
Intro
Currently, we don't have an API that supports extracting data from Brave Search.
This blog post is to show you way how you can do it yourself with provided DIY solution below while we're working on releasing our proper API.
The solution can be used for personal use as it doesn't include the Legal US Shield that we offer for our paid production and above plans and has its limitations such as the need to bypass blocks, for example, CAPTCHA.
You can check our public roadmap to track the progress for this API: [New API] Brave Search
What will be scraped
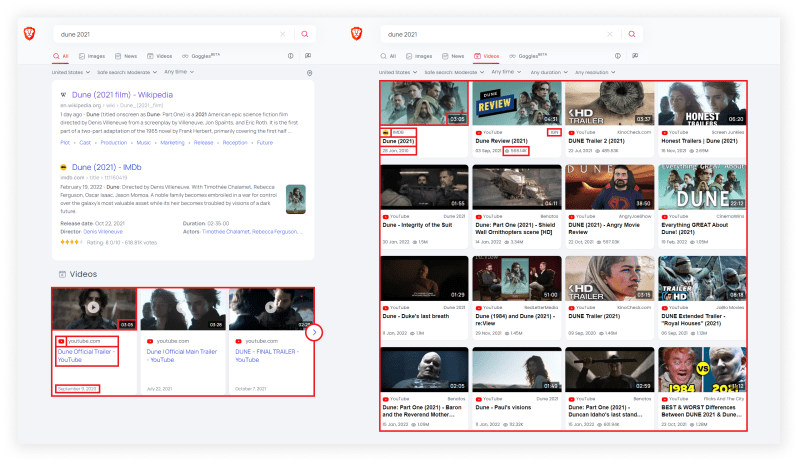
📌Note: Sometimes there may be no videos in the organic search results. This blog post gets videos from organic results and videos tab.
What is Brave Search
The previous Brave blog post previously described what is Brave search. For the sake of non-duplicating content, this information is not mentioned in this blog post.
Full Code
If you don't need explanation, have a look at full code example in the online IDE.
from bs4 import BeautifulSoup
import requests, lxml, json, re
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
'q': 'dune 2021', # query
'source': 'web', # source
'tf': 'at', # publish time (at - any time, pd - past day, pw - past week, pm - past month)
'length': 'all', # duration (short, medium, long)
'resolution': 'all' # resolution (1080p, 720p, 480p, 360p)
}
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
def scrape_organic_videos():
html = requests.get('https://search.brave.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
data = []
for result in soup.select('#video-carousel .card'):
title = result.select_one('.title').get_text()
link = result.get('href')
source = result.select_one('.anchor').get_text().strip()
date = result.select_one('.text-xs').get_text().strip()
favicon = result.select_one('.favicon').get('src')
# https://regex101.com/r/7OA1FS/1
thumbnail = re.search(r"background-image:\surl\('(.*)'\)", result.select_one('.img-bg').get('style')).group(1)
video_duration = (
result.select_one('.duration').get_text()
if result.select_one('.duration')
else None
)
data.append({
'title': title,
'link': link,
'source': source,
'date': date,
'favicon': favicon,
'thumbnail': thumbnail,
'video_duration': video_duration
})
return data
def scrape_tab_videos():
html = requests.get('https://search.brave.com/videos', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
data = []
for result in soup.select('.card'):
title = result.select_one('.title').get_text()
link = result.select_one('a').get('href')
source = result.select_one('.center-horizontally .ellipsis').get_text().strip()
date = result.select_one('#results span').get_text().strip()
favicon = result.select_one('.favicon').get('src')
# https://regex101.com/r/7OA1FS/1
thumbnail = re.search(r"background-image:\surl\('(.*)'\)", result.select_one('.img-bg').get('style')).group(1)
creator = (
result.select_one('.creator').get_text().strip()
if result.select_one('.creator')
else None
)
views = (
result.select_one('.stat').get_text().strip()
if result.select_one('.stat')
else None
)
video_duration = (
result.select_one('.duration').get_text()
if result.select_one('.duration')
else None
)
data.append({
'title': title,
'link': link,
'source': source,
'creator': creator,
'date': date,
'views': views,
'favicon': favicon,
'thumbnail': thumbnail,
'video_duration': video_duration,
})
return data
if __name__ == "__main__":
# brave_organic_videos = scrape_organic_videos()
# print(json.dumps(brave_organic_videos, indent=2, ensure_ascii=False))
brave_tab_videos = scrape_tab_videos()
print(json.dumps(brave_tab_videos, indent=2, ensure_ascii=False))
Preparation
Install libraries:
pip install requests lxml beautifulsoup4
Basic knowledge scraping with CSS selectors
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective.
Reduce the chance of being blocked
Make sure you're using request headers user-agent to act as a "real" user visit. Because default requests user-agent is python-requests and websites understand that it's most likely a script that sends a request. Check what's your user-agent.
There's a how to reduce the chance of being blocked while web scraping blog post that can get you familiar with basic and more advanced approaches.
Code Explanation
Import libraries:
from bs4 import BeautifulSoup
import requests, lxml, json, re
| Library | Purpose |
|---|---|
BeautifulSoup |
to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree. |
requests |
to make a request to the website. |
lxml |
to process XML/HTML documents fast. |
json |
to convert extracted data to a JSON object. |
re |
to extract parts of the data via regular expression. |
Create URL parameters and request headers:
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
'q': 'dune 2021', # query
'source': 'web', # source
'tf': 'at', # publish time (at - any time, pd - past day, pw - past week, pm - past month)
'length': 'all', # duration (short, medium, long)
'resolution': 'all' # resolution (1080p, 720p, 480p, 360p)
}
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
| Code | Explanation |
|---|---|
params |
a prettier way of passing URL parameters to a request. |
user-agent |
to act as a "real" user request from the browser by passing it to request headers. Default requests user-agent is a python-reqeusts so websites might understand that it's a bot or a script and block the request to the website. Check what's your user-agent. |
Scrape organic videos
This function scrapes all organic videos data for the https://search.brave.com/search URL and returns a list with all results.
You need to make a request, pass the created request parameters and headers. The request returns HTML to BeautifulSoup:
html = requests.get('https://search.brave.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
| Code | Explanation |
|---|---|
timeout=30 |
to stop waiting for response after 30 seconds. |
BeautifulSoup() |
where returned HTML data will be processed by bs4. |
Create the data list to store all videos:
data = []
To extract the necessary data, you need to find the selector where they are located. In our case, this is the #video-carousel .card selector, which contains all organic videos. You need to iterate each video in the loop:
for result in soup.select('#video-carousel .card'):
# data extraction will be here
To extract the data, you need to find the matching selectors. SelectorGadget was used to grab CSS selectors. I want to demonstrate how the selector selection process works:
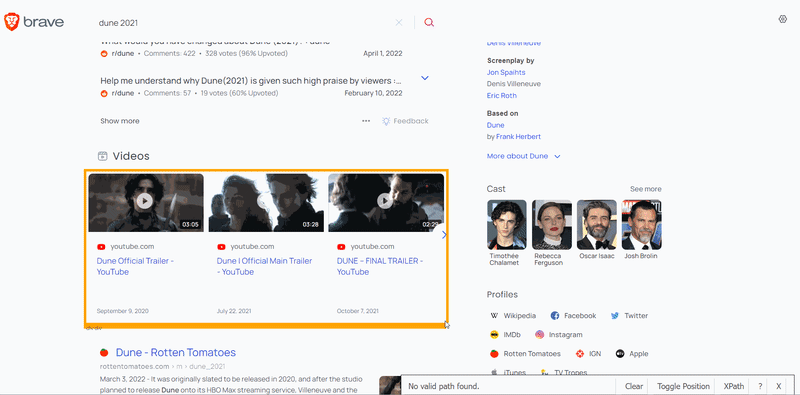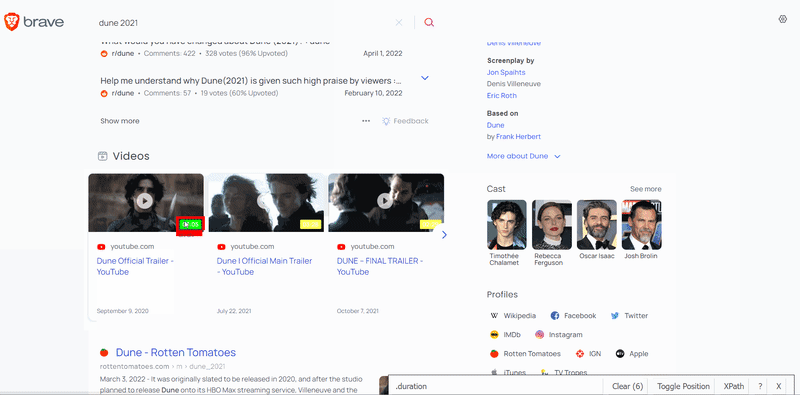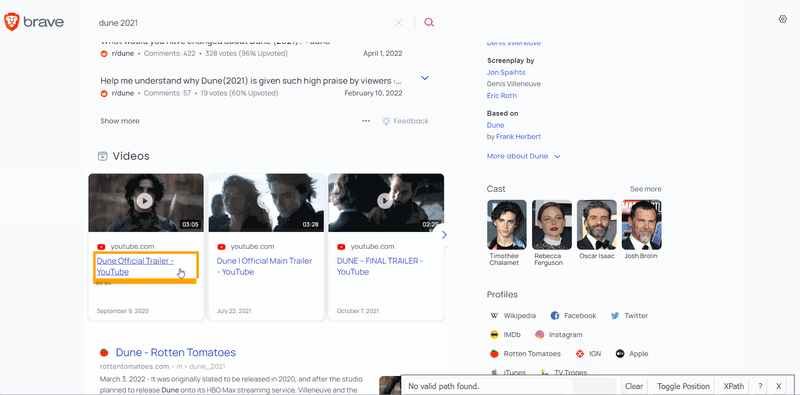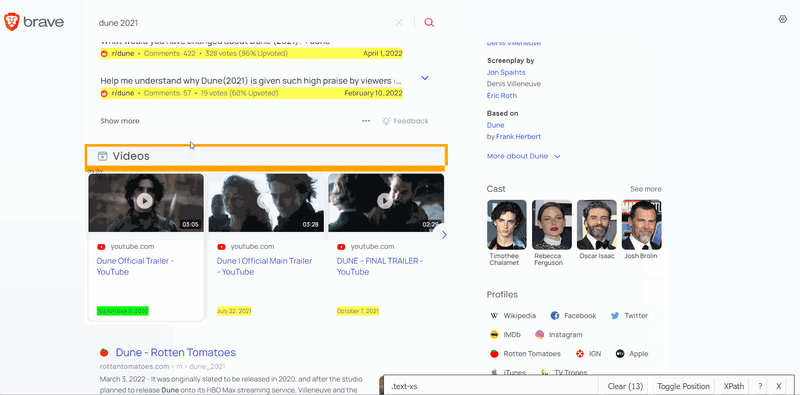
After the selectors are found, we need to get the corresponding text or attribute value. I want to draw your attention to the fact that the thumbnail is extracted in a different way. The desired image link is hidden inside the style attribute. To extract this link, you need to do a lot of operations on the string. Instead, you can use regular expression to extract the required data:
title = result.select_one('.title').get_text()
link = result.get('href')
source = result.select_one('.anchor').get_text().strip()
date = result.select_one('.text-xs').get_text().strip()
favicon = result.select_one('.favicon').get('src')
# https://regex101.com/r/7OA1FS/1
thumbnail = re.search(r"background-image:\surl\('(.*)'\)", result.select_one('.img-bg').get('style')).group(1)
video_duration = (
result.select_one('.duration').get_text()
if result.select_one('.duration')
else None
)
📌Note: When extracting the video_duration, a ternary expression is used which handles the values of these data, if any are available.
| Code | Explanation |
|---|---|
select_one()/select() |
to run a CSS selector against a parsed document and return all the matching elements. |
get_text() |
to get textual data from the node. |
get(<attribute>) |
to get attribute data from the node. |
strip() |
to return a copy of the string with the leading and trailing characters removed. |
search() |
to search for a pattern in a string and return the corresponding match object. |
group() |
to extract the found element from the match object. |
After the data from item is retrieved, it is appended to the data list:
data.append({
'title': title,
'link': link,
'source': source,
'date': date,
'favicon': favicon,
'thumbnail': thumbnail,
'video_duration': video_duration
})
The complete function to scrape organic videos would look like this:
def scrape_organic_videos():
html = requests.get('https://search.brave.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
data = []
for result in soup.select('#video-carousel .card'):
title = result.select_one('.title').get_text()
link = result.get('href')
source = result.select_one('.anchor').get_text().strip()
date = result.select_one('.text-xs').get_text().strip()
favicon = result.select_one('.favicon').get('src')
# https://regex101.com/r/7OA1FS/1
thumbnail = re.search(r"background-image:\surl\('(.*)'\)", result.select_one('.img-bg').get('style')).group(1)
video_duration = (
result.select_one('.duration').get_text()
if result.select_one('.duration')
else None
)
data.append({
'title': title,
'link': link,
'source': source,
'date': date,
'favicon': favicon,
'thumbnail': thumbnail,
'video_duration': video_duration
})
return data
Output:
[
{
"title": "Dune | Official Main Trailer - YouTube",
"link": "https://www.youtube.com/watch?v=8g18jFHCLXk",
"source": "youtube.com",
"date": "July 22, 2021",
"favicon": "https://imgs.search.brave.com/Ux4Hee4evZhvjuTKwtapBycOGjGDci2Gvn2pbSzvbC0/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvOTkyZTZiMWU3/YzU3Nzc5YjExYzUy/N2VhZTIxOWNlYjM5/ZGVjN2MyZDY4Nzdh/ZDYzMTYxNmI5N2Rk/Y2Q3N2FkNy93d3cu/eW91dHViZS5jb20v",
"thumbnail": "https://imgs.search.brave.com/E6_Wv3qlA5iqnRkLZILt8tq-lLKCHVwJESItayT5jro/rs:fit:200:200:1/g:ce/aHR0cHM6Ly9pLnl0/aW1nLmNvbS92aS84/ZzE4akZIQ0xYay9t/YXhyZXNkZWZhdWx0/LmpwZw",
"video_duration": "03:28"
},
{
"title": "Dune Official Trailer - YouTube",
"link": "https://www.youtube.com/watch?v=n9xhJrPXop4",
"source": "youtube.com",
"date": "September 9, 2020",
"favicon": "https://imgs.search.brave.com/Ux4Hee4evZhvjuTKwtapBycOGjGDci2Gvn2pbSzvbC0/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvOTkyZTZiMWU3/YzU3Nzc5YjExYzUy/N2VhZTIxOWNlYjM5/ZGVjN2MyZDY4Nzdh/ZDYzMTYxNmI5N2Rk/Y2Q3N2FkNy93d3cu/eW91dHViZS5jb20v",
"thumbnail": "https://imgs.search.brave.com/uNV6ho7lr6Z-67_BgPPOp56rj-aVny1loaiYzGyLwQk/rs:fit:200:200:1/g:ce/aHR0cHM6Ly9pLnl0/aW1nLmNvbS92aS9u/OXhoSnJQWG9wNC9t/YXhyZXNkZWZhdWx0/LmpwZw",
"video_duration": "03:05"
},
{
"title": "DUNE – FINAL TRAILER - YouTube",
"link": "https://www.youtube.com/watch?v=w0HgHet0sxg",
"source": "youtube.com",
"date": "October 7, 2021",
"favicon": "https://imgs.search.brave.com/Ux4Hee4evZhvjuTKwtapBycOGjGDci2Gvn2pbSzvbC0/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvOTkyZTZiMWU3/YzU3Nzc5YjExYzUy/N2VhZTIxOWNlYjM5/ZGVjN2MyZDY4Nzdh/ZDYzMTYxNmI5N2Rk/Y2Q3N2FkNy93d3cu/eW91dHViZS5jb20v",
"thumbnail": "https://imgs.search.brave.com/-irGOLELOj8B0YDVJU5dHgpWsd8nSx2l3yrVARUlv0E/rs:fit:200:200:1/g:ce/aHR0cHM6Ly9pLnl0/aW1nLmNvbS92aS93/MEhnSGV0MHN4Zy9t/YXhyZXNkZWZhdWx0/LmpwZw",
"video_duration": "02:29"
},
... other videos
]
Scrape tab videos
This function scrapes all tab videos data for the https://search.brave.com/videos URL and returns a list with all results.
You need to make a request, pass the created request parameters and headers. The request returns HTML to BeautifulSoup:
html = requests.get('https://search.brave.com/videos', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
Create the data list to store all videos:
data = []
To retrieve data from all videos in the page, you need to find the .card selector of the items. You need to iterate each item in the loop:
for result in soup.select('.card'):
# data extraction will be here
On this page, the matching selectors are different. So this function also used SelectorGadget to grab CSS selectors. I want to demonstrate how the selector selection process works:
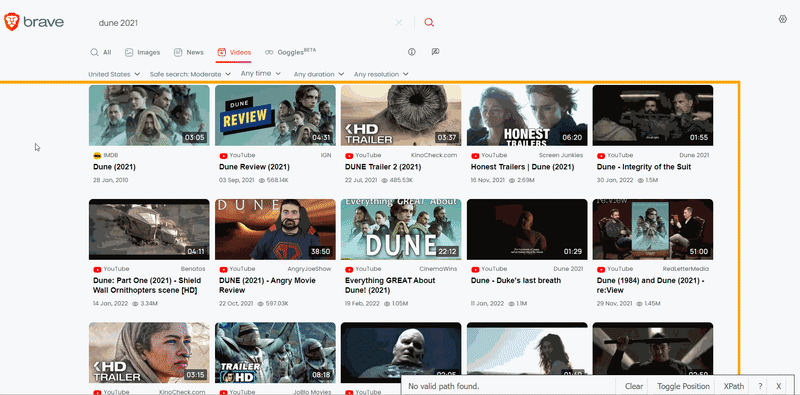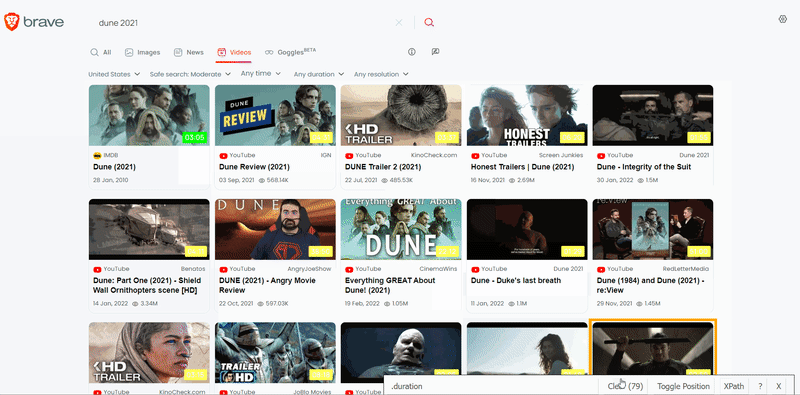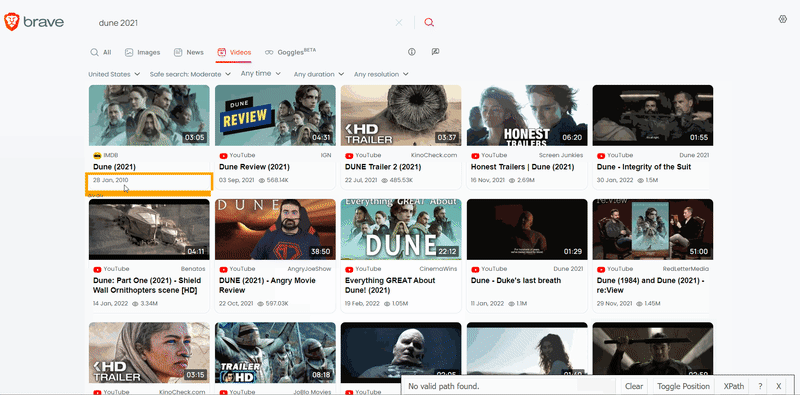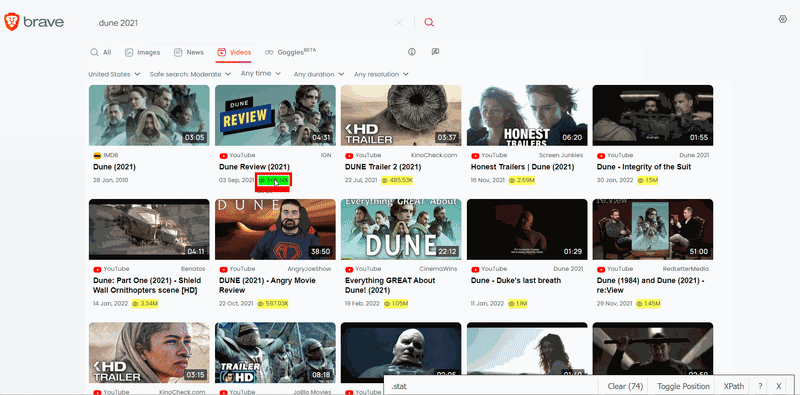
The difference between extracting data in this function is that here you can get a creator and views:
title = result.select_one('.title').get_text()
link = result.select_one('a').get('href')
source = result.select_one('.center-horizontally .ellipsis').get_text().strip()
date = result.select_one('#results span').get_text().strip()
favicon = result.select_one('.favicon').get('src')
# https://regex101.com/r/7OA1FS/1
thumbnail = re.search(r"background-image:\surl\('(.*)'\)", result.select_one('.img-bg').get('style')).group(1)
creator = (
result.select_one('.creator').get_text().strip()
if result.select_one('.creator')
else None
)
views = (
result.select_one('.stat').get_text().strip()
if result.select_one('.stat')
else None
)
video_duration = (
result.select_one('.duration').get_text()
if result.select_one('.duration')
else None
)
📌Note: When extracting the creator, views and video_duration, a ternary expression is used which handles the values of these data, if any are available.
After the data from item is retrieved, it is appended to the data list:
data.append({
'title': title,
'link': link,
'source': source,
'creator': creator,
'date': date,
'views': views,
'favicon': favicon,
'thumbnail': thumbnail,
'video_duration': video_duration,
})
The complete function to scrape tab videos would look like this:
def scrape_tab_videos():
html = requests.get('https://search.brave.com/videos', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
data = []
for result in soup.select('.card'):
title = result.select_one('.title').get_text()
link = result.select_one('a').get('href')
source = result.select_one('.center-horizontally .ellipsis').get_text().strip()
date = result.select_one('#results span').get_text().strip()
favicon = result.select_one('.favicon').get('src')
# https://regex101.com/r/7OA1FS/1
thumbnail = re.search(r"background-image:\surl\('(.*)'\)", result.select_one('.img-bg').get('style')).group(1)
creator = (
result.select_one('.creator').get_text().strip()
if result.select_one('.creator')
else None
)
views = (
result.select_one('.stat').get_text().strip()
if result.select_one('.stat')
else None
)
video_duration = (
result.select_one('.duration').get_text()
if result.select_one('.duration')
else None
)
data.append({
'title': title,
'link': link,
'source': source,
'creator': creator,
'date': date,
'views': views,
'favicon': favicon,
'thumbnail': thumbnail,
'video_duration': video_duration,
})
return data
Output:
[
{
"title": "Dune (2021)",
"link": "https://www.imdb.com/title/tt1160419/",
"source": "IMDB",
"creator": null,
"date": "28 Jan, 2010",
"views": null,
"favicon": "https://imgs.search.brave.com/_XzIkQDCEJ7aNlT3HlNUHBRcj5nQ9R4TiU4cHpSn7BY/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvZmU3MjU1MmUz/MDhkYjY0OGFlYzY3/ZDVlMmQ4NWZjZDhh/NzZhOGZlZjNjNGE5/M2M0OWI1Y2M2ZjQy/MWE5ZDc3OC93d3cu/aW1kYi5jb20v",
"thumbnail": "https://imgs.search.brave.com/zHiJ3yZ-f7a99EkHYp8nB2BD0XvWk5fKq-dcukd5Jro/rs:fit:235:225:1/g:ce/aHR0cHM6Ly90c2U0/Lm1tLmJpbmcubmV0/L3RoP2lkPU9WUC43/WUM5TEhVTGxFaEFm/VGNVNzZqZGRBRmVJ/SSZwaWQ9QXBp",
"video_duration": "03:05"
},
{
"title": "Dune Review (2021)",
"link": "https://www.youtube.com/watch?v=DqquKCvOxwA",
"source": "YouTube",
"creator": "IGN",
"date": "03 Sep, 2021",
"views": "568.14K",
"favicon": "https://imgs.search.brave.com/Ux4Hee4evZhvjuTKwtapBycOGjGDci2Gvn2pbSzvbC0/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvOTkyZTZiMWU3/YzU3Nzc5YjExYzUy/N2VhZTIxOWNlYjM5/ZGVjN2MyZDY4Nzdh/ZDYzMTYxNmI5N2Rk/Y2Q3N2FkNy93d3cu/eW91dHViZS5jb20v",
"thumbnail": "https://imgs.search.brave.com/Eru5tXsCCm42JOqGxc3XsNe8RPs0_Fk1Bs0AVvmpDQE/rs:fit:640:225:1/g:ce/aHR0cHM6Ly90c2Ux/Lm1tLmJpbmcubmV0/L3RoP2lkPU9WUC5q/TU5XYmtTdGFHalJY/X0JSQm1mUV9RSGdG/byZwaWQ9QXBp",
"video_duration": "04:31"
},
{
"title": "DUNE Trailer 2 (2021)",
"link": "https://www.youtube.com/watch?v=LG7QhzmavZg",
"source": "YouTube",
"creator": "KinoCheck.com",
"date": "22 Jul, 2021",
"views": "485.53K",
"favicon": "https://imgs.search.brave.com/Ux4Hee4evZhvjuTKwtapBycOGjGDci2Gvn2pbSzvbC0/rs:fit:32:32:1/g:ce/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvOTkyZTZiMWU3/YzU3Nzc5YjExYzUy/N2VhZTIxOWNlYjM5/ZGVjN2MyZDY4Nzdh/ZDYzMTYxNmI5N2Rk/Y2Q3N2FkNy93d3cu/eW91dHViZS5jb20v",
"thumbnail": "https://imgs.search.brave.com/XHCBNZHpAHNxvYqWYgfhYKKinSHXdYjI3e5HtsgVjcg/rs:fit:640:225:1/g:ce/aHR0cHM6Ly90c2Uy/Lm1tLmJpbmcubmV0/L3RoP2lkPU9WUC5q/VXZ2aE1Md1hfWUtM/OHZsU0l3SFJRSGdG/byZwaWQ9QXBp",
"video_duration": "03:37"
},
... other videos
]
Links
Add a Feature Request💫 or a Bug🐞





Top comments (0)