
One of the main features of Choirless, is that is automatically synchronizes uploaded parts. That is kind of its raison d'etre. Each person sings along to a 'reference' part usually sung or played by the choir/band leader, and then others all sing or play along.
It has actually been quite a challenge getting this right, as trying to identify how far behind or ahead of the reference piece a part is turns out to be quite tricky.

Firstly, why would it be out of sync? Well when you sing along with Choirless is shows you the reference part so you can see and hear the person singing.
If you look at the waveforms, and zoom in, it can be quite obvious that they are out of sync.
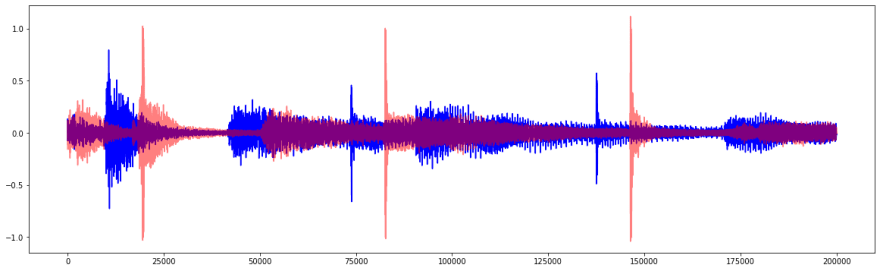
In the image above, it is quite obvious that they are out of sync and moving the red waveform forward a bit would match them up pretty nicely.
But this is hard to do in an algorithm! I've written about this before, and done a video on it. But still nothing matches up to real world testing!
Syncing to voices is not to hard, drums and a tuba? Much harder. We've had all sorts of people testing Choirless and all sorts of voices and instruments. The most recent test was the Soweto Gospel Choir. Their recording session didn't go quite as well as hoped as they were using an Android phone with the built in mic and speakers. The main problem was the sound from the reference track was bleeding into the subsequent recorded parts. As it happens, their reference part was keyboard and some drums. The drum sounds was very distinctive and easily noticeable on all the other parts. And even more noticeable was how out of sync it was :(
My original algorithm would scan over the reference and subsequent parts and try to extract certain features as 'landmarks' to use for the synchronisation. It would then take those landmarks and iteratively move them back and forth to get the best alignment.
It would measure the means squared error (MSE) between the two signals:
# function to measure two waveforms with one offset by a certian amount
def measure_error(x0, x1, offset):
max_len = min(len(x0), len(x1))
# calculate the mean squared error of the two signals
diff = x0[:max_len] - np.roll(x1[:max_len], offset)
err = np.sum(diff**2) / len(diff)
return err
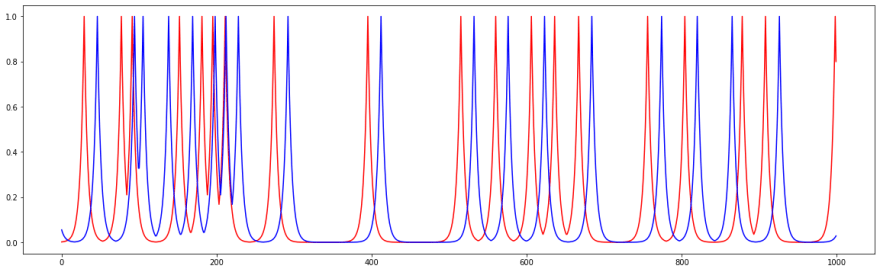
By iterating through different offsets, we could then plot the error against the offset. The 'best' match would be the minimum point on that graph:
Sometimes it would be obvious. But quite often the algorithm would be fooled and would find a false match. Sometimes it would thing there are multiple 'best' ways to align the audio that reduce the MSE between them. And often it was wrong.
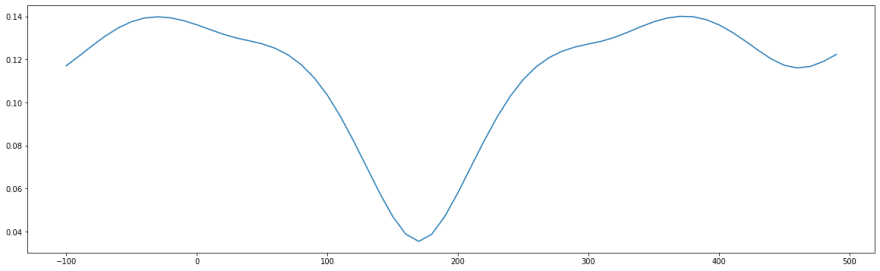
So this weekend, I set about making it more robust. I came up with the idea of instead of comparing the whole track as one, to compare just a small window, multiple times. So I use a sliding window of length 10 seconds, and stride of 2 seconds. I calculate the 'best' match in each of those windows. The end result is a chart that looks like this:
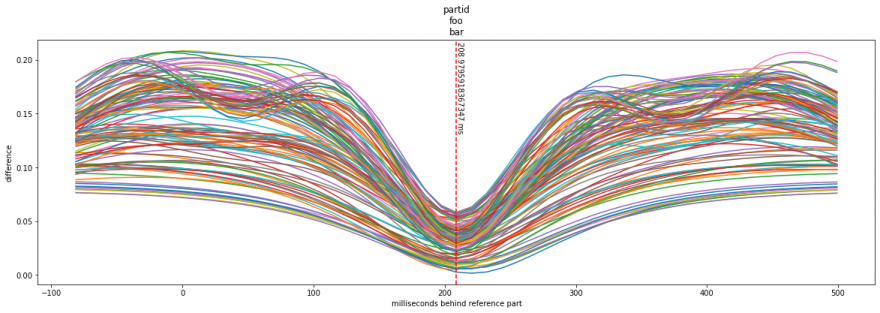
Pretty! But more to the point it shows the best sync for each 10s window. Plotting a histogram of the minimums we get this:
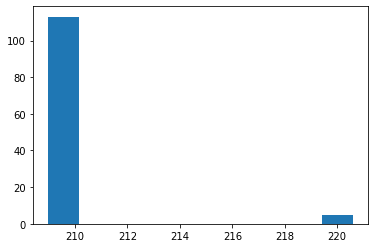
And you can see that 210ms is the most common 'best' offset to match the audio up.
Even after doing this, I still wasn't quite in sync. Looking at the waveforms all together in Audacity you could see they were still not lining up quite right. Better, but still not good enough.
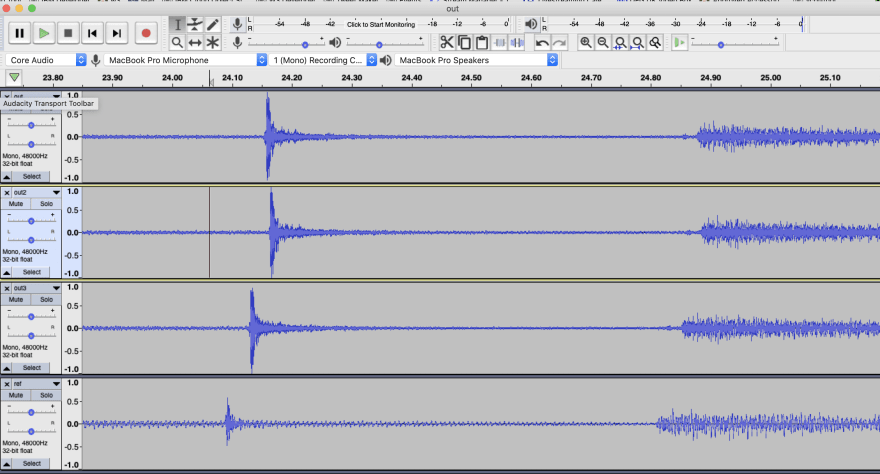
After a lot of digging about, I found the problem. I am using a great library called surfboard. And in particular a method in there called spectral_flux. The method takes a parameter hop_length_seconds which defaults to 0.01 ie 10 milliseconds. At the standard 44.1kHz sample rate of the audio we are using, that 10 milliseconds would be 441 samples. However in the code, it rounds that up to a power of 2, ie 512. So when I converted my 'best' offset in frames to samples I was assuming each frame was 441 samples, when in fact it was 512... thus throwing the sync out!
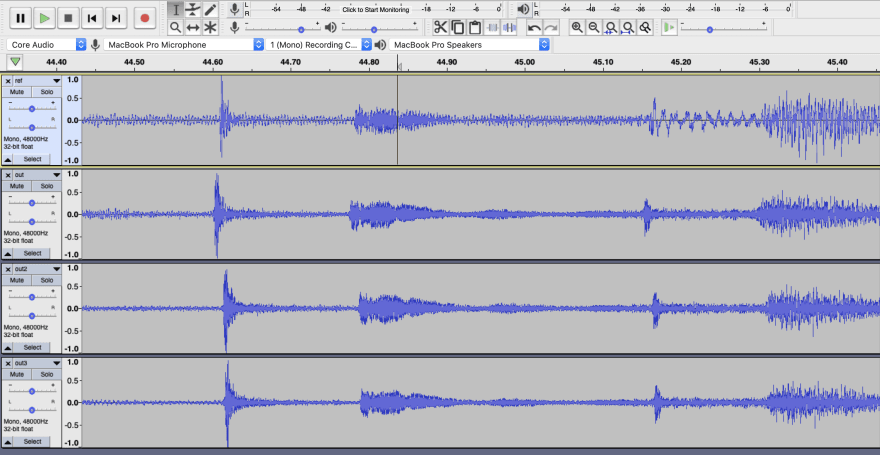
Now the parts are much more in sync with each other:
You can find out more about Choirless at:





Top comments (0)