
Intro
Currently, we don't have an API that supports extracting data from Google Trends Realtime Search page.
This blog post is to show you way how you can do it yourself with provided DIY solution below while we're working on releasing our proper API.
The solution can be used for personal use as it doesn't include the Legal US Shield that we offer for our paid production and above plans and has its limitations such as the need to bypass blocks, for example, CAPTCHA.
You can check our public roadmap to track the progress for this API:
🗺️ [New API] Google Trends Daily Search Trends
What will be scraped
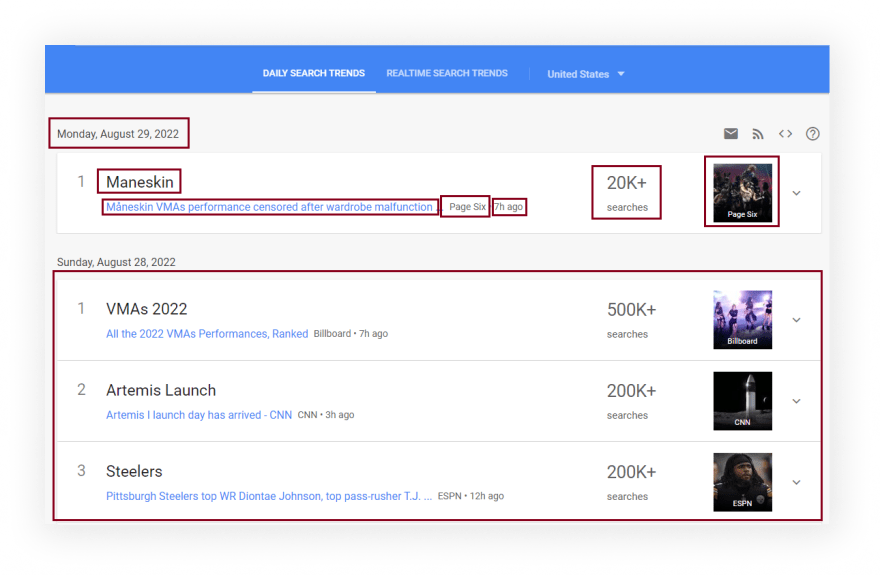
Full code
If you don't need an explanation, have a look at the full code example in the online IDE
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const baseURL = `https://trends.google.com`;
const countryCode = "US";
async function fillTrendsDataFromPage(page) {
while (true) {
const isNextPage = await page.$(".feed-load-more-button");
if (!isNextPage) break;
await page.click(".feed-load-more-button");
await page.waitForTimeout(2000);
}
const dataFromPage = await page.evaluate((baseURL) => {
return Array.from(document.querySelectorAll(".feed-list-wrapper")).map((el) => ({
[el.querySelector(".content-header-title").textContent.trim()]: Array.from(el.querySelectorAll("feed-item")).map((el) => ({
index: el.querySelector(".index")?.textContent.trim(),
title: el.querySelector(".title a")?.textContent.trim(),
titleLink: `${baseURL}${el.querySelector(".title a")?.getAttribute("href")}`,
subtitle: el.querySelector(".summary-text a")?.textContent.trim(),
subtitleLink: el.querySelector(".summary-text a")?.getAttribute("href"),
source: el.querySelector(".source-and-time span:first-child")?.textContent.trim(),
published: el.querySelector(".source-and-time span:last-child")?.textContent.trim(),
searches: el.querySelector(".search-count-title")?.textContent.trim(),
thumbnail: el.getAttribute("image-url"),
})),
}));
}, baseURL);
return dataFromPage;
}
async function getGoogleTrendsDailyResults() {
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
const URL = `${baseURL}/trends/trendingsearches/daily?geo=${countryCode}&hl=en`;
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".feed-item");
const dailyResults = await fillTrendsDataFromPage(page);
await browser.close();
return dailyResults;
}
getGoogleTrendsDailyResults().then((result) => console.dir(result, { depth: null }));
Preparation
First, we need to create a Node.js* project and add npm packages puppeteer, puppeteer-extra and puppeteer-extra-plugin-stealth to control Chromium (or Chrome, or Firefox, but now we work only with Chromium which is used by default) over the DevTools Protocol in headless or non-headless mode.
To do this, in the directory with our project, open the command line and enter npm init -y, and then npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth.
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
📌Note: also, you can use puppeteer without any extensions, but I strongly recommended use it with puppeteer-extra with puppeteer-extra-plugin-stealth to prevent website detection that you are using headless Chromium or that you are using web driver. You can check it on Chrome headless tests website. The screenshot below shows you a difference.

Process
SelectorGadget Chrome extension was used to grab CSS selectors by clicking on the desired element in the browser. If you have any struggles understanding this, we have a dedicated Web Scraping with CSS Selectors blog post at SerpApi.
The Gif below illustrates the approach of selecting different parts of the results.
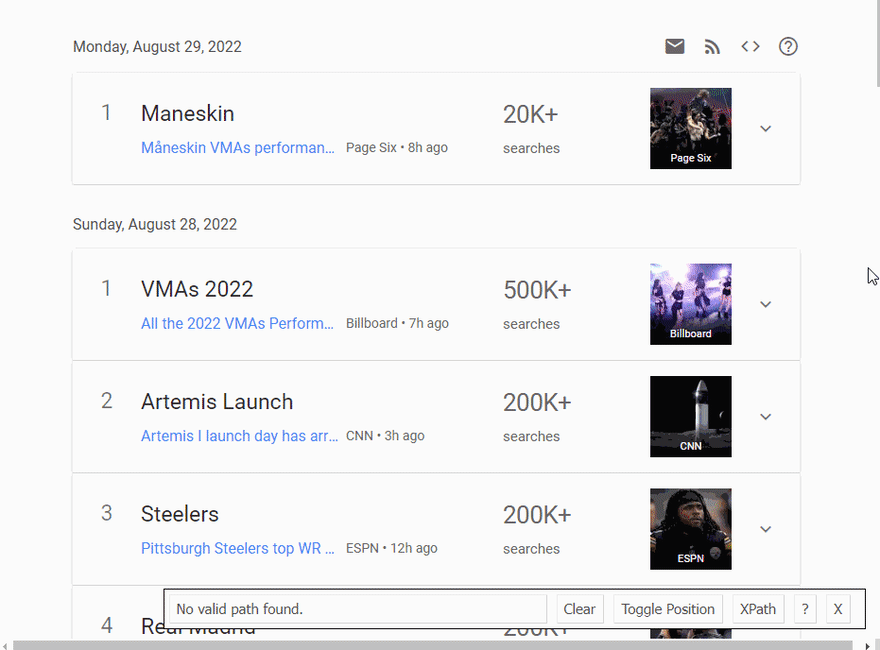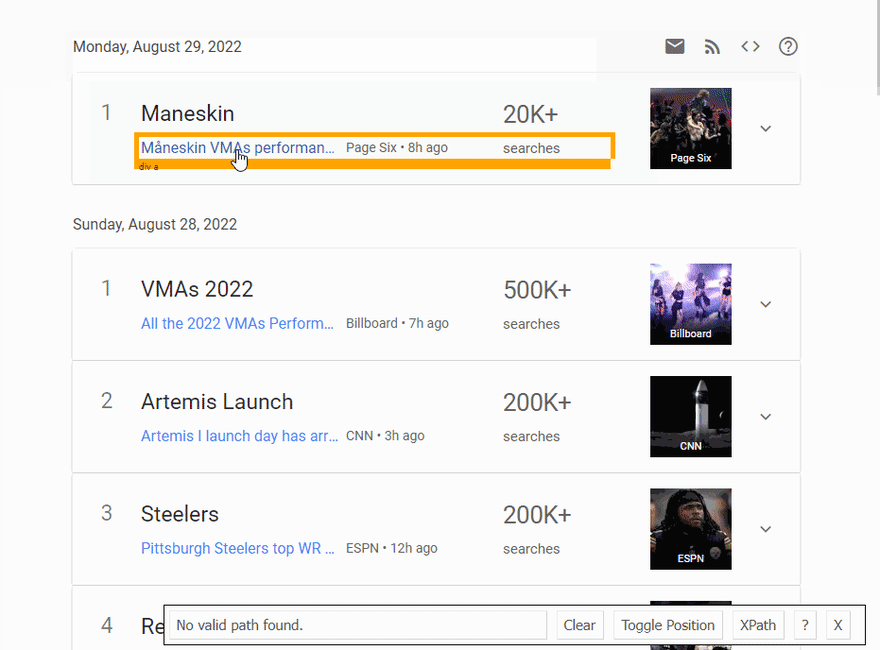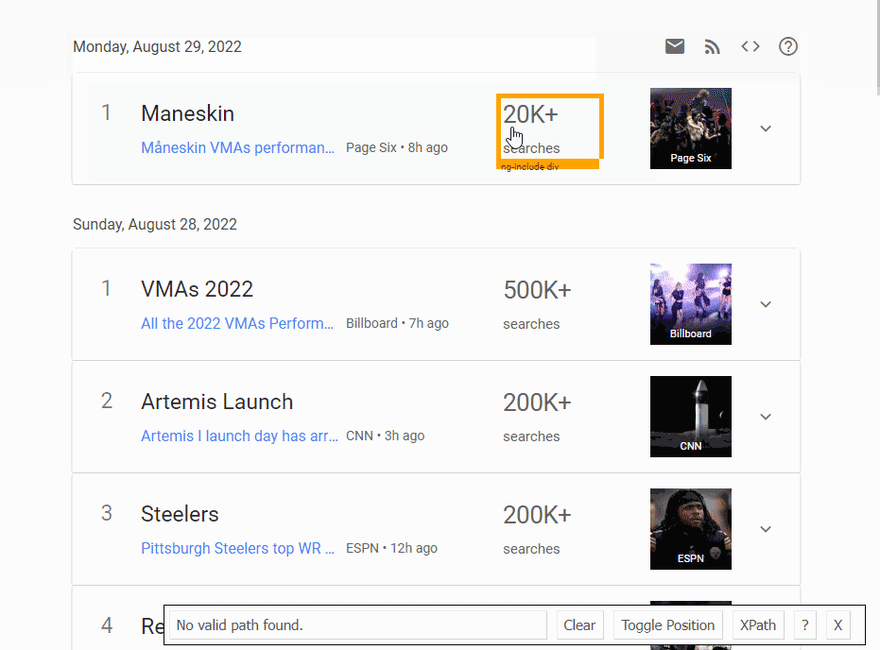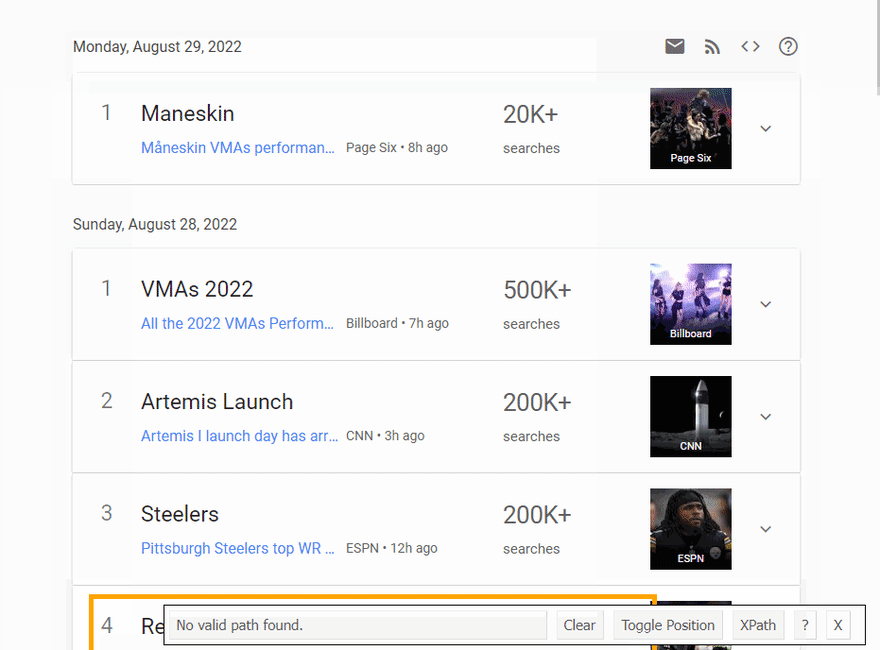
Code explanation
Declare puppeteer to control Chromium browser from puppeteer-extra library and StealthPlugin to prevent website detection that you are using web driver from puppeteer-extra-plugin-stealth library:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
Next, we "say" to puppeteer use StealthPlugin, write Google Trends URL and country code (check the full list of supported Google Trends Locations):
puppeteer.use(StealthPlugin());
const baseURL = `https://trends.google.com`;
const countryCode = "US";
Next, write a function to load all data and get information from the page:
async function fillTrendsDataFromPage() {
...
}
In this function, first, we need to load more data until it is available. To do this we use while loop in which we check if "Load More" button is present on the page (page.$() method), click on this button, wait 2 seconds (using waitForTimeout method) and repeat again until the button is absent from the page:
while (true) {
const isNextPage = await page.$(".feed-load-more-button");
if (!isNextPage) break;
await page.click(".feed-load-more-button");
await page.waitForTimeout(2000);
}
Next, we get information from the page context (using evaluate() method) and save it in the returned array. First, we need to get all the dates available on the page (querySelectorAll() method) and make the new array from got NodeList (Array.from()). This dates will be our results objects keys:
return Array.from(document.querySelectorAll(".feed-list-wrapper")).map((el) => ({
[el.querySelector(".content-header-title").textContent.trim()]:
Next, we assign the trends results value to each date:
Array.from(el.querySelectorAll("feed-item")).map((el) => ({
Next, we assign the necessary data to each object's key. We can do this with textContent and trim() methods, which get the raw text and removes white space from both sides of the string. If we need to get links, we use getAttribute() method to get "href" HTML element attribute:
index: el.querySelector(".index")?.textContent.trim(),
title: el.querySelector(".title a")?.textContent.trim(),
titleLink: `${baseURL}${el.querySelector(".title a")?.getAttribute("href")}`,
subtitle: el.querySelector(".summary-text a")?.textContent.trim(),
subtitleLink: el.querySelector(".summary-text a")?.getAttribute("href"),
source: el.querySelector(".source-and-time span:first-child")?.textContent.trim(),
published: el.querySelector(".source-and-time span:last-child")?.textContent.trim(),
searches: el.querySelector(".search-count-title")?.textContent.trim(),
thumbnail: el.getAttribute("image-url"),
Next, write a function to control the browser, and get information:
async function getGoogleTrendsDailyResults() {
...
}
In this function first we need to define browser using puppeteer.launch({options}) method with current options, such as headless: false and args: ["--no-sandbox", "--disable-setuid-sandbox"].
These options mean that we use headless mode and array with arguments which we use to allow the launch of the browser process in the online IDE. And then we open a new page:
const browser = await puppeteer.launch({
headless: false,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
Next, we define the full request URL, change default (30 sec) time for waiting for selectors to 60000 ms (1 min) for slow internet connection with .setDefaultNavigationTimeout() method, go to URL with .goto() method and use .waitForSelector() method to wait until the selector is load:
const URL = `${baseURL}/trends/trendingsearches/daily?geo=${countryCode}&hl=en`;
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".feed-item");
And finally, we save trends data from the page in the dailyResults constant, close the browser and return the received data:
const dailyResults = await fillTrendsDataFromPage(page);
await browser.close();
return dailyResults;
Now we can launch our parser:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
Output
[
{
"Monday, August 29, 2022":[
{
"index":"1",
"title":"Serena Williams",
"titleLink":"https://trends.google.com/trends/explore?q=Serena+Williams&date=now+7-d&geo=US",
"subtitle":"Thrilled 'to just to live in the moment,' Serena Williams begins US ...",
"subtitleLink":"https://www.espn.com/tennis/story/_/id/34484739/serena-williams-begins-us-open-run-victory-danka-kovinic-arthur-ashe-stadium",
"source":"ESPN",
"published":"3h ago",
"searches":"1M+",
"thumbnail":"https://t3.gstatic.com/images?q=tbn:ANd9GcRv9wWSAE6FrtmwW-UHm4XrHgkSXH7ZUL2Vm1mJkdJNYriJjI10ewtkAf3HNKkoTpq-RFc8uf-1"
},
... and other results
]
},
{
"Sunday, August 28, 2022":[
{
"index":"1",
"title":"Artemis launch",
"titleLink":"https://trends.google.com/trends/explore?q=Artemis+launch&date=now+7-d&geo=US",
"subtitle":"Artemis I launch scrubbed as engine problem defies fast fix",
"subtitleLink":"https://www.washingtonpost.com/technology/2022/08/29/artemis-launch/",
"source":"The Washington Post",
"published":"18h ago",
"searches":"1M+",
"thumbnail":"https://t0.gstatic.com/images?q=tbn:ANd9GcQPD2Dn4-kwn9LYzuMQ2-62vp6vO5XV8oHpedBrlRf6MLfJJ7n1fhW_n6Vfi5Tr1Ogk0jVthKFd"
},
... and other results
]
},
... and other days
]
If you want to see some projects made with SerpApi, please write me a message.
Add a Feature Request💫 or a Bug🐞




Top comments (0)