
Créditos
- Escrito originalmente por Pete Naylor, em What really matters in DynamoDB data modeling?.
Spoiler: não é o número de tabelas!
Quando deixei a equipe do DynamoDB alguns meses atrás, decidi que precisava compartilhar o que aprendi sobre como modelar dados para o DynamoDB e operá-lo bem. Durante meus seis anos trabalhando com clientes internos e externos do DynamoDB na AWS, tive a sorte de obter exposição a uma ampla variedade de modelos de dados do DynamoDB. Eu também vi como eles evoluíram na operação: como eles foram dimensionados (ou não) utilização com carga variável, sua flexibilidade para acomodar novos requisitos de aplicativos e se eles se tornaram proibitivos em termos de custo ao longo do tempo.
Esta é a primeira parte de uma pequena série de artigos que publicarei com o objetivo de corrigir alguns equívocos sobre as práticas recomendadas de modelagem de dados do DynamoDB. Nos últimos anos, recomendações estranhas evoluíram por meio dos rumores das mídias sociais (com a ajuda do marketing da AWS). Vou escrever sobre o mundo real. Darei os mesmos conselhos que a equipe do DynamoDB dá a outras equipes da Amazon para quem o serviço é de missão crítica - as mesmas recomendações de otimização, os mesmos avisos sobre o placebo do "design de tabela única", as mesmas dicas sobre a interpretação de métricas, os mesmos detalhes nas nuâncias de mensuração e medição, e o mesmo foco na excelência operacional.
Pronto para começar? Nesse primeiro artigo, definirei as bases para a série, compartilhando o molho secreto para o sucesso com o DynamoDB. Reconheço que demorei um pouco para realmente grocar essas coisas. Me siga! Eu conheço alguns atalhos.
O que realmente importa se não é tudo sobre o número de tabelas?
Os dois primeiros conceitos que você precisa entender ao aprender modelagem de dados do DynamoDB para levar seu pensamento além dos casos de uso de chave-valor simples são:
- Flexibilidade de Esquema
- Coleções de itens
Flexibilidade de esquema significa que nem todos os itens em uma tabela do DynamoDB exigem a mesma estrutura – cada item pode ter seu próprio conjunto de atributos e tipos de dados – isso abre muitas possibilidades! Na verdade, os únicos atributos para os quais o esquema é obrigatório são os atributos de chave primária — aqueles usados para indexar os dados na tabela. Cada item deve incluir os atributos-chave definidos para a tabela com o tipo de dados correto.
Uma coleção de itens é o conjunto de todos os itens que possuem o mesmo valor de atributo que a chave de partição; em outras palavras, eles estão todos relacionados pelo valor da chave de partição. Se você estiver familiarizado com bancos de dados relacionais, uma maneira de pensar sobre isso é olhar para uma coleção de itens como sendo um pouco como um JOIN materializado, onde o valor comum do atributo de chave de partição é algo como uma chave estrangeira. Para otimizar seu modelo de dados do DynamoDB, você deve procurar oportunidades para usar coleções de itens na tabela base ou em índices secundários, especialmente itens que se relacionam e que seriam buscados (seletivamente) juntos. Isso pode parecer óbvio, mas vale a pena deixar claro: para estar na mesma coleção de itens, os itens também precisam estar na mesma tabela – a coleção de itens é um subconjunto da tabela.
Por exemplo, você pode representar um carrinho de compras como uma coleção de itens, em que o identificador exclusivo do carrinho (Pete's Cart) é o valor da chave de partição e o identificador de cada produto adicionado ao carrinho é o valor da chave de ordenação (sort). Aparentemente, Pete gosta mais de café do que de vegetais, mas não tanto quanto de chocolates. O número de cada tipo de produto no carrinho é outro atributo (não-chave). A imagem abaixo descreve tal coleção de itens.

Seu código tem uma definição mais rígida, como a captura de tela do NoSQL Workbench abaixo.

As coleções de itens podem existir no índice primário (a tabela base) e/ou em um índice secundário. Vou me aprofundar nos detalhes dos índices secundários em um artigo futuro, então vamos nos concentrar na tabela base. As coleções de itens na tabela base requerem uma chave primária composta (chave de partição e chave de ordenação). Se não houver índices secundários locais (LSIs), a coleção de itens pode abranger várias partições do DynamoDB — ela não começará dessa forma, mas o DynamoDB dividirá automaticamente a coleção de itens entre as partições para acomodar o crescente volume de dados e, às vezes, ele também pode distribuir a coleção de itens entre as partições para fornecer uma taxa de transferência generalizada ou para isolar itens mais quentes (ou intervalos de itens).
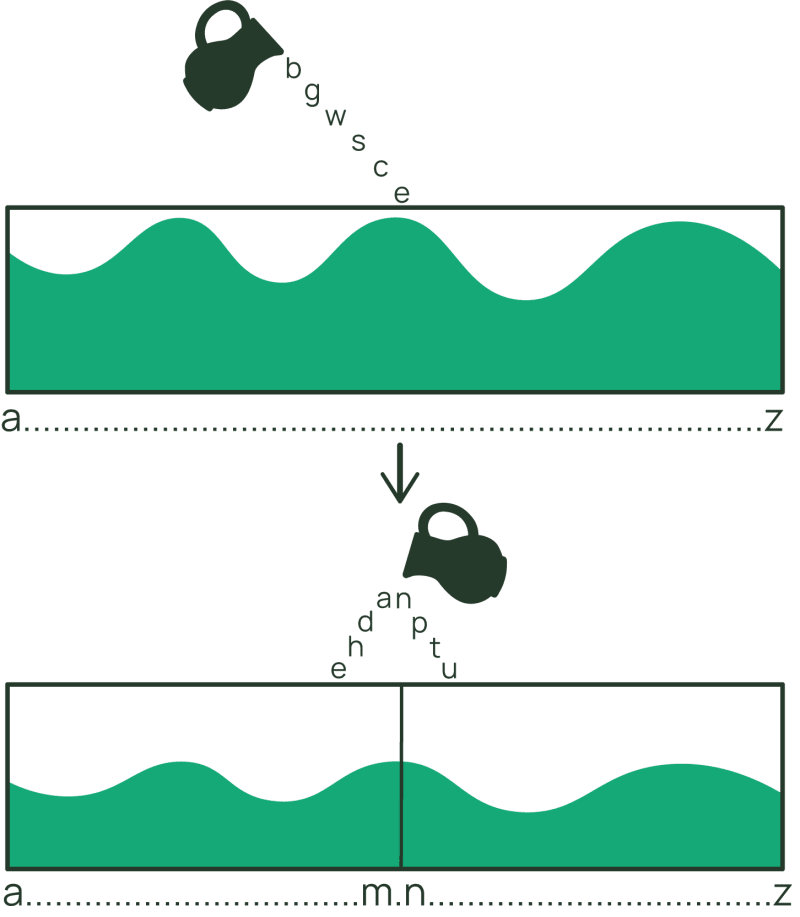
É útil pensar em itens e coleções de itens como sendo dois tipos diferentes de registros no DynamoDB. Em uma tabela base com uma chave primária simples (sem chave de ordenação definida), você trabalha inteiramente com itens. Mas se sua tabela tiver uma chave primária composta (chave de partição + chave de ordenação), você trabalhará com coleções de itens. Os itens na coleção são armazenados na ordem dos valores da chave de ordenação e podem ser retornados na ordem descendente ou ascendente.
Uma coleção de itens é mágica – ela nos permite armazenar e recuperar itens relacionados juntos de forma eficiente. Os itens na coleção podem ter esquemas diferentes (o DynamoDB é flexível, lembra?) — cada um representando uma parte do registro geral da coleção de itens.
Se você tiver um item de 200 KB, atualizar até mesmo uma pequena parte desse item consumirá 200 unidades de escrita. Se, ao invés disso, esse item for armazenado como uma coleção de partes de itens em uma coleção, você poderá atualizar qualquer pequena parte para um consumo mínimo de unidade de escrita. Ei, mas isso é só o começo!
Você pode usar a operação Query para recuperar todos os itens da coleção ou apenas aqueles com um intervalo específico de valores de chave de ordenação. A especificação para o intervalo é chamada de condição de chave de ordenação (sort key condition). Dentro da coleção de itens, você pode limitar os itens recuperados para serem aqueles com uma chave de ordenação menor que um valor escolhido, ou maior que, ou mesmo entre dois valores.
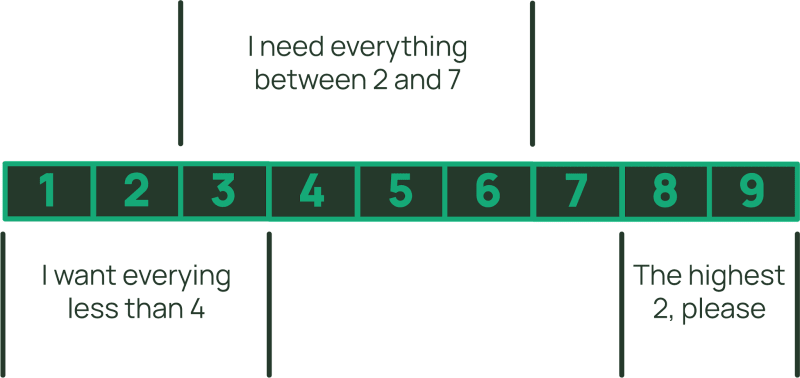
Para chaves de ordenação em strings, você também pode usar begin_with (que na verdade é apenas uma variação de between, se você pensar bem). A aplicação de uma condição de chave de ordenação limita efetivamente o intervalo de itens a serem retornados da coleção de itens. É importante ressaltar que apenas os itens da coleção que correspondem à condição da chave de ordenação serão incluídos na medição das unidades de leitura (read units). Isso contrasta com uma expressão de filtro que se aplica após a avaliação das unidades de leitura - portanto, você ainda paga para ler os itens filtrados. Quando você recupera vários itens usando Query (ou Scan), a medição do consumo da unidade de leitura adiciona os tamanhos de todos os itens e depois arredonda para o próximo limite de 4KB (ao invés de arredondar para cada item como GetItem e BatchGetItem fazem). Assim, as coleções de itens permitem que você armazene registros muito grandes, atualize partes seletivas a baixo custo e recupere-as com eficiência ideal.
Coleções de itens (Query) e Scan são, na verdade, os únicos diferenciadores atraentes de custo e desempenho que defendem o armazenamento de dois itens na mesma tabela. Ambos permitem a recuperação de vários itens com os tamanhos de itens agregados arredondados para o próximo limite de 4 KB. Se você não for indexar dois itens juntos na mesma coleção de itens (tabela ou índice secundário) e não quiser retornar ambos de cada Scan, não há vantagem em mantê-los na mesma tabela. Mas certamente existem algumas desvantagens que abordarei um pouco mais tarde. Para todas as outras operações de dados (incluindo vários itens como BatchGetItem, TransactWriteItems, etc), o DynamoDB não se importa se os itens estão na mesma tabela ou não - você verá a mesma medição de armazenamento/taxa de transferência e o mesmo desempenho de qualquer jeito.
As vezes, para reunir os dados na mesma coleção de itens, você precisa fazer alguns ajustes nos valores da chave primária. Para ser armazenado na mesma tabela, a mesma definição de chave primária deve ser usada. Exemplos disso incluem armazenar um valor numérico como uma string para corresponder ao tipo de dados da chave de partição ou chave de ordenação ou criar um valor exclusivo para a chave de ordenação onde você não necessariamente tem algo importante para armazenar (usando o mesmo valor que o atributo de chave de partição é comum para isso ao criar um item de "metadados" na coleção).
Imagine uma tabela para armazenar pedidos de clientes para envio. A chave de partição é um identificador de pedido numérico exclusivo (o tipo de dados é número) e você deseja usar uma coleção para armazenar um registro por item de itens do carrinho (identificado por um SKU numérico) e eventos de rastreamento (identificados por um UUID ordenável, como ksuid) para processamento de pedidos. Você deseja recuperá-los juntos para eficiência porque o padrão mais comum é fornecer uma página de rastreamento com os itens comprados mostrados além dos detalhes de rastreamento. Nesse caso, você precisará definir a chave de ordenação com tipo de dados string e converter valores para armazenar esses SKUs numéricos como strings. Há um custo para isso (porque armazenar um número como uma string consome mais bytes), mas vale a pena para obter o benefício da coleção de itens.
Como é fácil acomodar essas alterações ao escrever seus itens na tabela, um desenvolvedor pode fazer isso apenas para todos os itens e coleções de itens, certo? E colocá-los todos na mesma tabela? Faria sentido para todos os clientes do DynamoDB se unirem e armazenarem seus dados em uma tabela multi-tenant gigante? Não, claro que não. Essas técnicas têm um custo e só devem ser usadas quando puderem ser justificadas - para colher os benefícios das coleções de itens.
Finalizando
A parte valiosa e válida da orientação de "design de tabela única" é simplesmente esta:
- Use a flexibilidade de esquema e as coleções de itens do DynamoDB para otimizar seu modelo de dados para os padrões de acesso que você precisa cobrir.
Se você estiver migrando de um banco de dados relacional, provavelmente terminará com menos tabelas do que seu antigo modelo totalmente normalizado. Você provavelmente terá mais de uma tabela e deve usar qualquer número de Índices Secundários Globais (GSIs) necessários para atender aos seus padrões secundários.
Sim, é isso. Realmente nunca houve necessidade de criar uma nova terminologia. O "design de tabela única" confundiu algumas pessoas e levou muitas outras a um caminho doloroso, complexo e caro (detalhes sobre isso em um próximo artigo) quando foi interpretado literalmente e, em seguida, deturpado como "melhor prática".
É hora de deixar essa terminologia de lado - ficar com a flexibilidade do esquema e as coleções de itens.
Se você quiser discutir esse tópico comigo, obter minha opinião sobre uma pergunta de modelagem de dados do DynamoDB que você tem ou sugerir tópicos para eu escrever em artigos futuros, entre em contato comigo no Twitter (@pj_naylor) ou envie-me um [e-mail diretamente]mailto:petenaylor@momentohq.com)!
Fique de olho em artigos futuros em que discutirei as nuâncias de LSIs e GSIs e explicarei por que a "sobrecarga de GSI" é um padrão de modelagem de araque.
Se você quiser discutir esse tópico comigo, obter minha opinião sobre uma pergunta de modelagem de dados do DynamoDB que você tem ou sugerir tópicos para eu escrever em artigos futuros, entre em contato comigo no Twitter (@pj_naylor) ou envie-me um [e-mail diretamente]mailto:petenaylor@momentohq.com)!
Apêndice: O que eu saberia sobre o DynamoDB afinal?
Até recentemente, eu trabalhava na AWS. Comecei como gerente técnico de contas em 2016 na equipe de contas que oferece suporte à Amazon.com como cliente corporativo da AWS. Minha área de foco era ajudar a Amazon a atingir algumas metas organizacionais ambiciosas: 1) migrar projetos críticos de bancos de dados transacionais de bancos de dados relacionais tradicionais para bancos de dados distribuídos desenvolvidos especificamente para computação em nuvem (como DynamoDB); 2) cargas transacionais de segundo nível "lift and shift" do Oracle para o Aurora; e 3) mover todo o armazenamento de dados do Oracle para o Redshift. Foi uma experiência fantástica em geral, mas a parte que mais gostei foi testemunhar a redução drástica na carga operacional e as melhorias na disponibilidade e latência que o DynamoDB proporcionou. Trabalhei com centenas de equipes de desenvolvedores da Amazon.com para revisar seus modelos de dados, ensiná-los sobre como gerenciar limites, dimensionamento, alarmes e painéis do DynamoDB. Sentei-me nas salas de guerra para eventos de pico, como o Prime Day, como ponto de contato para qualquer tipo de preocupação relacionada ao DynamoDB que surgisse com o rápido crescimento do tráfego de eventos. Não foi fácil para todos fazer a mudança de paradigma do modelo de dados, mas quando esse programa foi concluído, todos os desenvolvedores rapidamente passaram a considerar todas as vantagens garantidas do DynamoDB. Eles passaram a dedicar muito mais tempo às coisas que faziam a diferença para seus clientes — ver isso me impressionou profundamente.
Em 2018, tornei-me um arquiteto de soluções especializado em DynamoDB — parte de uma pequena equipe que trabalha com os maiores clientes corporativos (externos) da AWS. Eu os ajudei a desenvolver modelos de dados DynamoDB eficazes e eficientes para uma ampla variedade de casos de uso e padrões de acesso, e ensinei muitos desenvolvedores a operar bem com o DynamoDB. Meus últimos 18 meses na AWS foram gastos como gerente de produto para o serviço DynamoDB. Também dei centenas de consultorias a engenheiros de várias equipes de serviço da AWS como parte de um programa de "office hours" para o DynamoDB — revisando modelos de dados, fornecendo orientação de arquitetura mais ampla e ensinando sobre como o DynamoDB funciona e os insights revelados pelas métricas.
Tudo isso é para dizer que já vi muitos casos de uso de produção para o DynamoDB (de centenas de solicitações por dia a milhões de solicitações por segundo) e tenho uma forte noção da maneira como os desenvolvedores (na Amazon.com, dentro da AWS e em muitas outras empresas ao redor do mundo) estão realmente usando o DynamoDB na prática.





Top comments (1)
As imagens estão com dois links concatenados, por isso está aparacendo quebrado pra mim. Se copiar o link da imagem e extrair o segundo http (dev.to) é possível abrir a imagem em uma nova aba do navegador.