
This is the fourth article of the Inverted index series that I am writing on dev.to. We will be talking about the first component i.e The Dictionary in this article and other component i.e the Posting lists in the coming articles. This post is very closely related to my last article on Introduction to Inverted Index Please do give it a read before reading this one for better understanding.
Please don't assume the dictionary as the python dictionary/HashMap. There is more to it. 😌
Topics to be covered
* Overview and need for Dictionary
* Supported Operations
* Types of Dictionary
* Sort-based Dictionary
* Hash-based Dictionary
* Which one is better?
Overview
Let's recall the simple representation of the Inverted Index that we saw in our last post
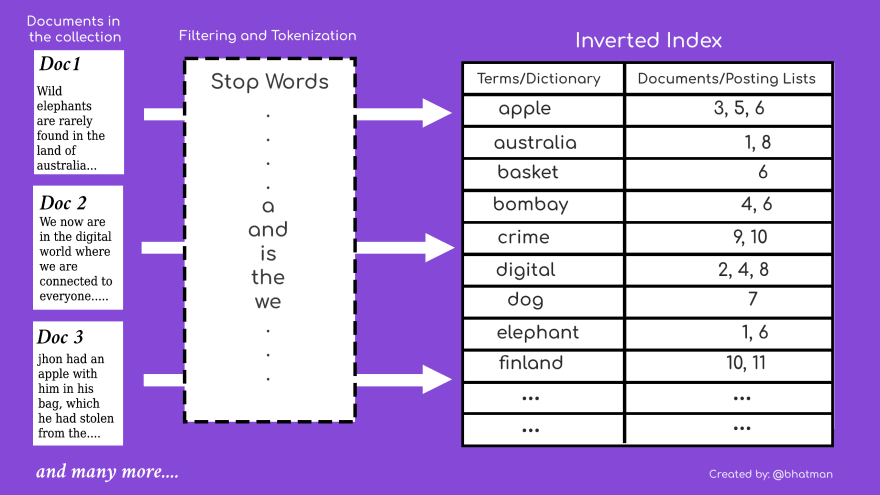
In this article, we are going to focus on the term column in the Inverted Index representation in the above diagram.
Since this term column contains all the words/terms in our collection, we also refer to it as our Inverted index's dictionary.
🙋 But why do I need a dictionary?
The answer is pretty simple as seen in the diagram too, the main purpose of the dictionary terms is to manage a set of terms in a text collection and provide a mapping from the set of index terms to the locations of their posting lists. Posting lists column does not contain the data but the pointer/reference to the actual data store, they are just references to the actual text data available in-memory or over the disk.
Supported Operations by Dictionary 🚀
A "Basic" dictionary implementations in inverted indexes/search engines usually provide the following operations:
- Insert new entry to the dictionary
- Search/Find the key in the dictionary:
- Find a particular key/term and return the posting list entry.
- Find the entries for aa the terms which start with a given prefix.
- Update the dictionary term entries as per the new incoming data. The delete operation can also be part of this since the deletion of old terms is kind of an update for the dictionary based on the new incoming data.
We will understand the Search/Find and insert operation right now in this post.
The problem in our beautiful dictionary? ❓
Let's assume my Dictionary has 10,000,000 terms. And I plan to search for the term "Scranton" in this dictionary. This itself becomes a problem since scanning/grepping through the dictionary will result in the time complexity of O(n). How do we reduce it down? Now take a seat and let me explain it to you with two of the most popular ways to achieve this:

Types to store the Dictionary terms:
- Sort based dictionary
- Search Tree
- Lexicographical order list
- Hash-based dictionary.
Again there are no perfect solutions, you can choose the type based on your requirement. We will have a look at the pros and cons of each implementation which will help you to choose the better approach based on the problem/scenario.
Sort based Dictionary 👀
As the name suggests this implementation is based on the arrangement of our text collection(aka Dictionary) in a sorted form. This lexicographically sorted form can be implemented in two ways, one is sorted arrays and the other one is search trees. Search over the text collection(aka dictionary) happens using binary search in case of sorted arrays and tree traversal in the case of search trees.
Hash-Based Dictionary 👀
For hash-based dictionaries, we can use hashtables. Where each term has a corresponding entry in the hashtable. Hashtables are amazingly fast when we are searching for a particular term but this has a catch too which we discuss later in the article(i.e prefix matches). Also, most of the people believe that search and insertions happen in hashtables at O(1) time complexity but IT IS NOT TRUE. To understand this you can read this answer on stackoverflow
Comparison between Hash-based and Sort based dictionaries. 🚀
- If hashtable size is chosen properly, the hashtable implementation to search for a particular term is generally faster than the Sort based dictionary. Because unlike sort based approach binary search or tree traversal is not required.
- Let us consider the query which requires prefix matches like searching "Jef*" in a dictionary should match all index terms starting with "Jef" -> Jeff Bezos, Jeffrey Archer, etc. For this requirement, hashtables will require a system to scan the whole hashtable(i.e term collection) for this whereas in a Sort based approach is it will be much faster generally ~ O(log(n)).
Because of this reason, the autocomplete feature on websites like amazon.com will be using (kind of a) prefix match over the product catalog data somewhere in the background and for it to be amazingly fast you you just cannot have it in O(n) time complexity, it has to be O(log(n)) or even less. And this data structure should preferably be an amazingly fast Search Tree.
Also, this is a major functionality that is expected from any search engine or an inverted index because at the end of the day you just want to type "lap" and get options as shown in the image here:
 (Accept it, you love this feature and you use it every day, accept this god damn it) 😜
(Accept it, you love this feature and you use it every day, accept this god damn it) 😜
But as per our human tendency, we always want to know who's better than who, right? Messi VS Ronaldo? Robert DeNiro Vs Al Pacino? dev.to VS medium? 🙄
🙋 So which one out of sort based and hash-based dictionaries is better?

Thomas Sowell once said: There Are No Solutions, Only Trade-offs.
So, considering Thomas's statement the answer is Sort based Dictionaries using the Search trees. (with decent tradeoffs in query processing time ofcourse).

Besides the prefix query support, predictable performance there is one more reason why I said "Sort based indexes are better". Ever heard of Lucene? the most popular search engine used by elastic search and Solr under the hood.
For the Memory Index Apache Lucene full-text search index, Lucene uses Sort based dictionary approach. Won't believe me check the source code yourself. Here
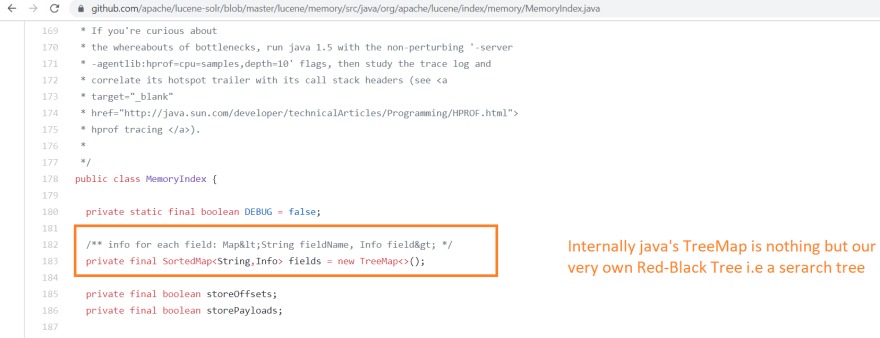
(I have asked the Lucene committers to confirm this, will update this too after getting the confirmation from them)
Bonus Gyaan:
FYI: SortedMap is nothing but a beautiful Red-Black tree. 🖖
Also, the holy "Introduction To Algorithm" by Thomas Cormem says "Red-Black trees make good search trees." with proof on page 309. I will be covering this for sure in some of my future posts. Hope you can join the links from here.
So we have discussed all the major tradeoffs between the Dictionary implementation in this article. For the next article, we will be looking into something again related to the dictionary implementation i.e the Tokenization of term. As of now we only consider "space" in between the sentences/documents to identify the terms but there are a lot of other things to be considered.
Also, hope you liked the article and it was helpful to you. As always, I am open to suggestions and feedback w.r.t the series.





Top comments (1)
thank you very much for this series.