How do we ensure security after we have deployed our application? This question comes up in many customer engagements. How do we make something secure and how can we ensure we are compliant? Unfortunately, many of these questions arise after the fact. After the application has been built, or even after it has been deployed, and this is exactly what makes it hard. Our answer to these questions is, you do not. You don’t do this afterwards; you are secure and compliant by default.
Secure and Compliant by default
Nowadays, security is often implemented with a mindset of preventing breach. Make sure your perimeter is safe and prevent bad things from happening. This is often accompanied by a control framework of choice that targets three important areas – Confidentiality, Availability, and Integrity.

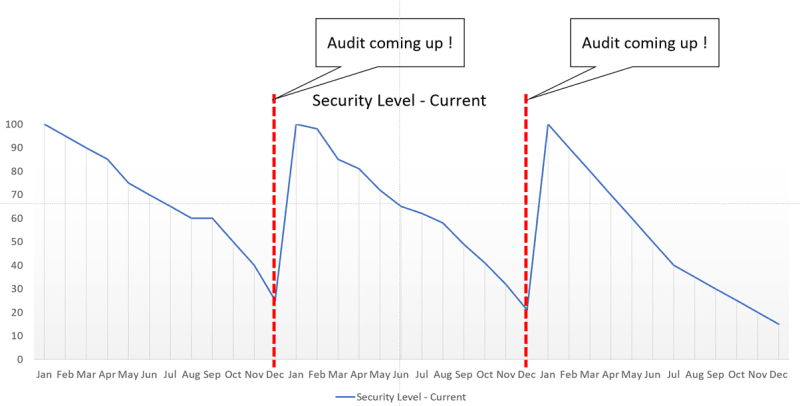
In many cases we receive an Excel list with hundreds of rules we need to implement to make our application “secure”. Following these rules makes us compliant but not necessarily secure, and in practice we can visualize the security score like in the graph below.
In this new world, where cyber threats are the new normal, you and your organization should assume that your software is or will be under attack, and people are going to use your software in ways you cannot anticipate. This is where “Rugged DevOps” or “SecDevOps” comes in. To be “rugged” means that you can deal with this unanticipated use and sudden attacks, that your software and infrastructure is resilient against abuse, that it does not contain vulnerabilities, and that it is secure by design. Furthermore, your software as well your processes should be in such a state that you can deal with frequent changes. After all, it makes all your effort rather useless when your application becomes insecure after five releases because you have no time to maintain the periphery.
And that’s why we should consider security in every phase of our development lifecycle and shift security as far to the left as possible.
Defining a secure and compliant delivery process
With the move to DevOps and Continuous Delivery, where deployments happen multiple times per day, it is even more important to be in control of the process. When the “security department” is outnumbered by the number of product teams and engineers, they have their hands tied. Without automation and the integration of security into the daily work of Engineers (Developers, IT-Operation, Test Engineers, etc.), this department can only do compliance checking. And as Gene Kim mentions in the DevOps Handbook: “Compliance checking is the opposite of security engineering” (source: The DevOps Handbook – Gene Kim – page 313).
In terms of compliance, it all boils down to being able to show that the code that has been produced is traceable (audit trail), reviewed (4-eyes) and that the artifact which has been published to production is unchanged from the code it originated from (integrity). But does all of this make the code secure? Probably it will, but certainly not all aspects are covered.
If we keep in mind that we want to write and deploy secure software, we should enable teams to do just that. We should make sure that code:
- is reviewed
- scanned for known vulnerabilities
- doesn’t expose your passwords or keys
- checked against common errors
- uses approved standard libraries
- and is well tested.
Our process should:
- produce immutable artifacts
- test the application
- monitor for anomalies.
All of this is needed to develop secure and reliable software.
By focusing on security within the development and deployment process, the need for information shifts from the auditor to the teams themselves. To debug a problem in production, sufficient logging is needed. To ensure the same version is deployed to test and production, scripts need to be in place and, in order to get a notification when a problem occurs, sufficient monitoring needs to be implemented. When the need is within the team itself, security and Non Functional Requirements (NFR) become a different priority, and the result is that the teams become compliant automatically. By implementing the security and the necessary countermeasures, the required controls to be compliant will be fulfilled automatically. And the best part? It is verified continuously by an automated pipeline and evidence can be retrieved from the system at any time.
If we shift our focus from building software and making it “secure” to building “secure” software in a “secure” way, we create secure systems. And when we create secure systems, we can test and validate in each step of our process, and they are compliant systems as well. If you are secure, it is most likely that you are compliant as well.
It is vital to enable teams to integrate security into their processes and pipelines. This means at every stage of the so-called Application Lifecycle, which consists of the following phases:

- Requirements: how do you collect requirements? How do you make sure the requirements cover the security requirements and the Non-Functional Requirements (like availability, backups, privacy, etc.)?
- Local Development: what can engineers do within their local environment to develop, build, test, and run more secure code?
- Source Control: once code leaves the local machine and is checked into Source Control, what can we do to make this more secure?
- Build: when building code that comes from a Source Control Repository, what do we need to check and validate, in the code as well as in the produced artifact? Furthermore, what can we do to ensure that the pipeline itself is secure?
- Release: when the artifact is released to a Non-Production Environment, what can we do in terms of security – of the artifact (integrity, are we sure it is the same code as in source control), the pipeline, and the target environment?
- Monitor: what can we do to ensure that the infrastructure and application that has been deployed stay healthy, and how can we detect, respond, and recover from any unforeseen circumstance?
In the rest of this article, we will explore a number of GitHub features that can help us to take some steps into secure software development.
Moving your code to production
When we want to ship a new feature to production using GitHub, we can divide our attention to the following 5 phases:
- coding phase
- storing phase
- build phase
- deploy phase
- release phase
In the following paragraphs we will walk through each of these phases, explaining the various practices you can use, and we will show how GitHub can help you to implement some of these steps.
Coding phase
In the coding phase, code is being developed. In most cases this happens locally on the developer’s machine. This is arguably the most important phase, because this is where security is ultimately put into the code. There are a number of techniques and tools that support the creation of secure code.
Static Code Analysis
Static Code Analysis analyzes the code base without running it. Some tools scan for textual patterns, more advanced tools parse the code and sometimes even build a model to analyze how data flows through your application.
Static Analysis tools then apply rules to detect issues in the code. Static Analysis can detect a multitude of known bad coding practices and often suggests more secure alternatives. Most Static Analysis tools are general purpose, but there’s also a number of security specific analyzers.
In general, when these issues can be detected while the code is being written, the issue can be corrected immediately, and the developer is immediately confronted with an opportunity to learn.
Credential and secret scanning
While locally testing the application, a developer may need to connect to external systems, decrypt data, or store the credentials for its service account. The encryption keys – credentials and API keys – need to be stored securely, but they regularly end up in source or configuration files.
When such files leave the developer’s workstation, they may fall into the hands of others, and they may be able to leverage these credentials to hack into your infrastructure.
To prevent this from happening, a special breed of static analysis tool can analyze your local repository to prevent you from accidentally sharing your secrets to the world.
Curated dependencies
In today’s modern applications we import more code from other developers and organizations than we write ourselves. We rely heavily on artifact repositories such as NPM, NuGet and Ruby Gems. Recent security research has shown that these public repositories offer interesting new ways to trick your teams from running code they didn’t expect to run.
Each time a new dependency is pulled in, it should be vetted to ensure it’s secure and you don’t want your build system to accidentally pull in new, unexpected dependencies.
- 3 ways to mitigate risks by using private package feeds
- 99% of code isn't yours
- Dependency Confusion
Tools like npm audit and snyk will allow you to verify that a dependency has no known security vulnerabilities. Visual Studio has started highlighting problematic packages in recent updates:

GitHub Codespaces
Setting up all these tools can be time-consuming and it’s easy to make mistakes. It also creates a high barrier for people outside of your team to contribute to your projects, whether it is open source or inner source. It is even a high entry barrier for new people joining your team.
Advances in Visual Studio and Visual Studio Code now allow you to build easily extensible standard configurations for your development environments. Visual Studio has basically been broken up into the backend, which manages, analyzes, and compiles your code and the front-end, which handles the user interactions.
GitHub CodeSpaces leverages this technology to run a full IDE from your code repository. Because GitHub CodeSpaces runs on a cloud VM outside your internal environment, it lowers the security risks. Anyone who needs to contribute to the repo is instantly transported into a ready-made environment that has all the aforementioned tools installed and configured to help them make their contribution secure.
Because CodeSpaces runs Visual Studio on a remote container, you can even work from an iPad connected to a much more powerful remote container, only paying for the actual usage while the IDE is open. This even allows a casual contributor to propose changes while helping them do it the right way.
Visual Studio Live Share
With many developers being forced to work remotely, it has become a lot harder to just scoot over to your coder-buddy at the desk next to you to ask for quick feedback, pair or help you debug. Regularly reviewing your code with another person is one of the quickest ways to grow your own understanding and to find potential problems before they are committed to the shared repository.
In the past we often used screen sharing and remote control to collaborate, but using this has its disadvantages. Especially when it comes to security and you give the other person full control over your system by giving them remote control.
Visual Studio Live Share can be compared to Google Docs for your code. It allows you to work in the same local repository with multiple people at the same time, even with multiple cursors simultaneously changing the same code file.
All participants can see the list of detected issues in the code as well as the status of all unit tests, and you can even debug code together. With Live Share you can essentially collaborate and review remotely without having to commit the code and pushing it to a remote repository.
It can even register who collaborated on the code when you decide to commit. By enabling the liveshare.populateGitCoAuthors, the Source Control tab in VS Code will automatically generate the Co-authored-by trailer in the commit message, so hosts can attribute the collaborators they worked with during a pair programming session.
Who you can collaborate with and what they are allowed to do can be managed by GateKeeper.
Storing phase
In the storing phase the engineer pushes code from his local machine to source control. When using GitHub, storing the source code consists of two phases. Committing the code to your local Git repository, and pushing the code to the Git repository that is also used by the rest of the development team.
To ensure a secure process, a number of things can be done.
Required code review
To ensure the 4 (6/8) eyes principle on every code change, generally the first occasion where you can do this is on code push to the Git repository. By defining a simple branching strategy where people create short-lived branches for their code changes and protect the main branch from direct check-ins with a branch policy, you can easily enforce that someone other than the author reviews and approves changes to the code base. With GitHub you can use the settings tab in your repository to set these policies on the branches. You can create different policies and apply them to different branches. To apply the policy to all branches, specify the “Branch name pattern”. Wildcards are allowed, so “*” will apply the policy to all branches.


Validating code phase checks against the code base
Assuming that an engineer ran the checks described in the code phase on his workstation is fine, but it does involve risks. However, to make sure nothing slips through the cracks, you can set up a Continuous Integration (CI) build. Running a CI build after every push to the short-lived branch validates the changes made in the short-lived branch, combined with the code base where other engineers work. This practice gives even more assurance. This build should include (at least) the following code phase checks:
- compiling / syntax checking
- static code analysis
- unit tests
- credential and secret scanning.
When you use GitHub, you can use GitHub Actions to perform the actions. GitHub also includes automated security scanning for credentials on every check-in. When you check in a credential by accident, you will be informed about this by GitHub.

You can create a new action (or workflow) on the “Action” tab. Depending on your repository you can use a default workflow or you can create your own.

The workflow pipeline is created as code and added to your repository. Changing this workflow will result in a code change and thus it will be part of the branch policies on the repository.
Vulnerability and dependency scanning
Scanning your own software is one thing, but in modern software development, over 70% of the software you deliver is not written by your own development team (check out version 9 of our magazine and read “99% of the code isn’t yours). With the rise of Open Source Software and Package Management Tooling, Artifact Repositories and Container Registries, the use of software that was written by others became mainstream.
Conceptually this is perfect. The less you have to do yourself, the better it is. It makes people more productive and in many cases, the people that wrote a specific Open Source Library are more knowledgeable on the subject than you yourself. However, using the software of others, open-source, or purchased from a vendor, is a potentially dangerous practice. The software that you use as part of your own software may contain hazardous vulnerabilities that can be exploited.
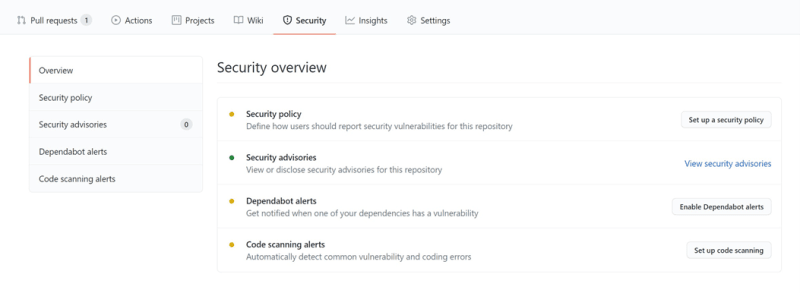
GitHub integrated security scanning for vulnerabilities in their repositories. When they find a vulnerability that is solved in a newer version, they file a Pull Request with the suggested fix. This is done by a tool called Dependabot.
You can enable Dependabot on your GitHub repository using the “Security” tab, click on “Enable Dependabot alerts”, and pick the setting you need.

An alternative for Dependabot is NuKeeper, which provided similar functionality.
To learn more about integrating vulnerability scanning in your pipeline, you can follow the lab “Managing Open-source security and license with WhiteSource” on Azure DevOps Labs.
Credential and secret scanning
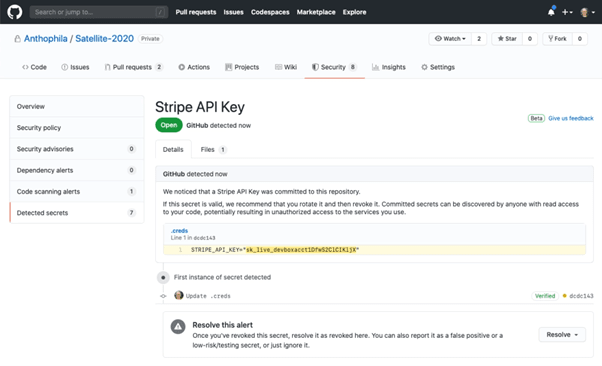
Of course, you are scanning your local repo for accidentally committed credentials, but sometimes your scanning tool will learn new patterns after the fact. GitHub Advanced security now has automated scans to detect leaked credentials on push and will keep monitoring your repository even afterwards.
If you are not scanning, be aware that many threat actors do. They look at a wide range of interesting repositories and offer GitHub-wide search patterns. It may take only five minutes for your shared AWS key to be detected and exploited to deploy miners or ransomware to your cloud environments. When undetected by you, it may cost $60k within a couple of days.
When credentials are detected by GitHub, it will automatically revoke them to prevent others from exploiting the key. GitHub integrates with major cloud providers to provide this service.
Build phase
When code has been created on the local workstation and is stored safely in source control, the delivery process can really start. The software needs to be “packaged.” Compare it with an assembly line where products roll off the belt and are packaged in a big box. This box is signed, sealed, and delivered to the warehouse where it can be picked up for further delivery. In essence, the build pipeline works in the same way.
During the coding and storing phase, we already ran several checks that quickly provided feedback about the quality, security, and stability of the code. In the build phase, we add some more checks and validation and, eventually, package the product:
- build activities from storing phases
- second stage – static code analysis
- vulnerability and dependency scanning
- license scanning
- securely storing the build artifact
- protecting the build history.
Set up a Continuous Integration pipeline on all your branches. When engineers push code to a branch in source control, the validation should start directly. On many occasions, the full build only runs after merging the changes to the main branch.
Securely storing the Build Artifact
One of the main purposes of a build pipeline is to produce:
- an artifact that can eventually be deployed on an environment;
- an artifact that creates an environment;
- a set of scripts that will set the required configuration.
In any case, it is essential that we make sure that the artifact is uniquely identifiable. This allows us to ensure that nobody tampered with an artifact before it landed on production and ensure that the code we produced is actually the code that runs. Storing the artifact that the build pipeline produces is, therefore, an essential task in a secure pipeline.
Within your build pipeline, you can produce two types of artifacts:
- packages or containers that will be consumed by other software and will not run by itself;
- software packages or containers that will be consumed by the end-user or run a process.
When we build software packages, like NuGet packages, NPM packages, PowerShell Modules or even containers, we should immediately think of artifact repositories. We publish our packages to a gallery or repository so that others can consume them. We can either make this publicly available (Open Source) or internally available (Inner Source). To be able to store the artifact, the artifact needs to adhere to a number of simple rules. For example, it needs to contain a unique version and a manifest that describes the package. To publish the package, the publisher requires authentication. This combination, versioned package and secure connection will ensure the integrity of the package.
Strangely enough, when we deploy our website or application to our production servers, we treat it differently. We build our software in the pipeline and copy the files to production. Sometimes we store an artifact on a network share or disk before we release it. But storing it on a disk can allow others to modify the package. Also, our versioning is not always straightforward when it comes to our own files.
To ensure the integrity of our software, the build pipeline and storage location of the artifacts need to be secure as well. When using GitHub, you can upload the build artifacts on the server. There is no way somebody can modify the package on the server. By securing the pipeline and versioning the packages, you drastically reduce the risks of insecure software. In addition, uploading the artifacts GitHub also allows you to use GitHub Package Repository to store your inner source packages. You can even use the building GitHub Container Registry to store your Docker images directly from your workflow.
Deploy phase
The deployment phase is the phase where all the activities of previous phases come together. Code that has been checked by one or multiple teams has been transformed into packages or deployable artifacts. During the deploy phase, the release pipeline is the mechanism that is used to move things from a protected, private environment to a location where others can start using it.
Typically, a release pipeline is built up as follows:
- gather artifacts from one or more sources
- deploy infrastructure
- configure infrastructure
- validate infrastructure
- deploy application
- configure application
- validate application
When we look at the activities mentioned above, there are a number of things we need to ensure when we talk about a secure pipeline.
Run dynamic security tests on infrastructure
Dynamic Application Security Testing (DAST) is a process of testing an application or software product in an operating state. This kind of testing is helpful for industry-standard compliance and general security protections for evolving projects. Good examples are scans for SQL injections, cross-site scripting etc. When an application is deployed multiple times a day, it is necessary to perform the security checks every time instead of checking it once (like in the old days). By using Automated Dynamics Security Testing tools, you can automate these attacks.
A great tool to run Dynamic Security Tests is OWASP ZAP. Find the OWASP ZAP task in either the GitHub or Azure DevOps marketplace.
GitHub allows you to easily enable scanning on common vulnerabilities and coding errors. By using the security tab you can create this workflow, which will run on every branch you create. CodeQL is a semantic code analysis tool, and it allows you to query your code to find vulnerabilities.

Run tests that require a deployed application
Although the software has been tested in the build phase, preferably by running unit tests, you also need to run tests that require a deployed application, i.e.. integration tests or end-to-end tests. GitHub offers GitHub action to integrate your own test runners and allows you to run this as part of the deployment process
Monitor key metrics after deployment
When you have deployed your application, how do you ensure it is running correctly? Of course you need to check some fundamentals by running a smoke test, by checking whether the application responds. But it is also wise to start gathering metrics about the baselines of your application. What is the response time, what is the CPU load? When you know these baselines, you can check these metrics after a new deployment and validate whether they are still the same or at least did not deteriorate.
Set up secure endpoints to the target environment
Of course you need to check your own software for all kinds of security issues. But the pipeline itself and the connection to the target environment also needs to be secure. When you deploy a new version of an application, you probably need some sort of configuration in the application itself. You may also need some secrets like passwords or access tokens to deploy the application. Within Azure DevOps you can use Service Connections to create a secure endpoint. In GitHub you can store the publishing credentials in a GitHub Secret. This way you ensure that the pipeline is the only way to deploy an application. This simply uses a key-value pair where you can use the name of the secret in the action workflow as an environment variable.
Release phase
In contrast to what many people and companies think, the release phase is not the same as the deploy phase. On many occasions, it is still the case that deployment is equal to releasing but by having this dependency, there is also an implicit security risk. When releasing is like deployment, this means that the moment you deploy the software, it becomes available to your end-users. Because you probably need to check a few things before allowing customers to start using the software, the only way to do this is to plan for downtime. A service window is usually the way to do this.
But restricting the release/deployment times to a strict release window also limits the possibility of delivering new features, or worse, security patches. We all know that waiting for an appropriate time to roll out a security fix may imply a much more significant risk.
Building your software and pipelines in such a way to allow the software to be released, without impacting the target environment, is not only the way forward for businesses to deliver new features quickly to their customers, but it dramatically reduces security risks because patching them is a matter of starting a new deployment. When you use feature toggles in your code, these can help in facilitating this. Feature toggles allow you to disable or enable functionality. If the toggle is “on”, users are allowed to use the new functionality. If the toggle is “off”, the functionality cannot be used. Feature toggles allow you to change the behavior of the application without changing the code.
Conclusion
When you develop an application you should do this securely by default. There are a lot of tools that can ease the life of developers and increase security. Just implementing the tools is not enough, you also need to understand why these tools are needed and support them.
GitHub supports a lot of security features out of the box. You need to secure the infrastructure, your software, but also your delivery pipeline. Focus on shifting the security left in your process.
Authors René van Osnabrugge, Michiel van Oudheusden, Jesse Houwing and Arjan van Bekkum.
This article was originally published as part of Xpirit magazine #12.
Get your copy today!
Together we build an Engineering Culture - the title of the latest issue of our XPRT Magazine!
With special thanks to @mickey_gousset who personally reviewed all of the 16 articles. Thank you!
Download the magazine here: https://t.co/HkgsiS6xW0#engineeringculture pic.twitter.com/2cCDaV5kaT
— Xpirit (@Xpiritbv) March 15, 2022





Top comments (0)