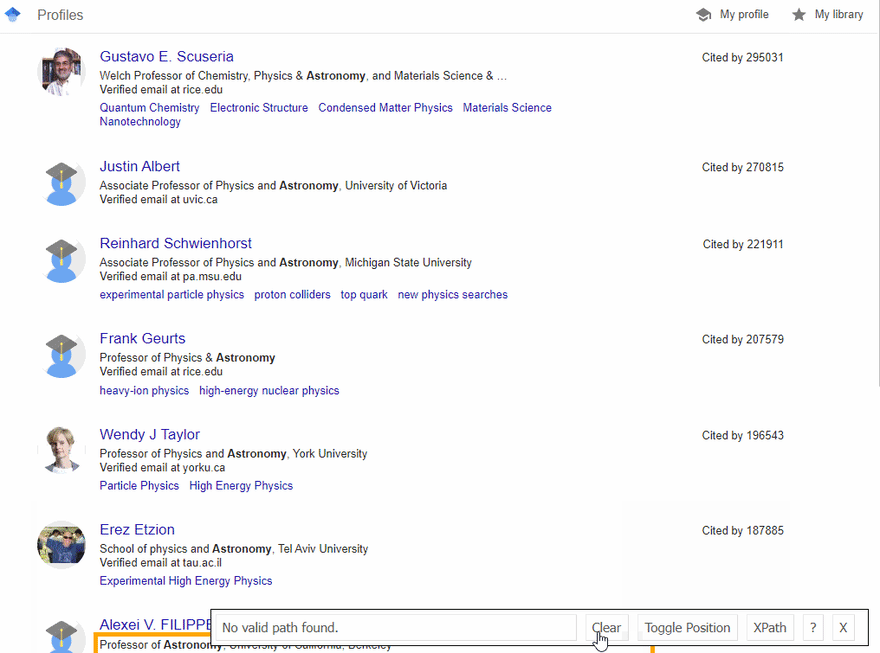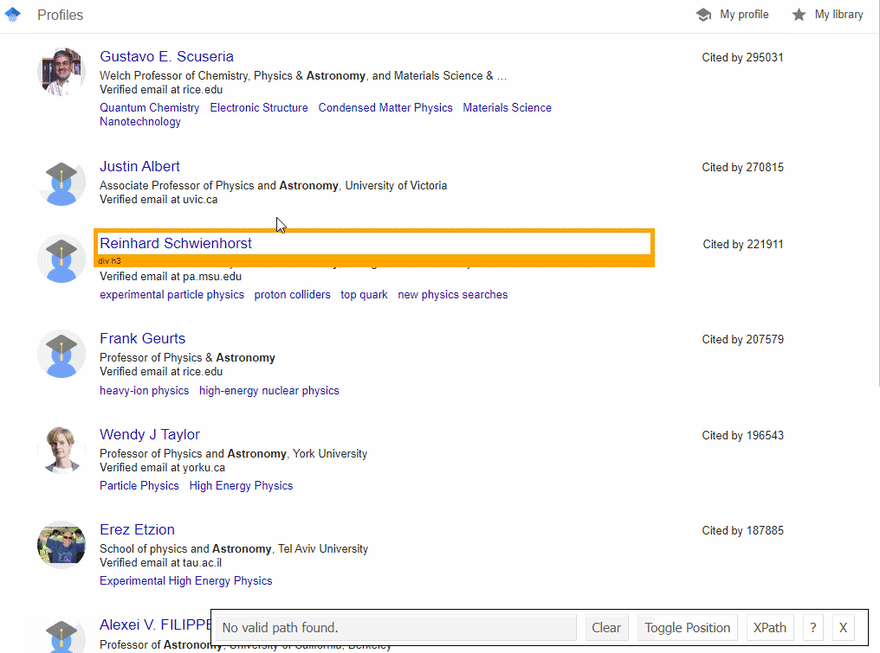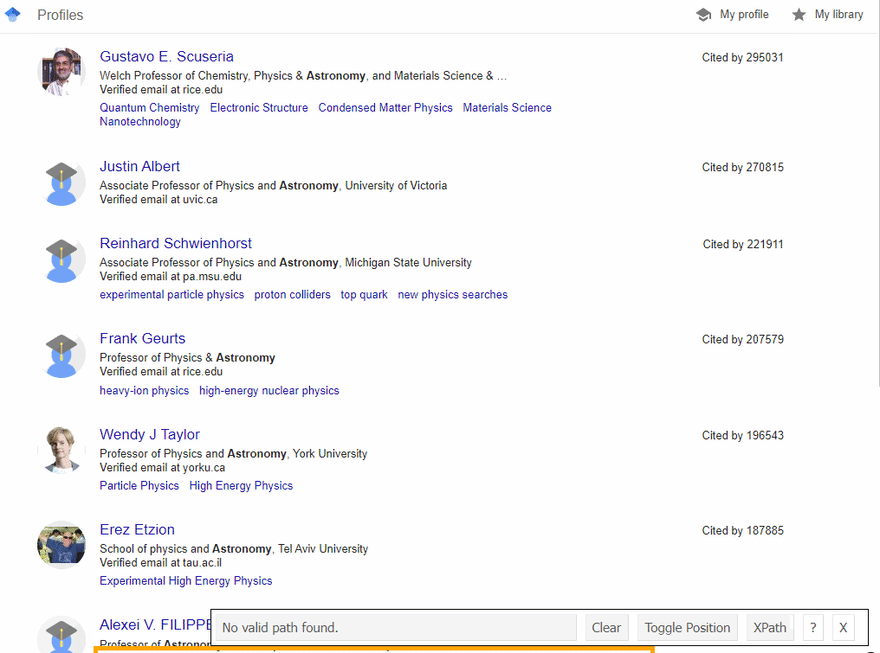
Full code
const cheerio = require("cheerio");
const axios = require("axios");
const searchString = "astronomy"; // what we want to search
const encodedString = encodeURI(searchString); // what we want to search for in URI encoding
const pagesLimit = Infinity; // limit of pages for getting info
const domain = `http://scholar.google.com`;
const AXIOS_OPTIONS = {
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
}, // adding the User-Agent header as one way to prevent the request from being blocked
params: {
mauthors: encodedString, // our encoded search string
hl: "en", // parameter defines the language to use for the Google search
view_op: "search_authors", // parameter defines what kind of search we want to use
},
};
function buildValidLink(rawLink) {
if (!rawLink) return "link not available";
return domain + rawLink;
}
function getHTML(link, options = AXIOS_OPTIONS.headers) {
return axios.get(link, options).then(function ({ data }) {
return cheerio.load(data);
});
}
function fillProfilesData($) {
const profiles = Array.from($(".gsc_1usr")).map((el) => {
const link = buildValidLink($(el).find(".gs_ai_name a").attr("href"));
const authorIdPattern = /user=(?<id>[^&]+)/gm //https://regex101.com/r/oxoQEj/1
const authorId = link.match(authorIdPattern)[0].replace('user=', '')
return {
name: $(el).find(".gs_ai_name a").text().trim(),
link,
authorId,
photo: $(el).find(".gs_ai_pho img").attr("src"),
affiliations: $(el).find(".gs_ai_aff").text().trim().replace("\n", ""),
email: $(el).find(".gs_ai_eml").text().trim() || "email not available",
cited_by: $(el).find(".gs_ai_cby").text().trim(),
interests: Array.from($(el).find(".gs_ai_one_int")).map((interest) => {
return {
title: $(interest).text().trim(),
link: buildValidLink($(interest).attr("href")),
};
}),
};
});
const isNextPage = buildValidLink(
$(".gs_btnPR:not([disabled])")
?.attr("onclick")
?.replace("window.location='", "")
.replaceAll("'", "")
.replaceAll("\\x3d", "=")
.replaceAll("\\x26", "&")
);
return { profiles, isNextPage };
}
function getScholarProfilesInfo(link) {
if (!link) {
return getHTML(`${domain}/citations`, AXIOS_OPTIONS).then(fillProfilesData);
} else {
return getHTML(link).then(fillProfilesData);
}
}
async function startScrape() {
const allProfiles = [];
let nextPageLink;
let currentPage = 1;
while (true) {
const data = await getScholarProfilesInfo(nextPageLink);
allProfiles.push(...data.profiles);
nextPageLink = data.isNextPage;
currentPage++;
if (nextPageLink === "link not available" || currentPage > pagesLimit) break;
}
return allProfiles;
}
startScrape().then(console.log);
Code explanation
Declare constants from required libraries:
const cheerio = require("cheerio");
const axios = require("axios");
| Code | Explanation |
|---|---|
cheerio |
library for parsing the html page and access the necessary selectors |
axios |
library for requesting the desired html document |
Next, we write in constants what we want to search for and encode our text into a URI string:
const searchString = "astronomy";
const encodedString = encodeURI(searchString);
const pagesLimit = Infinity;
| Code | Explanation |
|---|---|
searchString |
what we want to search |
encodedString |
what we want to search for in URI encoding |
pagesLimit |
limit of pages for getting info. If you want to limit the number of pages for getting info you need to define the last page number in this |
Next, we write down the necessary parameters for making a request:
const AXIOS_OPTIONS = {
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36",
},
params: {
mauthors: encodedString,
hl: "en",
view_op: "search_authors",
},
};
| Code | Explanation |
|---|---|
headers |
HTTP headers let the client and the server pass additional information with an HTTP request or response |
User-Agent |
is used to act as a "real" user visit. Default axios requests user-agent is axios/0.27.2 so websites understand that it's a script that sends a request and might block it. Check what's your user-agent. |
mauthors |
encoded in URI search query |
hl |
parameter defines the language to use for the Google search |
view_op |
parameter defines what kind of search we want to use |
Next, we write a function that helps us change the raw links to the correct links. We need to do this with links because some of them start with "/citations" and some don't have links:
function buildValidLink(rawLink) {
if (!rawLink) return "link not available";
return domain + rawLink;
}
Next, we write a function that helps us get request data with axios and return this data parsed with cheerio:
function getHTML(link, options = AXIOS_OPTIONS.headers) {
return axios.get(link, options).then(function ({ data }) {
return cheerio.load(data);
});
}
| Code | Explanation |
|---|---|
function ({ data }) |
we received the response from axios request that have data key that we destructured (this entry is equal to function (response) and in the next line cheerio.load(response.data)) |
Next, we write down a function for getting information from page:
function fillProfilesData($) {
const profiles = Array.from($(".gsc_1usr")).map((el) => {
const link = buildValidLink($(el).find(".gs_ai_name a").attr("href"));
const authorIdPattern = /user=(?<id>[^&]+)/gm
const authorId = link.match(authorIdPattern)[0].replace('user=', '')
return {
name: $(el).find(".gs_ai_name a").text().trim(),
link,
authorId,
photo: $(el).find(".gs_ai_pho img").attr("src"),
affiliations: $(el).find(".gs_ai_aff").text().trim().replace("\n", ""),
email: $(el).find(".gs_ai_eml").text().trim() || "email not available",
cited_by: $(el).find(".gs_ai_cby").text().trim(),
interests: Array.from($(el).find(".gs_ai_one_int")).map((interest) => {
return {
title: $(interest).text().trim(),
link: buildValidLink($(interest).attr("href")),
};
}),
};
});
const isNextPage = buildValidLink(
$(".gs_btnPR:not([disabled])")
?.attr("onclick")
?.replace("window.location='", "")
.replaceAll("'", "")
.replaceAll("\\x3d", "=")
.replaceAll("\\x26", "&")
);
return { profiles, isNextPage };
}
| Code | Explanation |
|---|---|
profiles |
an array with profiles results from page |
.attr('href') |
gets the href attribute value of the html element |
authorIdPattern |
a RegEx pattern for search and define author id. See what it allows you to find |
link.match(pattern)[0].replace('user=', '') |
in this line, we find a substring that matches authorIdPattern, take 0 element from the matches array and remove "user=" part |
$(el).find('.gs_ai_aff') |
finds element with class name gs_ai_aff in all child elements and their children of el html element |
.text() |
gets the raw text of html element |
.trim() |
removes whitespace from both ends of a string |
replace('\n', '') |
in this code we remove new line symbol |
$(".gs_btnPR:not([disabled])") |
in this code we find an html element with class name .gs_btnPR which doesn't have attribute disabled
|
replaceAll("\\x3d", "=") |
in this code we replace all \\x3d symbols to = symbol |
Next, we write down a function for making the first request (when link is not defined) and all other requests:
function getScholarProfilesInfo(link) {
if (!link) {
return getHTML(`${domain}/citations`, AXIOS_OPTIONS).then(fillProfilesData);
} else {
return getHTML(link).then(fillProfilesData);
}
}
And finally, a function to get the necessary information from each page and put it in an array:
async function startScrape() {
const allProfiles = [];
let nextPageLink;
let currentPage = 1;
while (true) {
const data = await getScholarProfilesInfo(nextPageLink);
allProfiles.push(...data.profiles);
nextPageLink = data.isNextPage;
currentPage++;
if (nextPageLink === "link not available" || currentPage > pagesLimit) break;
}
return allProfiles;
}
| Code | Explanation |
|---|---|
allProfiles |
an array with profiles results from page |
nextPageLink |
we write a variable that is not defined for the first run in the loop, and then we write a link to the next page in it |
currentPage |
the current page number need if we set pagesLimit
|
allProfiles.push(...data.profiles) |
here, we use spread syntax to split the array data.profiles into elements and add them in the end of allProfiles array |
if (nextPageLink === "link not available" ┃┃ currentPage > pagesLimit) break |
in this line of code, we check that nextPageLink is equal to "link not available" or that currentPage is less than pagesLimit (that's need if we set pagesLimit). And if the expression in brackets is true we run break which ends the loop |
Now we can launch our parser. To do this enter node YOUR_FILE_NAME in your command line. Where YOUR_FILE_NAME is the name of your .js file.
Output
📌Note: if you see something like [Object] in your console you can use console.dir(result, { depth: null }) instead console.log(). Watch Node.js documentation for more info.
[
{
"name":"Gustavo E. Scuseria",
"link":"http://scholar.google.com/citations?hl=en&user=6ZiRSwQAAAAJ",
"photo":"https://scholar.googleusercontent.com/citations?view_op=small_photo&user=6ZiRSwQAAAAJ&citpid=2",
"affiliations":"Welch Professor of Chemistry, Physics & Astronomy, and Materials Science & …",
"email":"Verified email at rice.edu",
"cited_by":"Cited by 295031",
"interests":[
{
"title":"Quantum Chemistry",
"link":"http://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:quantum_chemistry"
},
{
"title":"Electronic Structure",
"link":"http://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:electronic_structure"
},
{
"title":"Condensed Matter Physics",
"link":"http://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:condensed_matter_physics"
},
{
"title":"Materials Science",
"link":"http://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:materials_science"
},
{
"title":"Nanotechnology",
"link":"http://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:nanotechnology"
}
]
},
...and other results
]
Google Scholar Profiles API
Alternatively, you can use the Google Scholar Profiles API from SerpApi. SerpApi is a free API with 100 search per month. If you need more searches, there are paid plans.
The difference is that you won't have to write code from scratch and maintain it. You may also experience blocking from Google and changing the selected selectors. Using a ready-made solution from SerpAPI, you just need to iterate the received JSON. Check out the playground.
First we need to install google-search-results-nodejs. To do this you need to enter in your console: npm i google-search-results-nodejs
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY); //your API key from serpapi.com
const searchString = "astronomy"; // what we want to search
const pagesLimit = Infinity; // limit of pages for getting info
let currentPage = 1; // current page of the search
const params = {
engine: "google_scholar_profiles", // search engine
mauthors: searchString, // search query
hl: "en", // Parameter defines the language to use for the Google search
};
const getScholarProfilesData = function ({ profiles }) {
return profiles.map((result) => {
const { name, link = "link not available", author_id, thumbnail, affiliations, email = "no email info", cited_by, interests } = result;
return {
name,
link,
author_id,
photo: thumbnail,
affiliations,
email,
cited_by,
interests:
interests?.map((interest) => {
const { title, link = "link not available" } = interest;
return {
title,
link,
};
}) || "no interests",
};
});
};
const getJson = (params) => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const profilesResults = [];
let nextPageToken;
while (true) {
if (currentPage > pagesLimit) break;
const json = await getJson(params);
nextPageToken = json.pagination.next_page_token;
params.after_author = nextPageToken;
profilesResults.push(...(await getScholarProfilesData(json)));
if (!nextPageToken) break;
currentPage++;
}
return profilesResults;
};
getResults().then((result) => console.dir(result, { depth: null }))
Code explanation
Declare constants from required libraries:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
| Code | Explanation |
|---|---|
SerpApi |
SerpApi Node.js library |
search |
new instance of GoogleSearch class |
API_KEY |
your API key from SerpApi |
Next, we write down what we want to search and the necessary parameters for making a request:
const searchString = "astronomy";
const pagesLimit = Infinity;
let currentPage = 1;
const params = {
engine: "google_scholar_profiles",
mauthors: searchString,
hl: "en",
};
| Code | Explanation |
|---|---|
searchString |
what we want to search |
pagesLimit |
limit of pages for getting info. If you want to limit the number of pages for getting info you need to define the last page number in this |
currentPage |
current page of the search |
engine |
search engine |
mauthors |
search query |
hl |
parameter defines the language to use for the Google search |
Next, we write a callback function in which we describe what data we need from the result of our request:
const getScholarProfilesData = function ({ profiles }) {
return profiles.map((result) => {
const { name, link = "link not available", author_id, thumbnail, affiliations, email = "no email info", cited_by, interests } = result;
return {
name,
link,
author_id,
photo: thumbnail,
affiliations,
email,
cited_by,
interests:
interests?.map((interest) => {
const { title, link = "link not available" } = interest;
return {
title,
link,
};
}) || "no interests",
};
});
};
| Code | Explanation |
|---|---|
profiles |
an array that we destructured from response |
name, link, thumbnail, ..., interests |
data that we destructured from element of profiles array |
link = "link not available" |
we set default value link not available if link is undefined
|
Next, we wrap the search method from the SerpApi library in a promise to further work with the search results:
const getJson = (params) => {
return new Promise((resolve) => {
search.json(params, resolve);
})
}
And finally, we declare and run the function getResult that gets info from all pages between currentPage and pagesLimit and return it:
const getResults = async () => {
const profilesResults = [];
let nextPageToken;
while (true) {
if (currentPage > pagesLimit) break;
const json = await getJson(params);
nextPageToken = json.pagination.next_page_token;
params.after_author = nextPageToken;
profilesResults.push(...(await getScholarProfilesData(json)));
if (!nextPageToken) break;
currentPage++;
}
return profilesResults;
};
getResults().then((result) => console.dir(result, { depth: null }))
| Code | Explanation |
|---|---|
profilesResults.push(...(await getScholarProfilesData(json))) |
in this code, we use spread syntax to split the array from result that was returned from getScholarProfilesData function into elements and add them in the end of profilesResults array |
console.dir(result, { depth: null }) |
console method dir allows you to use an object with necessary parameters to change default output options. Watch Node.js documentation for more info |
Output
[
{
"name":"Gustavo E. Scuseria",
"link":"https://scholar.google.com/citations?hl=en&user=6ZiRSwQAAAAJ",
"photo":"https://scholar.googleusercontent.com/citations?view_op=small_photo&user=6ZiRSwQAAAAJ&citpid=2",
"affiliations":"Welch Professor of Chemistry, Physics & Astronomy, and Materials Science & …",
"email":"Verified email at rice.edu",
"cited_by":295031,
"interests":[
{
"title":"Quantum Chemistry",
"link":"https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:quantum_chemistry"
},
{
"title":"Electronic Structure",
"link":"https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:electronic_structure"
},
{
"title":"Condensed Matter Physics",
"link":"https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:condensed_matter_physics"
},
{
"title":"Materials Science",
"link":"https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:materials_science"
},
{
"title":"Nanotechnology",
"link":"https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:nanotechnology"
}
]
},
...and other results
]
Links
If you want to see some project made with SerpApi, please write me a message.
Add a Feature Request💫 or a Bug🐞





Top comments (0)