
Intro
I'm a fan of Mathematics story telling, and a fidel follower of Numberphile.
Recently Youtube recommended me the following appealing content :
I was discovering the Collatz conjecture, and that was already fascinating me.
The following things kept my attention :
- The structure looks like a graph where each node is a number
LINKED_TO(or not) to an another one - If we stay on positive numbers, they all are connected to a same tree... linked to the number one (that's the essence of the Collatz conjecture)
- If we play with negative number, islands of communities should appear
Immediately, questions came to me :
- What does the graph look like ?
- How big are the islands ?
- How could I interact with the graph ?
These are the questions I'll cover shortly in this post.
The underlying universe
The most exciting thing is that this time, the social data is generated from maths, juste the following simple rule does the whole thing :

Then comes the following Unsolved problem in mathematics:
"Does the Collatz sequence eventually reach 1 for all positive integer initial values?"
This simple formula is embedding a whole universe.
Generate the Universe
To generate the data for the universe, I created a quick program that creates two kind of files :
- graphml file so the graph can be imported by drawing/analysis tools like yEd or Gephi
-
NODES.csvwhich contains all the nodes of the graph, andRELATIONS.csvthat contain all relations between nodes

The program takes two arguments : the lower (-l) and upper (-u) bounds of the seeds. Then, for each seed, compute nodes and relationships around them.
Load the graph
If it's a graph, why not playing with it through Neo4J, the graph database ?
Therefore, simply :
// Load nodes
LOAD CSV WITH HEADERS FROM 'file:///NODES.csv'
AS line
CREATE (:Number {
id: line.id
});
MATCH (n:Number)
RETURN n;
// Add unicity constraint, index nodes
CREATE CONSTRAINT uniqueNumber IF NOT EXISTS
ON (n:Number)
ASSERT n.id IS UNIQUE;
// Link nodes with edges
// Increment weight between node each time
// they get a new connection
LOAD CSV WITH HEADERS FROM "file:///RELATIONS.csv" AS row
MATCH (i:Number), (j:Number)
WHERE
i.id = row.source AND
j.id = row.target
MERGE (i)-[r:LINKED_TO]->(j)
ON CREATE SET r.weight = 1
ON MATCH SET r.weight = r.weight + 1
RETURN r;
The data is in.
Notice that the more nodes are connected, the heavier is the link between them, thanks to the weight attribute of the LINKED_TO relation.
We can play with it, first, check is we visually retrieve the infinite loop around 4, 2 and 1 nodes:

Also, let's take a look at the whole picture while loading the graphml in yEd :

The two tools provide different perspectives. The second one puts in evidence the presence of islands (or cities with roads), not connected to others.
The first one makes it easier to make more analytics queries to explore this universe, thanks to the dedicated GraphDataScience library :

Detect subgraphs (aka. islands or communities)
CALL gds.graph.create(
'Collatz',
'Number',
'LINKED_TO',
{
relationshipProperties: 'weight'
}
);
// Count subgraphs
CALL gds.wcc.stats('Collatz')
YIELD componentCount;
// Tag components
CALL gds.wcc.mutate('Collatz',
{ mutateProperty: 'componentId' })
YIELD nodePropertiesWritten, componentCount;
// Put compoentId on each node to flag them
// as part of the same component
CALL gds.wcc.write('Collatz',
{ writeProperty: 'componentId' })
YIELD nodePropertiesWritten, componentCount;
Then each node has a new property called componentId that tells to which subraph each node belongs to.
How are positive nodes organized ?
// Different componentId from positive nodes
MATCH (n:Number)
where toInteger(n.id) >= 0
RETURN DISTINCT n.componentId, count(*);
Will return :
n.componentId count(*)
2 2228
Well, all positive numbers are part of a same huge subgraph.
What about negative integers ?
MATCH (n:Number)
where toInteger(n.id) < 0
RETURN DISTINCT n.componentId, count(*);
will return
n.componentId count(*)
0 702
7 677
32 783
This time there are many subgraphs, the one we were previously seing as islands.
Local clustering coefficient
The Local Clustering Coefficient algorithm computes the local clustering coefficient for each node in the graph. The local clustering coefficient Cn of a node n describes the likelihood that the neighbours of n are also connected.
CALL gds.graph.create(
'ClusterCoeff',
'Number',
{
LINKED_TO: {
orientation: 'UNDIRECTED'
}
}
);
CALL gds.localClusteringCoefficient.write('ClusterCoeff', {
writeProperty: 'localClusteringCoefficient'
})
YIELD averageClusteringCoefficient, nodeCount;
PageRank
The PageRank algorithm measures the importance of each node within the graph, based on the number incoming relationships and the importance of the corresponding source nodes.
CALL gds.graph.create(
'pageRank',
'Number',
'LINKED_TO',
{
relationshipProperties: 'weight'
}
);
CALL gds.pageRank.write('pageRank', {
maxIterations: 20,
dampingFactor: 0.85,
writeProperty: 'pagerank'
})
YIELD nodePropertiesWritten, ranIterations;
What are the most important nodes of the structure ?
MATCH (n:Number)
RETURN n.id, n.pagerank
order by n.pagerank desc
limit 20;
We get the following result, not surprised to see 4 almost at the top, also -14 is quite interesting:
n.id n.pagerank
"-2" 9.92905827432867
"4" 9.319116539911938
"-14" 8.316335296925851
"-1" 8.13621301949055
"-20" 7.764817040114742
"2" 7.629390404561685
"-7" 6.922374589590439
"-10" 6.4826537196143805
"40" 6.373381127872719
"1" 6.22800676749003
Also, check that -14 is part of a cycle :

Get the top 20 heavily linked nodes
MATCH (i:Number)-[r:LINKED_TO]->(j:Number)
RETURN r.weight,i,j
order by r.weight desc limit 20;

Degree Centrality : find "bifurcations"
The Degree Centrality algorithm
can be used to find popular nodes within a graph. Degree centrality measures the number of incoming or outgoing (or both) relationships from a node, depending on the orientation of a relationship projection.
CALL gds.graph.create(
'CollatzDegree',
'Number',
{
LINKED_TO: {
orientation: 'REVERSE',
properties: ['weight']
}
}
);
CALL gds.degree.write('CollatzDegree',
{ writeProperty: 'degree' })
YIELD centralityDistribution,
nodePropertiesWritten
RETURN centralityDistribution.min AS minimumScore,
centralityDistribution.mean AS meanScore,
nodePropertiesWritten;
Finally, the biggest bifurcations
MATCH (n:Number)
RETURN n.id, n.degree
order by n.degree desc limit 10;
2 is the maximum incoming amount of edges to
any node (and 4 is one of them) :
n.id n.degree
"16" 2.0
"-26" 2.0
"-8" 2.0
...
"4" 2.0
Or this way if you rather drill down afterwards :
MATCH (n:Number)
where n.degree > 1
RETURN n;
Size of the biggest island (component)
Get components, elect a number of the island then get its size :
MATCH (n:Number)
RETURN n.componentId, min(toInteger(n.id)),
count(*) as component_size
order by component_size desc;
Gives back :
n.componentId min(toInteger(n.id)) component_size
2 1 2228
32 -132860 783
0 -113240 702
7 -45200 677
Notice that the "positive" island is by far the biggest one,... at least for this dataset.
Explore loops
Finally, one of the funniest thing in the Collatz dataset : the cycles, ... or loops.
When you manually compute them on a paperboard, this is a really cool experience !
But how to discover them on such a huge dataset ?
Let's find out :
MATCH
(m1:Number)-[:LINKED_TO]->(m2:Number),
cyclePath=shortestPath((m2)-[:LINKED_TO*]->(m1))
WITH
m1, nodes(cyclePath) as cycle
WHERE id(m1) = apoc.coll.max([node in cycle | id(node)])
RETURN m1, cycle;
And we discover the cycles :
- the well known
1->4->2->1 - the funny two state one
(-2)->(-1)->(-2) - but also a much bigger (and unexpected) cycle that "contains" the seed
-17:

Going futrther : what's next ?
Keep pushing boundaries of seeds and :
- Generate really huge datasets and upgrade the Generator accordingly (better algorithm, better types or datastructures)
- Tune Neo4J instance to support huge datasets
- Look for more porwerful workstations to run analysis on them
- Discover if the number of islands is stable or if we discover new ones : are they bigger or smaller ?
- Discover if there are even bigger cycles on negative numbers
- Make digital art on top of these datasets
Other algorithms to play with
Resources
Generator repo (with ready to use samples), feel free to report ideas or feature requests, or even better pull requests :
❔About
This repo has been created to generate ready to use data files around the Collatz Conjecture. As I wanted to learn more about these patterns, I needed to generate some custom files.
Finally I quickly developed a first draft, a generator that makes the job at least for my first experimentations.
👉Usage
To play with these files, you have two options :
- use ready to use samples
- generate your owns
📂Ready to use samples
Ready to use samples are stored in samples directory. The directorories are organized
as follow : ${lower-bound}_${upper_bound}.
So, the -1000_1000 directory contains sample where seeds are between -1000 and 1000.
🚀Generate your own samples
The code is organized as a JBang script, so all you have to do to install :
💣Install JBang
Linux :
sdk install jbang
choco install jbang
Windows :
choco install jbang
🕹️Generate your own samples
Shortest way to…
- Collatz Conjecture on NumberPhile
- Dedicated Coding Train episode
- Graph Data Science Library
- Extend Collatz Conjecture to fractal approach with complex numbers
Feedbacks




Top comments (14)
Gephi render :

Gephi render:

Gephi render :
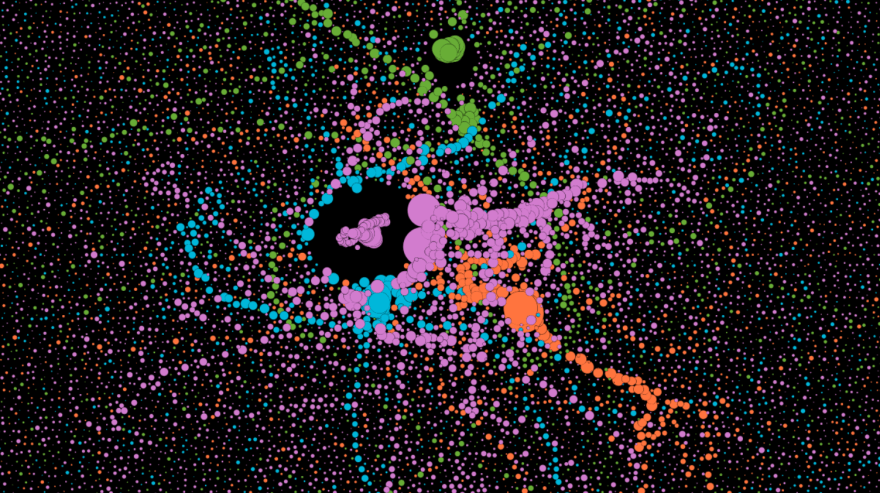
Gephi render :
