
Welcome back to this third part of our four-part series on metaprogramming in Elixir.
Previously, we established the underlying behavior of macros.
Now we will dive into the various applications of macros in Elixir using open-source Elixir libraries.
Let's go!
Using Macro Wrappers to Extend Elixir Module Behavior
Macros can extend module behavior by adding new functions through wrappers that behave similarly to inheritance in object-oriented programming (OOP).
To extend a module, we use use — this is syntactic sugar that performs the following for us:
defmodule Foo do
defmacro __using__(opts) do
quote do
# Extend another module’s behavior here
end
end
end
defmodule Bar do
use Foo
# equivalent to calling these two expressions
# require Foo
# Foo.__using__([])
end
The __using__ callback macro extends the behavior of Bar. It is injected into the callsite and expanded.
We will be using the following terminology:
-
Wrapper — a module that extends other modules like
Foo. -
Inheritor — a module that
uses wrappers likeBar, inheriting behavior.
Let’s design a wrapper.
Say we are building a website that relies on several APIs to work. Assuming we use an HTTP client like
HTTPoison and each API request has common configurations like
request/response data type, we can handle the API requests in three ways:
- Set up each API request separately.
- Compose API requests by chaining functions that configure each request.
- Build a wrapper that automatically configures each API request per request.
While each of these approaches has its merits, we will focus on the last approach.
HTTPoison offers a wrapper for building basic API wrappers through
HTTPoison.Base. It handles aspects of an API request like setting up the endpoint and parsing the request/response body.
We will build another wrapper on top of this that will enable inheritors to achieve our business requirements:
- Parse all request/response bodies to/from JSON.
- Generate an API URL, given a base URL and an endpoint for the base URL.
- Configure the request headers to accept JSON and set the content type to JSON.
- Parse and handle response bodies.
The wrapper should produce inheritors like:
defmodule DogWrapper do
use BaseWrapper, base_url: “https://api.dogs.com”
def upload(name, breed) do
case post?(“upload”, %{“name” => name, “breed” => breed}) do
{:ok, response} -> {:ok, response[“link”]}
{:error, error} -> {:error, error}
end
end
end
defmodule CatWrapper do
use BaseWrapper, base_url: “https://api.cats.com”
def upload(name, breed, talkative) do
case post?(“upload”, %{“name” => name, “breed” => breed, “talkative” => talkative}) do
{:ok, response} -> {:ok, response[“url”]}
{:error, error} -> {:error, error}
end
end
end
defmodule AnimalLovers do
def upload(:dog, name, breed) do
case DogWrapper.upload(name, breed) do
{:ok, link} -> redirect(link)
{:error, error} -> redirect_error(error)
end
end
def upload(:cat, name, breed, talkative) do
case CatWrapper.upload(name, breed, talkative) do
{:ok, link} -> redirect(link)
{:error, error} -> redirect_error(error)
end
end
end
The inheritors do not contain any cumbersome API request logic. Instead, they focus on extracting data from the responses and executing the business logic.
Additionally, the wrapper integrates a base URL into the API requests, so inheritors provide only the endpoint.
Now we know what we want to accomplish, let’s build the wrapper.
First, we define our wrapper, calling it BaseWrapper. This module will define the __using__ callback.
opts is a keyword list that will hold the base_url of the inheritor, and it is bound to the quote.
location option for quote ensures that any errors will directly point to the line in the BaseWrapper.
Any behavior defined in quote will be injected into the inheritor.
defmodule BaseWrapper do
defmacro __using__(opts) do
quote location: :keep, bind_quoted: [opts: opts] do
# behavior goes here
end
end
end
Then, we extend our inheritor to use the basic behavior from HTTPoison.Base.
# quote
use HTTPoison.Base
Now, we want to retrieve the base URL from opts. We do not need to unquote opts as it was bound.
# quote
base_url = Keyword.get(opts, :base_url)
With that, we can begin configuring our wrapper using HTTPoison.Base.
HTTPoison.Base defines several callbacks used to process requests and responses.
We will override these callbacks to implement the behavior we want.
# quote
# Modify request headers to include necessary information about the API
def process_request_headers(headers) do
h = [
{“Accept”, “application/json”},
{“Content-Type”, “application/json”}
]
headers ++ h
end
# Generate the URL for the endpoint using a base URL received from the inheritor
def process_url(endpoint), do: URI.merge(URI.parse(unquote(base_url)), endpoint) |> to_string()
# Automatically encode request body to JSON
def process_request_body(body), do: Jason.encode!(body)
# Automatically decode request body from JSON
def process_response_body(body), do: Jason.decode!(body)
Finally, we want to parse responses from POST requests based on the HTTP status code of the response.
# quote
def post?(endpoint, body) do
# post is available as we have used HTTPoison.Base which will perform the necessary imports for us
# post receives only the endpoint of the request as process_url prepends the base URL already
response = post(endpoint, body)
# We defer the parsing of the response to a function within the BaseWrapper module.
# Reasons for doing so will be discussed later
BaseWrapper.parse_post(response)
end
# BaseWrapper
def parse_post({:ok, %HTTPoison.Response{status_code: code, body: body}})
when code in 200..299 do
{:ok, body}
end
def parse_post({:ok, %HTTPoison.Response{body: body}}) do
IO.inspect(body)
error = body |> Map.get(“error”, body |> Map.get(“errors”, “”))
{:error, error}
end
def parse_post({:error, %HTTPoison.Error{reason: reason}}) do
IO.inspect(“reason #{reason}”)
{:error, reason}
end
Putting all this together, we have a module that looks like this:
defmodule BaseWrapper do
defmacro __using__(opts) do
quote location: :keep, bind_quoted: [opts: opts] do
use HTTPoison.Base
base_url = Keyword.get(opts, :base_url)
def process_request_headers(headers) do
h = [
{“Accept”, “application/json”},
{“Content-Type”, “application/json”}
]
headers ++ h
end
def process_url(endpoint), do: URI.merge(URI.parse(unquote(base_url)), endpoint) |> to_string()
def process_request_body(body), do: Jason.encode!(body)
def process_response_body(body), do: Jason.decode!(body)
# Function injected at compile-time to parse and act on responses accordingly
def post?(url, body) do
response = post(url, body)
BaseWrapper.parse_post(response)
end
end
end
def parse_post({:ok, %HTTPoison.Response{status_code: code, body: body}})
when code in 200..299 do
{:ok, body}
end
def parse_post({:ok, %HTTPoison.Response{body: body}}) do
IO.inspect(body)
error = body |> Map.get(“error”, body |> Map.get(“errors”, “”))
{:error, error}
end
def parse_post({:error, %HTTPoison.Error{reason: reason}}) do
IO.inspect(“reason #{reason}”)
{:error, reason}
end
end
We've used macro wrappers to extend module behavior. Now, let's focus our attention on performing batch imports using wrappers.
Batch Imports with Macro Wrappers
We can use wrappers to perform batch imports in inheritors.
We can define a group of imports/aliases/requires that will be available during compile-time without performing the imports manually in the inheritor.
This is useful when several inheritors require the same set of imports and is best illustrated in Hound — a browser automation testing library:
# lib/hound/helpers.ex
defmacro __using__([]) do
quote do
import Hound
import Hound.Helpers.Cookie
import Hound.Helpers.Dialog
import Hound.Helpers.Element
import Hound.Helpers.Navigation
import Hound.Helpers.Orientation
import Hound.Helpers.Page
import Hound.Helpers.Screenshot
import Hound.Helpers.SavePage
import Hound.Helpers.ScriptExecution
import Hound.Helpers.Session
import Hound.Helpers.Window
import Hound.Helpers.Log
import Hound.Helpers.Mouse
import Hound.Matchers
import unquote(__MODULE__)
end
end
Hound overrides __using__ to import a host of helper modules available to the inheritor.
The inheritors are always going to be test suites written by other developers. It is convenient and easy to maintain imports through use Hound.Helpers.
Next up, wrappers can also override and dynamically generate functions. Let's see how that works.
Macro Wrappers Define Functions to Override
Like a child class overrides a method in its parent class in OOP, wrappers can define some base behavior for functions and allow inheritors to override this behavior.
This is achieved using defoverridable.
Phoenix uses this to great effect by allowing inheritors of Phoenix.Controller.Pipeline to override functions like init and call to include context-specific behavior.
However, if a custom behavior isn't necessary — i.e. the function is not overwritten — the base behavior will be used instead:
# lib/phoenix/controller/pipeline.ex
defmacro __using__(opts) do
quote bind_quoted: [opts: opts] do
# ...
@doc false
def init(opts), do: opts
@doc false
def call(conn, action) when is_atom(action) do
conn
|> merge_private(
phoenix_controller: __MODULE__,
phoenix_action: action
)
|> phoenix_controller_pipeline(action)
end
@doc false
def action(%Plug.Conn{private: %{phoenix_action: action}} = conn, _options) do
apply(__MODULE__, action, [conn, conn.params])
end
defoverridable init: 1, call: 2, action: 2
end
end
Macro Wrappers Dynamically Generate Functions
You can also use unquote fragments to dynamically define an arbitrary number of functions. These functions are injected into a module during compile-time. This is especially useful when working with dynamic data or data that comes from an API.
This article will focus on the former, as Metaprogramming Elixir includes a wonderful example of dynamically defining functions for API responses under the code/hub/.
Let's say we are building a script that reads a list of groceries and generates functions for each category. These functions will operate on each unique category and the items within it.
For simplicity, each function will be the category's name and print the contents of the category.
The grocery list will use the following format — <category>:<comma separated list>:
// groceries.txt
dinner:carrots,potatoes,curry,chicken cubes
supplies:paper,pencils
school:folder,binder
We can read this file in an Elixir script:
# groceries.exs
defmodule Groceries do
@filename "groceries.txt"
for line <- File.stream!(Path.join([__DIR__, @filename]), [], :line) do
# line represents each line of the groceries list
end
end
We've extracted the lines of groceries, now we can parse each line:
# for
[category, rest] = line |> String.split(":") |> Enum.map(&String.trim(&1))
groceries = rest |> String.split(",") |> Enum.map(&String.trim(&1))
Then we can define our dynamic functions.
We use unquote as an argument for def. def is also a macro, so expands the unquote along with anything in its body during compilation. This is known as an unquote fragment.
# for
def unquote(String.to_atom(category))() do
readable_list = Enum.join(unquote(groceries), " and ")
IO.puts("Groceries in #{unquote(category)} include #{readable_list}")
end
Putting it all together, we get the following script:
# groceries.exs
defmodule Groceries do
@filename "groceries.txt"
for line <- File.stream!(Path.join([__DIR__, @filename]), [], :line) do
[category, rest] = line |> String.split(":") |> Enum.map(&String.trim(&1))
groceries = rest |> String.split(",") |> Enum.map(&String.trim(&1))
def unquote(String.to_atom(category))() do
readable_list = Enum.join(unquote(groceries), " and ")
IO.puts("Groceries in #{unquote(category)} include #{readable_list}")
end
end
end
iex(1)> Groceries.dinner
Groceries in dinner include carrots and potatoes and curry and chicken cubes
:ok
iex(2)> Groceries.school
Groceries in school include folder and binder
:ok
Now let's turn our attention to implementing domain-specific languages (DSLs) using macros.
Implement Domain-Specific Languages using Macros
Domain-Specific Languages (DSLs) are "computer language(s) specialized to a particular application domain."
DSLs can be built and used in Elixir to solve business requirements.
As the official DSL tutorial points out:
You don’t need macros in order to have a DSL: every data structure and every function you define in your module is part of your Domain-specific language.
However, we will cover a simple implementation of a DSL using macros to demonstrate how that would look.
The simplest example of a DSL is from ExUnit, a built-in testing framework (taken from the ExUnit documentation):
defmodule AssertionTest do
use ExUnit.Case, async: true
test "the truth" do
assert true
end
end
test is a macro that registers a new test case.
These test cases are collated using accumulating module attributes. Then, when the test suite executes, all of the declared test cases are executed.
You can find a simplified implementation and explanation of this DSL in the official tutorial.
Absinthe — an implementation of the GraphQL specification — has a DSL for defining schemas.
# lib/absinthe/schema/notation.ex
defmacro object(identifier, attrs, do: block) do
{attrs, block} =
case Keyword.pop(attrs, :meta) do
{nil, attrs} ->
{attrs, block}
{meta, attrs} ->
meta_ast =
quote do
meta unquote(meta)
end
block = [meta_ast, block]
{attrs, block}
end
__CALLER__
|> recordable!(:object, @placement[:object])
|> record!(
Schema.ObjectTypeDefinition,
identifier,
attrs |> Keyword.update(:description, nil, &wrap_in_unquote/1),
block
)
end
object is a macro that generates the GraphQL schema.
We define it as a macro because we're accessing compile-time information through __CALLER__, and we're attempting to work with the module's metadata. Defining it as a macro loads the schemas during compile-time.
Even the routing functions in Phoenix are a DSL.
Alchemist Camp's 'Creating a DSL for our router' video series explains how to implement a routing system similar to Phoenix's.
It's time to move on to Abstract Syntax Trees (ASTs): how they can be traversed and when to use prewalk vs. postwalk macros.
Traversing Abstract Syntax Trees (ASTs)
We introduced ASTs in part one of this series. You can traverse an existing AST to extract information about — or modify — the structure of the AST to:
- Improve performance
- Simplify the AST
- Perform computations based on the structure of the AST
As the modification of ASTs is a niche process and context-dependent, we will focus on how traversal is performed rather than the specific application of traversal.
Going Back to the Roots of ASTs
Before we can understand the traversal of ASTs, we have to get to grips with the core data structure of ASTs.
Source code is parsed into trees — data structures that house hierarchical tree data. They begin with a root node, followed by a set of sub-trees — children nodes.
Each node includes a reference to its children. Each childless node is known as a leaf.
Read more about the tree data structure.
The figure below illustrates the basic anatomy of a tree:
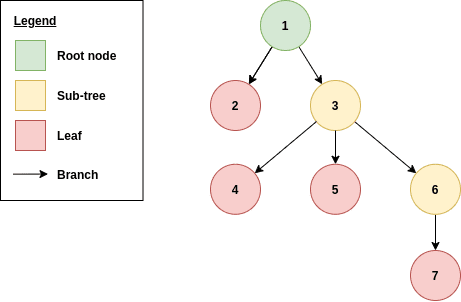
Order of Traversal in ASTs
Now that we know the underlying data structure of an AST, we can tackle the problem of traversing an AST/tree.
Elixir uses depth-first traversal in either pre-order or post-order.
Depth-first traversal follows a node down to its children recursively until reaching a leaf. The sibling of the node is moved to next, and the recursion repeats.

(Source: Wikimedia Commons)
If we use our example, the nodes are visited in the following order: 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7.
Pre-order and post-order traversal refer to how depth-first traversal occurs:
- Pre-order traversal starts from the root node and traverses depth-first through the AST until the right-most leaf is reached.
In our tree, the nodes would be visited in the following order: 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7.
- Post-order traversal starts from the left-most leaf of each sub-tree and traverses in depth-first fashion until we reach the root node.
In our tree, the nodes would be visited in the following order: 2 -> 4 -> 5 -> 7 -> 6 -> 3 -> 1. The traversal happens upwards towards the root node.
Read more about orders of traversal on Geeks for Geeks.
Regardless of the traversal order, the traversal occurs recursively until the "end condition" — i.e., right-most leaf for pre-order and root node for post-order.
In Elixir, functions represent each type of traversal:
-
Macro.prewalk— performs depth-first, pre-order traversal -
Macro.postwalk— performs depth-first, post-order traversal -
Macro.traverse— performs depth-first traversal and both pre and post-order traversal on the AST
By traversing the tree in a given order, we can extract information about the AST and use it to modify the AST.
We define functions that will be executed recursively on every node during traversal. These functions are similar to map.
The input is the currently visited node, while the output is a modified/untouched node.
Prewalk vs. Postwalk Macros
You might ask: "What is the benefit of using pre-order traversal over post-order traversal, and vice versa?"
In most scenarios, there is no difference between the two as both will traverse the AST.
However, you'll have a preference for postwalk or prewalk if the operation is order-sensitive — i.e., if you require the traversal to start at the root node or the left-most leaf first.
This may happen when the operation aims to match the first node (in order) against a given condition and only perform the operation on that node. We would rather have the traversal find the node quickly to operate as soon as possible.
In this case, prewalk is preferred over postwalk if the node appears at the beginning of the AST.
Macro.prewalk(ast, fn
{:match, [], args} -> foo(args)
otherwise -> otherwise
)
Another consideration is unintended infinite recursion. Take this example:
Macro.prewalk({:foo, [], [:bar]}, fn
{:foo, [], _} -> {:foo, [], [{:foo, [], [:bar]}]}
otherwise -> otherwise
end)
In this prewalk, the function matches any node that calls the foo function and replaces it with a recursive call to foo, with foo as the argument.
This will produce an infinite AST that, when converted to Elixir code, will look something like foo(foo(foo(...))).
prewalk is recursively executed on an AST — usually until it reaches the right-most leaf, indicating the AST's end. However, as the AST expands infinitely in the above example, there will never be a right-most leaf, hence infinite recursion.
Using postwalk instead avoids this issue as we simply replace the node once and move on upwards to the root node where the recursion will stop.
Macro.postwalk({:foo, [], [:bar]}, fn
{:foo, [], _} -> {:foo, [], [{:foo, [], [:bar]}]}
otherwise -> otherwise
end)
{:foo, [], [{:foo, [], [:bar]}]}
So, while the choice of prewalk and postwalk might not matter when an operation is not order-sensitive, postwalk is preferred over prewalk to avoid infinite recursion.
traverse combines prewalk and postwalk, performing both together. This is useful when we want to traverse the AST in both orders.
Ecto uses prewalk to count the number of interpolations within a given expression.
In this case, there isn't a specific reason to choose prewalk over postwalk.
# lib/ecto/query/builder.ex
def bump_interpolations(expr, params) do
len = length(params)
Macro.prewalk(expr, fn
# The following expression matches a pinned variable which is what Ecto relies on for
# interpolation
{:^, meta, [counter]} when is_integer(counter) -> {:^, meta, [len + counter]}
other -> other
end)
end
Ecto also uses postwalk to expand dynamic expressions.
# lib/ecto/query/builder/dynamic.ex
defp expand(query, %{fun: fun}, {binding, params, subqueries, count}) do
{dynamic_expr, dynamic_params, dynamic_subqueries} = fun.(query)
Macro.postwalk(dynamic_expr, {binding, params, subqueries, count}, fn
{:^, meta, [ix]}, {binding, params, subqueries, count} ->
case Enum.fetch!(dynamic_params, ix) do
{%Ecto.Query.DynamicExpr{binding: new_binding} = dynamic, _} ->
binding = if length(new_binding) > length(binding), do: new_binding, else: binding
expand(query, dynamic, {binding, params, subqueries, count})
param ->
{{:^, meta, [count]}, {binding, [param | params], subqueries, count + 1}}
end
{:subquery, i}, {binding, params, subqueries, count} ->
subquery = Enum.fetch!(dynamic_subqueries, i)
ix = length(subqueries)
{{:subquery, ix}, {binding, [{:subquery, ix} | params], [subquery | subqueries], count + 1}}
expr, acc ->
{expr, acc}
end)
end
Another way you can change module behavior using macros is through compile-time hooks — let's take a quick look at those.
Compile-time Hooks with Macros
Compile-time hooks allow the compilation behavior of a module to be modified. Callbacks accompany these hooks.
The two notable hooks to discuss are @before_compile and @after_compile. They are useful when we want to perform computation right before — or right after — module compilation.
For now, let's look at a basic set of examples for each hook.
With @before_compile, as the callback (defmacro __before_compile__(env)) is called right before compilation, the callback must be declared in a separate module from where the hook references it.
If the callback is declared in the same module, the macro will not compile in time.
defmodule Foo do
defmacro __before_compile__(env) do
IO.inspect(env)
nil
end
end
defmodule Bar do
@before_compile Foo
end
An exception to this behavior is when Bar is an inheritor of Foo:
defmodule Foo do
defmacro __using__(_) do
quote do
@before_compile unquote(__MODULE__)
end
end
defmacro __before_compile__(env) do
IO.inspect(env)
nil
end
end
defmodule Bar do
use Foo
end
In this example, as @before_compile is injected into Bar, its callback is defined in Foo (a different module). Since use calls require, it ensures that Foo is compiled before Bar. This means Foo.__before_compile__/1 is always available to Bar.
With @after_compile, there isn't a need to declare the callback (defmacro __after_compile__(env, bytecode)) in another module. This is because the module housing the callback is already compiled, so the callback is available.
defmodule Foo do
@after_compile __MODULE__
def __after_compile__(env, _bytecode) do
IO.inspect(env)
nil
end
end
Another hook that is worth mentioning briefly is @on_definition, which invokes its callback whenever a function/macro is defined in the current module.
ExUnit uses @before_compile in a test suite to inject a final function — __ex_unit__ — to execute the test suites after they have been collated.
This function must be injected right before compilation when all the test suites are collated.
You may also wish to store a list of data across macro invocation, such as when ExUnit collates test cases and invokes them all at once.
This can be achieved using module attributes. Let's see that in action.
Module Attributes as Temporary Storage
When we set a module attribute to accumulate, any invocation of the module attribute will add the given value to the list, rather than overriding it:
defmodule Foo do
Module.register_attribute(__MODULE__, :names, accumulate: true)
@names "John"
@names "Peter"
def print, do: IO.inspect(@names)
end
iex(1)> Foo.print
["Peter", "John"]
We may also want to accumulate values through a function call.
This happens when the parent module first compiles, and then a secondary module updates the module attribute via a macro, like so:
defmodule Foo do
defmacro add(name) do
quote do
@names unquote(name)
:ok
end
end
end
defmodule Bar do
require Foo
import Foo
Module.register_attribute(__MODULE__, :names, accumulate: true)
add "john"
add "henry"
IO.inspect(@names) # This prints ["henry", "john"] right after the module is done compiling
end
Foo must compile first. The attribute has to be registered under Bar before it can be used in a given module.
The exception to this rule is use:
defmodule Foo do
defmacro __using__(_) do
quote do
import Foo
Module.register_attribute(__MODULE__, :names, accumulate: true)
end
end
defmacro add(name) do
quote do
@names unquote(name)
:ok
end
end
end
defmodule Bar do
use Foo
add "john"
add "henry"
IO.inspect(@names) # This prints ["henry", "john"] right after the module is done compiling
end
This is how ExUnit accumulates test cases and uses @before_compile to inject a "run all test cases in test suite" function right before compilation, similar to something like this:
defmodule Calculator do
def add(a, b), do: a + b
def subtract(a, b), do: a - b
end
defmodule TestCase do
defmacro __using__(_) do
quote do
import TestCase
Module.register_attribute(__MODULE__, :tests, accumulate: true)
@before_compile unquote(__MODULE__)
end
end
defmacro __before_compile__(_env) do
# Inject a run function into the test case after all tests have been accumulated
quote do
def run do
Enum.each @tests, fn test_name ->
result = apply(__MODULE__, test_name, [])
state = if result, do: "pass", else: "fail"
IO.puts "#{test_name} => #{state}"
end
end
end
end
defmacro test(description, do: body) do
test_name = String.to_atom(description)
quote do
@tests unquote(test_name)
def unquote(test_name)(), do: unquote(body)
end
end
end
defmodule CalculatorTest do
use TestCase
import Calculator
test "add 1, 2 should return 3" do
add(1, 2) == 3
end
test "subtract 5, 2 should not return 4" do
subtract(5, 2) == 4
end
end
CalculatorTest.run
"add 1, 2 should return 3" => pass
"subtract 5, 2 should not return 4" => fail
Finally, we'll touch on deferring computation using macros.
Deferring Computation with Macros
Macros inject behavior into the callsite as-is and can be used to avoid immediate evaluation of an expression.
For instance:
defmodule Foo do
def if?(condition, do: block, else: else_block) do
case condition do
true -> block
false -> else_block
end
end
end
Foo.if? true do
IO.puts("Truth")
else
IO.puts("False")
end
"Truth"
"False"
Here, we tried implementing the new if using a regular function. However, the result is not what we expect — rather than only evaluating and printing "Truth", both "Truth" and "False" are printed.
This is because of the nature of a regular function: each block is evaluated immediately, so the case will not work.
If we use a macro instead, the macro has to be expanded first, generating an AST of the case first and evaluating the case accordingly. During this time, the condition is evaluated, before matching against the case, and, finally, the appropriate block is evaluated.
Note: This example is borrowed from Metaprogramming Elixir.
Macros in Elixir: A Powerful Tool, If Used Wisely
You can apply macros to many scenarios to extend an application's behavior in ways that normal code cannot.
However, macros are a double-edged sword — when misused, they can create confusion and muddy code's readability and semantic meaning.
In the final part of this metaprogramming series, we will delve into the common pitfalls you might encounter when working with macros in Elixir.
Thanks for reading, and see you next time!
P.S. If you'd like to read Elixir Alchemy posts as soon as they get off the press, subscribe to our Elixir Alchemy newsletter and never miss a single post!
Jia Hao Woo is a developer from the little red dot — Singapore! He loves to tinker with various technologies and has been using Elixir and Go for about a year. Follow his programming journey at his blog and on Twitter.





{kind=link}
Top comments (0)