I started using TF for AWS infrastructure in the summer of 2019, and it was a big deal for me. Going from the AWS console and the AWS CLI to just write code and see those lines reflected in AWS resources felt like magic. To my shock, Terraform is very simple and I got the grasp of the language just by reading documentation. However, there are some things that I would have liked to know back then and cannot go unnoticed when creating a new project with TF. For that reason, in this post, I will try to give you some advice so you can start your projects in Terraform as easy as pie 😎.
First things first: Folder structure.
One of the best things I bought last year was the book Terraform Up & Running, written by Yevgeniy Brikman. In this book, you will get everything you need to implement Terraform on your infrastructure projects at its maximum power. Here is a piece of advice you will encounter in the fourth chapter of the aforementioned book. Terraform will create a state file in every folder you run terraform init, so if you want to differentiate between infrastructure for development and production, you should create a folder for both environments. Also, there is a huge possibility that you will implement some resources that are going to be used across all environments, so a global folder will be nice to have.
Summarizing what I already wrote, a nice folder structure to start in Terraform should look like this:
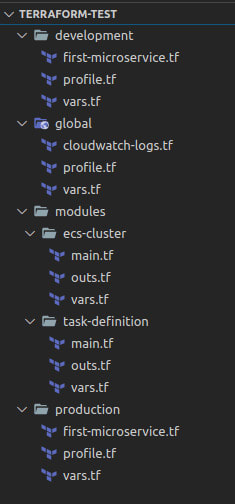
Modules for the win!
Modules are for TF what functions are for regular coding. Without them, you would only repeat yourself ad infinitum. You can get modules from existing Github repositories, like this one to give a static IP to a lambda:
 ainestal
/
terraform-lambda-fixed-ip
ainestal
/
terraform-lambda-fixed-ip
Provide a fixed IP (ElasticIP) to your AWS Lambdas
The idea of the Terraform modules is to provide you with a container for a certain architecture so you only configure what is necessary. In your project file system, there should be a modules folder where you can have all the modules you need for your infrastructure. Then, inside the folder for a specific module, the following files should exist:

The main.tf file contains all the configuration for the resources; the vars.tf file is where the input variables for the module are defined, and the outs.tf file is a collection of parameters returned by the module that you can use on other modules or resources. Like everything on TF, those three files can actually just be one, but the recommendation is to have different files to apply separation of concerns.
Last but not least, to use the modules in your infrastructure, instead of declaring resources you can declare the used module as follows:
module "name-of-module" {
source = "../path/of/module" (can also be a Git repo)
var1 = var.var1
}
Terraform on Teamwork
More often than not, you are going to be pushing your TF code into a repository, where your team will review it. To make the review process easier, aside from tests, but also to verify the changes plan, you think you could use the command terraform plan -out=path/to/output. However, this output will be used by terraform apply and it won't be easy for a human to understand.
If you want to write the terraform plan console output to a file, you should execute something like:
terraform plan -no-color | tee output.txt
The -no-color particle is important because, without it, the command would write a lot of nonsense to the file. This output file will contain your TF plan to be approved before going to a CI/CD process. Speaking of which, here it comes the second advice on the teamwork issue: Centralize the terraform state.
As I previously said, TF creates a state file on every folder you do terraform init to. Let's suppose you use something like Jenkins for the CI/CD process, and you changed the code and did an emergency terraform apply if that code doesn't get into the repository and someone else triggers Jenkins, then your recently deployed infrastructure will be destroyed.
One way to avoid this is by creating a terraform backend. A Backend in TF manages the state and the locks remotely, so you won't have issues with state corruption or unveiling of sensitive data. By default, Terraform offers its own cloud where the state can be stored but on AWS, you can achieve this with an S3 bucket and a dynamo table. Here is a code snippet you can use as a template for an AWS backend:
terraform {
backend "s3" {
profile = "default"
bucket = "test-terraform-state"
key = "global/s3/terraform.tfstate"
region = "us-east-1"
dynamodb_table = "test-terraform-locks"
encrypt = true
}
}
You should have this backend written on every folder you plan to do terraform init in, just like the profile. This way your team will rarely have issues with the terraform state locks.
Import to the rescue
Sometimes, it might happen that you want to implement some resource but you are not sure about its properties, because documentation is not enough, or you are not very clear on what you want; however you know how to set up that exact same resource on the AWS console. It can also happen that you already have some existing resources on the cloud, and you want to start managing them with TF. Here is where terraform import comes to play. This is a very powerful command because you are giving TF permission to manage a resource that might be accidentally deleted or changed later on the road.
To import a resource you can run something like:
terraform import resource_name.resource_tf_name my_test_resource
Where my_test_resource is the actual name of it on the cloud, and the resource_name as well as the resource_tf_name is how you map it on the Terraform code, like this:
resource "resource_name" "resource_tf_name" {
}
Before importing, you need to let terraform know that there will be an incoming resource. Therefore, you should map that resource in the code (empty, this is important), and later on terraform plan you can accommodate its properties so that there are no changes in it. According to the Terraform documentation, in the future, it will import the resource configuration so this will be no longer necessary.
If you want Terraform to stop managing this resource, you can always use the terraform state rm 'resource_name.resource_tf_name' command. 😉
Divide resources and conquer
Last but not least, this advice has more to do with code organization rather than functioning. With modules, there are several ways to organize your code in terraform, and you can choose the most convenient one given your project characteristics. As far as I can see, there are two main ways.
Organize by resource type: useful when the number of resources is not that big, and the resources don't depend on other resources explicitly, i.e.: a group of resources for an ECS cluster.
Organize by resource group: useful when there are a lot of resources and the resources depend on each other, i.e.: a group of resources for lambdas.
Those would be all the insights I would have like to know when I was just starting projects with Terraform. TF is a wonderful tool, and it's even better when used correctly. I hope you can use everything I said in your favor.
Happy terraforming! 😄
Cheers 😎 🍺





Top comments (1)
You can also use show, which gives you HCL of the current state: