
🔰 Beginners new to AWS CDK, please do look at my previous articles one by one in this series.
If in case missed my previous article, do find it with the below links.
🔁 Original previous post at 🔗 Dev Post
🔁 Reposted previous post at 🔗 dev to @aravindvcyber
In this article, let us add refine my previous article which demonstrated making use of a batch of dynamodb stream to delete items from another table. Here we convert the simple deleteItem action into a batchWrite action, which has great advantages.
Benefits in this approach 💦
- As earlier discussed in the previous article we are trying to make this scavenging setup as efficient as possible.
- This integration is fully asynchronous and does not block the existing process flow, and it uses the least amount of API calls and resources as discussed below.
- Involving
batchWritemakes us make delete operation on a maximum chunk size of 25. - Since only one request is used in place of 25 calls, write request throttling scenarios can also be avoided when we have smaller provisioned capacities.
- By then you also have to check the
UnprocessedItemsto retry any failed keys if it is returned in the worst cases. - In a summary including the previous article, we are now able to perform a batch get stream object with a size of 100 max which in turn performs a batch write of 25 max at a time.
- Fewer handler invocations and fewer dynamodb API calls.

Planning and Construction 🚣
As already mentioned we will optimize the previous deleteItem helper function and convert our stream invocation into a batchWrite action on dynamodb table with chunks of 25 max.
Starting with refractor my previous lambda a bit to achieve the desired effects optimizing goals.
Here you may find that we are targeting an event name to be INSERT, likewise we can have finer control over our desired outcome during these stream invocations as shown below.
Imports necessary 💮
The below imports are using in this article.
import { DynamoDBStreams } from "aws-sdk";
import {
DeleteItemInput,
BatchWriteItemInput,
WriteRequest,
} from "aws-sdk/clients/dynamodb";
New handler function logic ⚓
Here we have optimized the lambda handler as follows, this involves creating a keyMap from the stream data, and further slicing this into chunks of a maximum of 25 to perform batchWrite operation invoking our helper method.
exports.created = async function (event: any) {
console.log("Received stream:", JSON.stringify(event, undefined, 2));
const keyMap: any[] = [];
event.Records.map((Record: DynamoDBStreams.Record) => {
console.log(JSON.stringify(Record, undefined, 2));
if (Record.eventName === "INSERT") {
keyMap.push(Record.dynamodb?.Keys);
}
});
const chunkList = [...chunks(keyMap, 25)];
await Promise.all(
chunkList.map(async (chunk: any[]) => {
const results = await batchDeleteDbItems(chunk);
Object.entries(results).forEach((entry) => {
console.log(JSON.stringify(entry, undefined, 2));
});
})
);
};
Helper function dynamodb deleteItem 💐
Simple helper function to perform deleteItem from a dynamodb table.
Here we use the key list to generate a collection of WriteRequest of Delete action as follows.
const batchDeleteDbItems: any = async (keys: any) => {
console.log("Deleting: ", { keys });
const writeItems: WriteRequest[] = [];
keys.map((key: any) => {
const writeItem: WriteRequest = {
DeleteRequest: {
Key: {
...key,
},
},
};
writeItems.push(writeItem);
});
const params: BatchWriteItemInput = {
RequestItems: {
stgMessagesTable: writeItems,
},
ReturnConsumedCapacity: "TOTAL",
ReturnItemCollectionMetrics: "SIZE",
};
console.log("deleteItem: ", JSON.stringify(params, undefined, 2));
return await dynamo.batchWriteItem(params).promise();
};
Minor changes to the dynamodb table definition 🍊
I have highlighted the necessary changes, we need to perform dynamodb stream generation for our table.
Most importantly, I have requested only keys, which will have all the necessary data we need here.
Besides in this article, we are trying to optimize as much as we could for the least footprint.
const messages = new dynamodb.Table(this, "MessagesTable", {
tableName: process.env.messagesTable,
sortKey: { name: "createdAt", type: dynamodb.AttributeType.NUMBER },
partitionKey: { name: "messageId", type: dynamodb.AttributeType.STRING },
encryption: dynamodb.TableEncryption.AWS_MANAGED,
readCapacity: 5,
writeCapacity: 5,
stream: dynamodb.StreamViewType.KEYS_ONLY
});

Sample dynamodb stream with one record 🥣
I have shared the dynamodb stream object used as payload to invoke our handler lambda below.
{
"eventID": "961320567faf6d890d6498a08fd1f34c",
"eventName": "INSERT",
"eventVersion": "1.1",
"eventSource": "aws:dynamodb",
"awsRegion": "ap-south-1",
"dynamodb": {
"ApproximateCreationDateTime": 1652637075,
"Keys": {
"createdAt": {
"N": "1652637067000"
},
"messageId": {
"S": "615f1e20-8261-4492-bb69-c281d3ea3382"
}
},
"SequenceNumber": "36634400000000018872472773",
"SizeBytes": 61,
"StreamViewType": "KEYS_ONLY"
},
"eventSourceARN": "arn:aws:dynamodb:ap-south-1:57*****7078*****55:table/MessagesTable/stream/2022-05-15T17:48:27.902"
}
Console log during execution 🍿
Finally post-execution, we could find the above JSON payload we have received in the event object and which is then used to batch delete from our staging table. You may find the results below in cloud watch logs.
Here a simple k6 load test is performed for a period of 15s with 10 targets and we can get 27 requests of which 25 are successful. the 2 failed because of the rate limit in our API gateway.

Cloudwatch logs with 25 records of keys ⛲

BatchWrite result ⛲
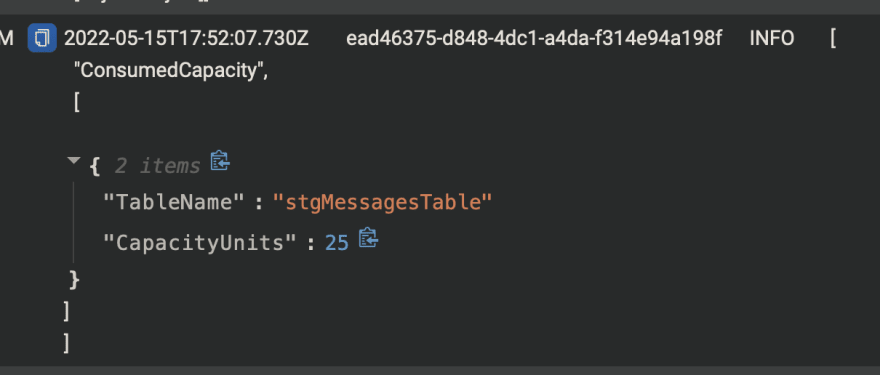
Visualizing latency involved 🚁
Here we take into account 25 successful puts, 25 get requests and a single batch deletes from separate handler functions. Though each request is of a different type, the common factor involved in the usage of dynamodb API calls across the network is where there are other overheads like latency.

PutItem Requests


GetItem Requests
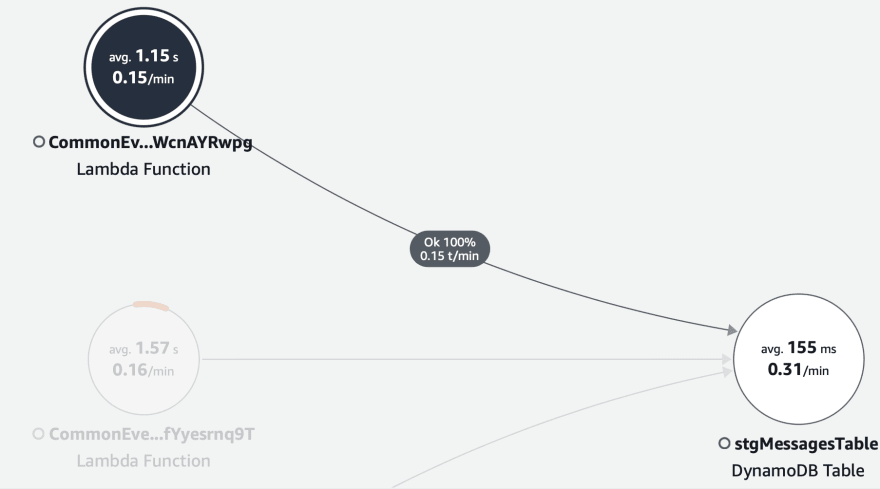

Batch DeleteItem Requests

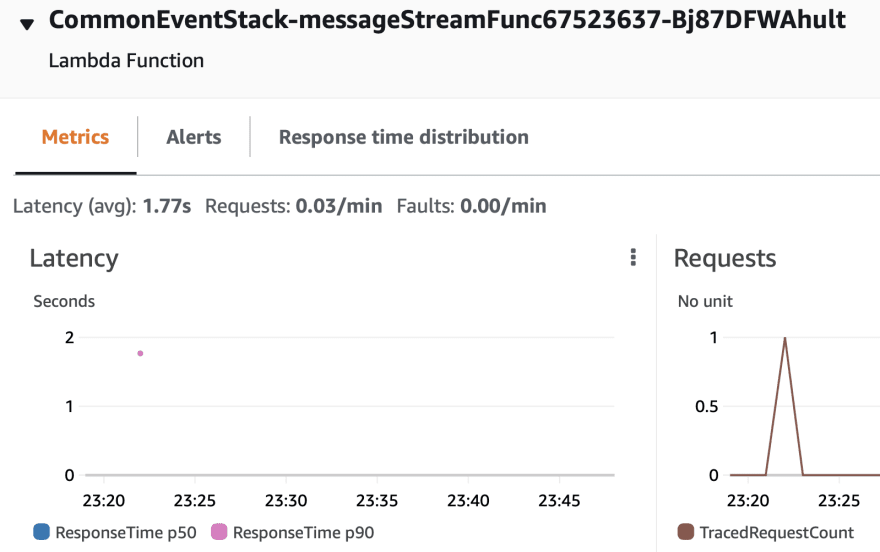
Hence batchWrite or batchGet is much more efficient by avoiding the latency, and hence we have tried batchWrite for deletion of unwanted data.
As for us, I learn that 25 is the max limit for the batch writes request collection.
Also, it is essential to checkUnprocessedItems in the result of batchWrite operation can be inspected and it is a best practice to check and retry the failed once, when we have some exceptions due to capacity or other failures due to message size.
In the next article, we will demonstrate how we will use a similar approach to delete Object from S3, which we have previously created.
We will be adding more connections to our stack and making it more usable in the upcoming articles by creating new constructs, so do consider following and subscribing to my newsletter.
⏭ We have our next article in serverless, do check out
https://dev.to/aravindvcyber/aws-cdk-101-dynamodb-streams-triggering-batch-deleteobjects-s3-2abn
🎉 Thanks for supporting! 🙏
Would be great if you like to ☕ Buy Me a Coffee, to help boost my efforts.


🔁 Original post at 🔗 Dev Post
🔁 Reposted at 🔗 dev to @aravindvcyber
🌺 AWS CDK 101 - 🚂 Dynamodb streams triggering batch deleteItem on another dynamodb table @hashnode
— Aravind V (@Aravind_V7) May 15, 2022
Checkout more at my pagehttps://t.co/CuYxnKr0Ig#TheHashnodeWriteathon#aws #awscdk #dynamodb #typescript #thwcloud-computing https://t.co/b3sOi0UmBu





Top comments (0)